Computer Vision Bag of Visual Words
Umer Nazeer
Computer Vision Bag of Visual Words
Abstract/Introduction
The bag of visual words (BoVW) is a popular method for image classification and recognition that extracts features from images and represents them as visual words. In this task we first extract the features from the images then we generate a visual vocabulary as known as Codebook Generation, lastly we train two classifiers, one using Support Vector Machines and the other one using Random Forest. We work on two datasets in this task, Objects Dataset and Flowers Dataset and perform these tasks for both these datasets.
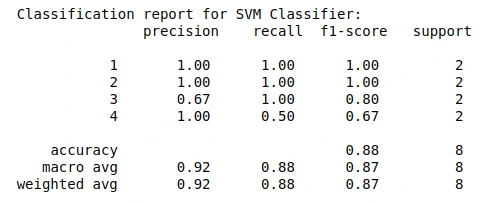
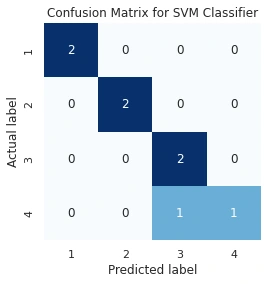
The first data set that was provided to us was the Objects dataset containing four different types of objects. This dataset was already split into training and test data and only needed to be loaded into the code in order to get started. The training set contained 14 images of all 4 categories namely accordion, dollar bill, motorbike and soccer ball. The test set contained 2 images per category (8 images in total).

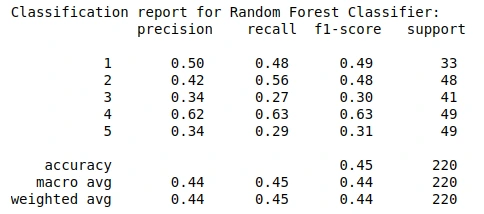
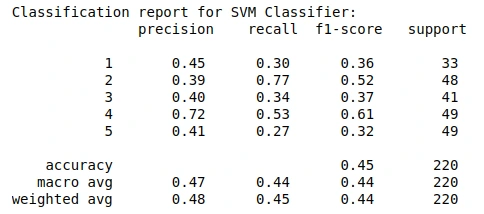
The second dataset was the Flowers dataset which contained 3670 images of five different types of flowers namely Daisy (633 images), Dandelion (898 images), Roses (641 images), Sunflowers (699 images), Tulips (799 images). In this dataset, a suitable quantity of images must be chosen for training and test sets. I kept 3450 out of 3670 images inside the training set whereas 220 images for the test set. The division of training and test set per class was as follows:
Daisy: 600 train images, 33 test images.
Dandelion: 850 train images, 48 test images.
Roses: 600 train images, 41 test images.
Sunflowers: 650 train images, 49 test images.
Tulips: 750 train images, 49 test images
Flowers Dataset

The Bag of Visual Words is applied on a dataset in the following sequence of steps.
Feature Extraction: Local features, such as shapes or textures, are extracted from the input images. In my assignment, this is achieved using Scale-Invariant Feature Transform (SIFT) which is an algorithm used for detecting and describing local features in images. It works by finding distinc- tive points in an image and representing them as a set of invariant descriptors.
Clustering: The local features are grouped into a number of clusters, and each cluster represents a visual word. I have made use of K-means clustering which is used for grouping data points into K number of clusters based on similarity. It works by iteratively assigning each data point to its closest cluster center and updating the cluster centers based on the mean of the data points assigned to them.
Building Histograms: A histogram is built for each image, by counting the occurrences of the visual words in the image.
Classification: A classifier is trained on the histograms of the training images, and used to predict the labels of new images. In this assignment, I have used two classifiers namely the Support Vector Machine (SVM) and Random Forest. The main libraries used for this assignment are OpenCV and SciKit Learn
Instructions to Run the Code
First copy the files Joblibs on your machine. Then Import the mentioned libraries and dependencies in the code. Then load the Joblibs mentioned in the codes to load the models.
Instructions to Run Train and Test Scripts
The path for train and test sets mentioned in the code needs to be altered to match with where the Datasets are located in your machine in order for this code to work.
Visual Results
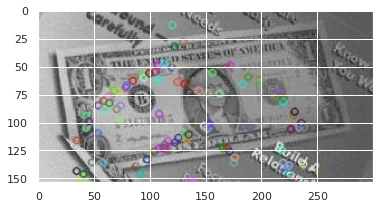
The images below show how SIFT feature detector outputs the features and key points in the images which then constitude towards the formation of the codebook or the visual vocabulary.


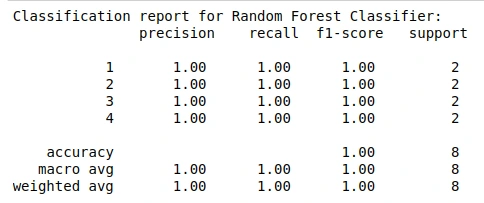
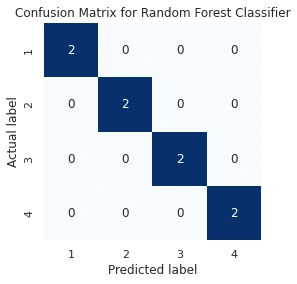
Quantitative Results
Objects Dataset
Flowers Dataset
Like this project
Posted Apr 18, 2024
Contribute to umer-un/CV-assign-1-bag-of-visual-words development by creating an account on GitHub.
Likes
0
Views
29