Unveiling Hotel Reviews with EDA, NLP and Deep Learning Models

Subhradip Roy



Like this project
Posted Feb 1, 2024
To gain a nuanced understanding of customer sentiments expressed in hotel reviews. Followed by designing a DL model to predict ratings based on customer review.
Likes
0
Views
80




Project Description
In this project, we will be exploring the Hotel Reviews and the Rating based on Customer Hotel Experience. We will be also looking at
feature engineering and designing a deep learning model to predict ratings based on reviews. For which we will be using NLP tools for feature extractions and preparing the data for deep learning models.My client aimed to gain a
nuanced understanding of customer sentiments expressed in hotel reviews. The objective was to uncover valuable insights that could inform strategic decisions and enhance customer satisfaction.Data Preprocessing
I began by extracting and preprocessing data from a vast array of Hotel Reviews. Leveraging
VADER for sentiment analysis and Gensim's summarization.keywords module, I extracted top keywords to provide a foundation for intuitive data visualizations. This initial phase laid the groundwork for a comprehensive analysis of customer sentiments.To process the review text effectively, I utilized
NLTK, incorporating lemmatization to standardize words and ensure consistency. The Keras Tokenizer class was employed to vectorize the text corpus, optimizing the data for subsequent deep learning endeavors.Data Analysis and Visualization
Here are a few glimpses of the data visualizations generated during the exploratory data analysis :
● Plotting the Stacked Bar Graph - In the stacked bar plot, we can see the distribution of
sentiment and rating, people with 5-star ratings have the highest positive sentiment, whereas at lower ratings its mixed emotions showed by customers review, this can be related to sarcasm.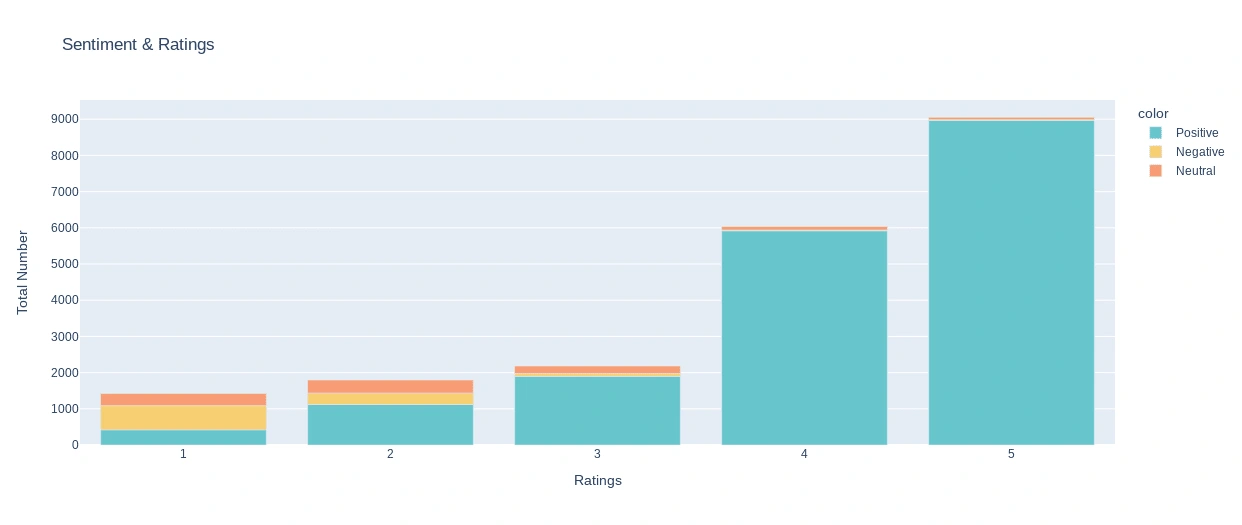
Stacked Bar Graph
● Violin plot - Violin plot gives us a better picture of the
relationship between Ratings and Sentiments. From 3 to 5 rating most of the review sentiments are positive.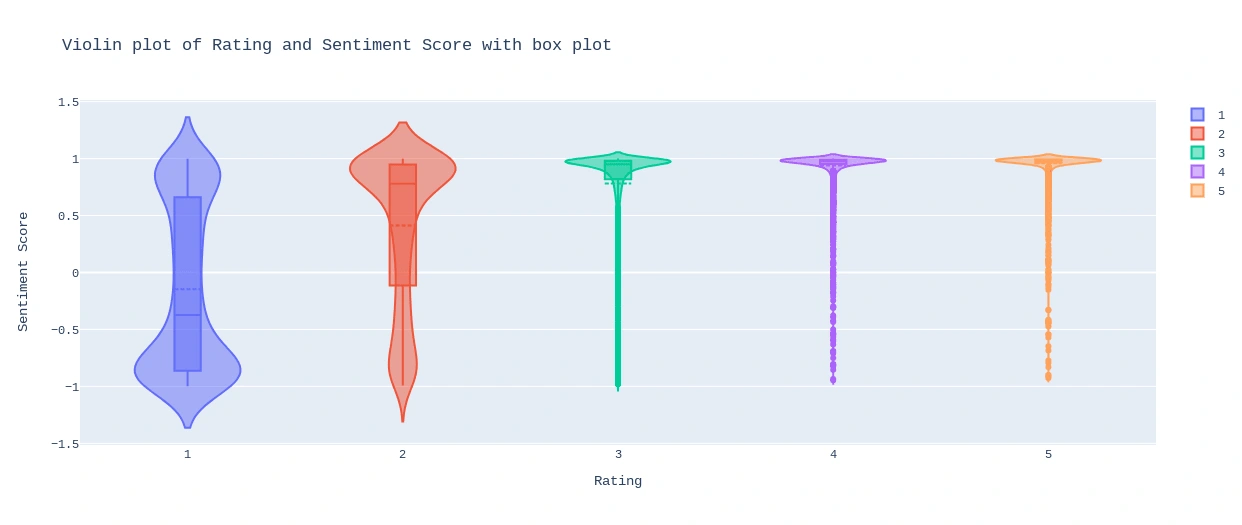
Violin Plot
● Word-cloud of Different Sentiments - The most
common word used in all three Sentiments was a hotel room. Which is quite obvious following which hotel managers can now be directed to focus on if they want a better rating from customers.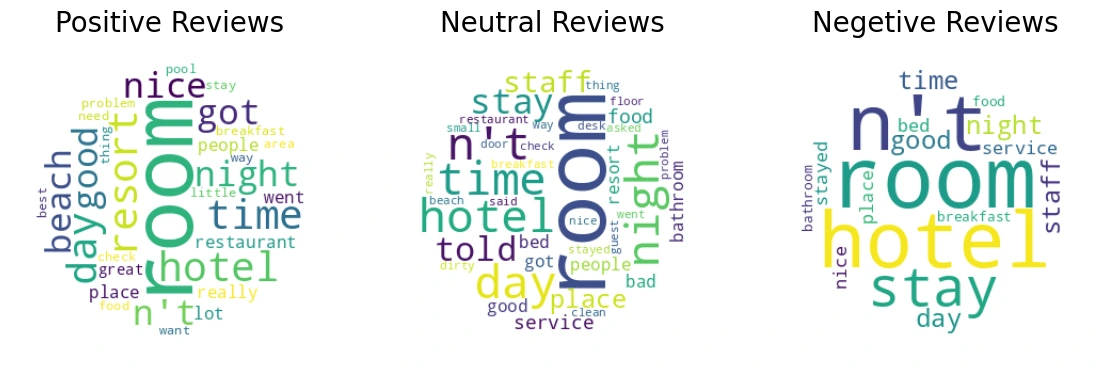
Word-Cloud
Review Text Processing using NLTK
Download
NLTK for natural language processing and to remove the common words and stop words to enhance model performance.Employed
lemmatization to convert words to their base form. Followed by text joining making all the comma separated lemmatized words back into a string. Then used PoerterStemmer to improve the performance metric.In addition, utilize the
Keras Tokenizer class to vectorize the text corpus. And finally employed the texts_to_sequences method helps in converting tokens of text corpus into a sequence of integers.Building the Deep Learning Model (LSTM)
The core of the project also involved the implementation of a
Long Short-Term Memory i.e. LSTM architecture for sentiment prediction in hotel reviews. This deep learning model was meticulously fine-tuned and validated, with a keen focus on visualizing its performance metrics . The resulting model, saved as "BiLSTM.h5",serves as a readily accessible resource for replication and testing, ensuring the sustainability and ease of use for future analyses. Here's a glimpse of the model architecture.Visualized Model Performance
Plotted
accuracy and sparse categorical cross-entropy for both training and validation sets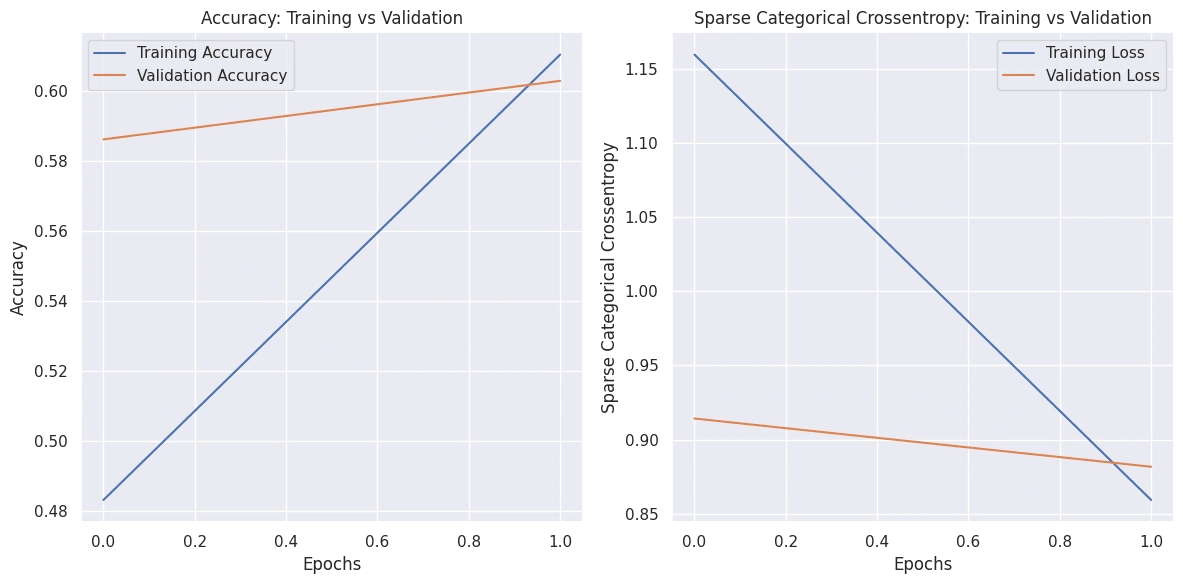
Visualized model
performance using a classification report
And at last, the
trained model has been saved as "BiLSTM.h5" for easy replication and testing.Summary of Project Success:
The project successfully unveiled comprehensive insights into hotel reviews, allowing the client to understand the nuances of customer sentiments. The combination of sentiment analysis, keyword extraction, and deep learning provided a holistic view of customer experiences. The
"BiLSTM.h5" model stands as a testament to the project's repeatability and sets the stage for ongoing analyses and enhancements.