Automatic Speech Recognition
Sherry Jasal
Fine-tuning XLSR-Wav2Vec2 for Arabic ASR with 🤗 Transformers
Frameworks Used
Frameworks Used: torchaudio, librosa, and jiwer
Dataset: Common Voice Dataset For Multi-language
Transformer: XLSR-Wav2Vec2
These are essential for loading audio files and evaluating the fine-tuned model using the word error rate (WER) metric.
Architecture OF Transformer & ASR
Feature extractor and a tokenizer for ASR (Automatic Speech Recognition) models. Specifically, it introduces the Wav2Vec2CTCTokenizer and Wav2Vec2FeatureExtractor for the XLSR-Wav2Vec2 model.
Model Architecture: An insight into the pretrained Wav2Vec2 checkpoint, which maps the speech signal to a sequence of context representations. It explains the need to add a linear layer on top of the transformer block for fine-tuning, analogous to how a linear layer is added on top of BERT's embeddings for further classification.
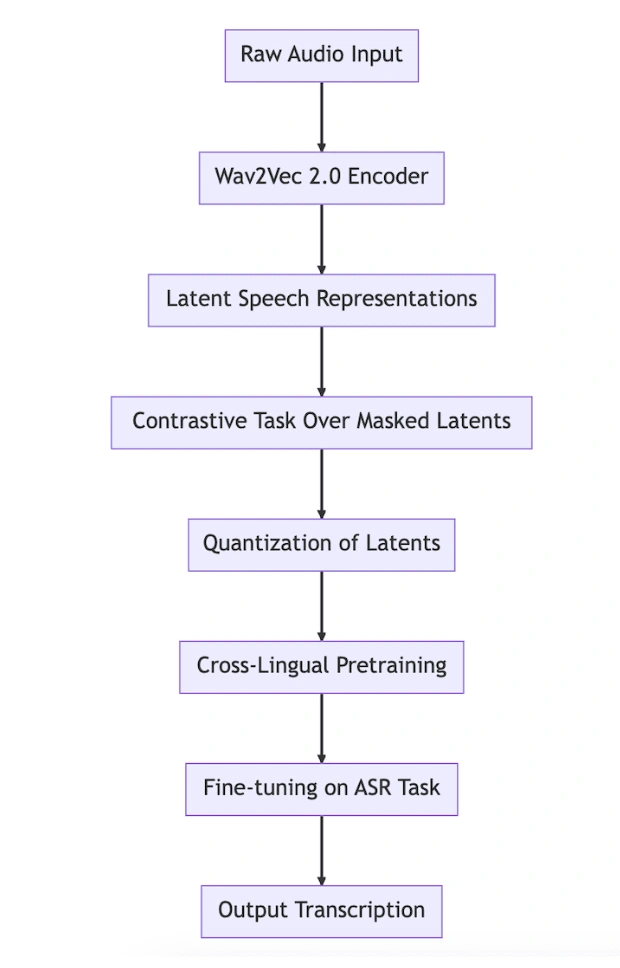
Flow Chart Of Automatic Speech Recognition(ASR)
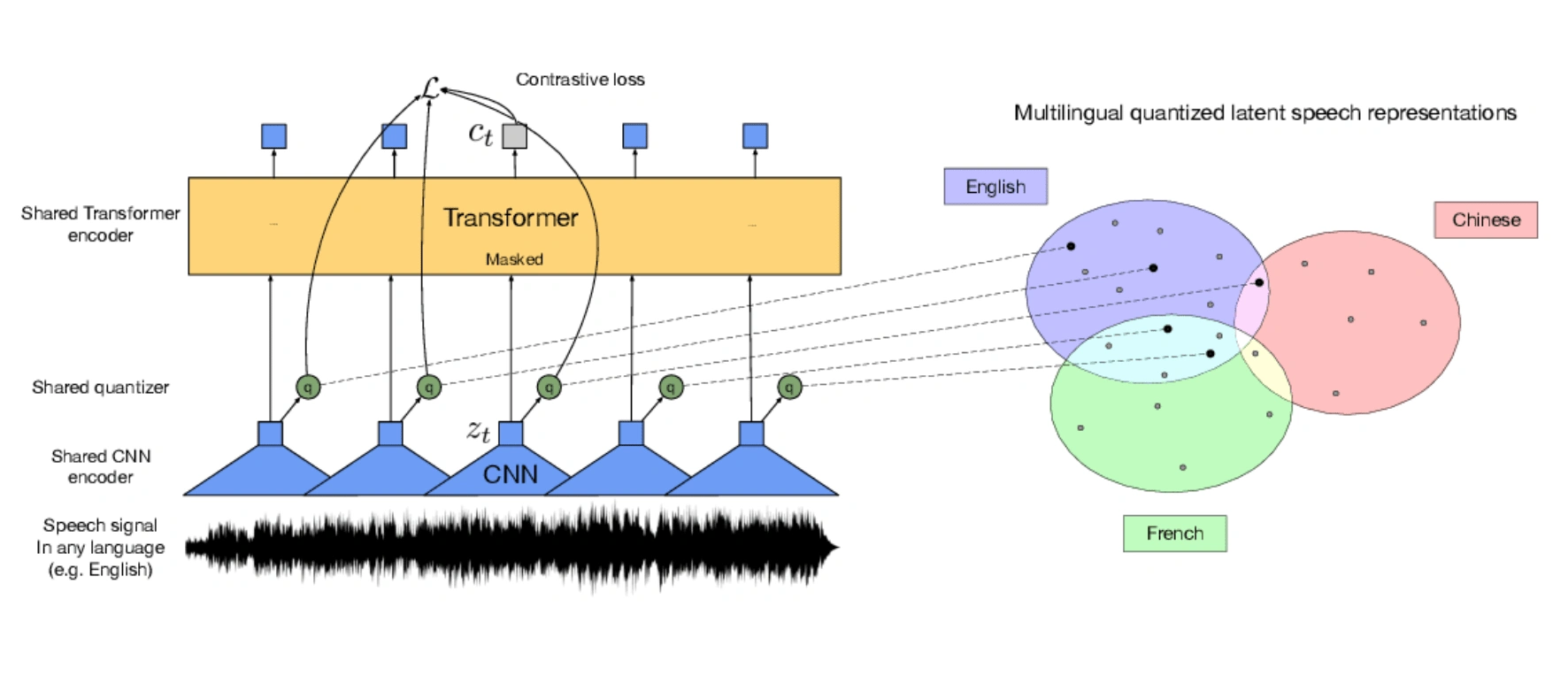
Transformer Architecture
How ASR Is FINETUNED ?
Vocabulary Creation: The output size of this layer corresponds to the number of tokens in the vocabulary. It is determined by the dataset used for fine-tuning and not by the pretraining task of XLSR-Wav2Vec2. The Common Voice dataset is chosen, and Arabic is selected as the language for fine-tuning.
Feature Extraction: First component of XLSR-Wav2Vec2 consists of a stack of CNN layers. These are used to extract acoustically meaningful features from the raw speech signal. This section also touches upon gradient checkpointing.
Training Parameters: group_by_length, learning_rate, and weight_decay.
Training
The training took several hours. The trained model yields satisfactory results on the Common Voice test data for Arabic and a satisfactory WER rate is achieved.
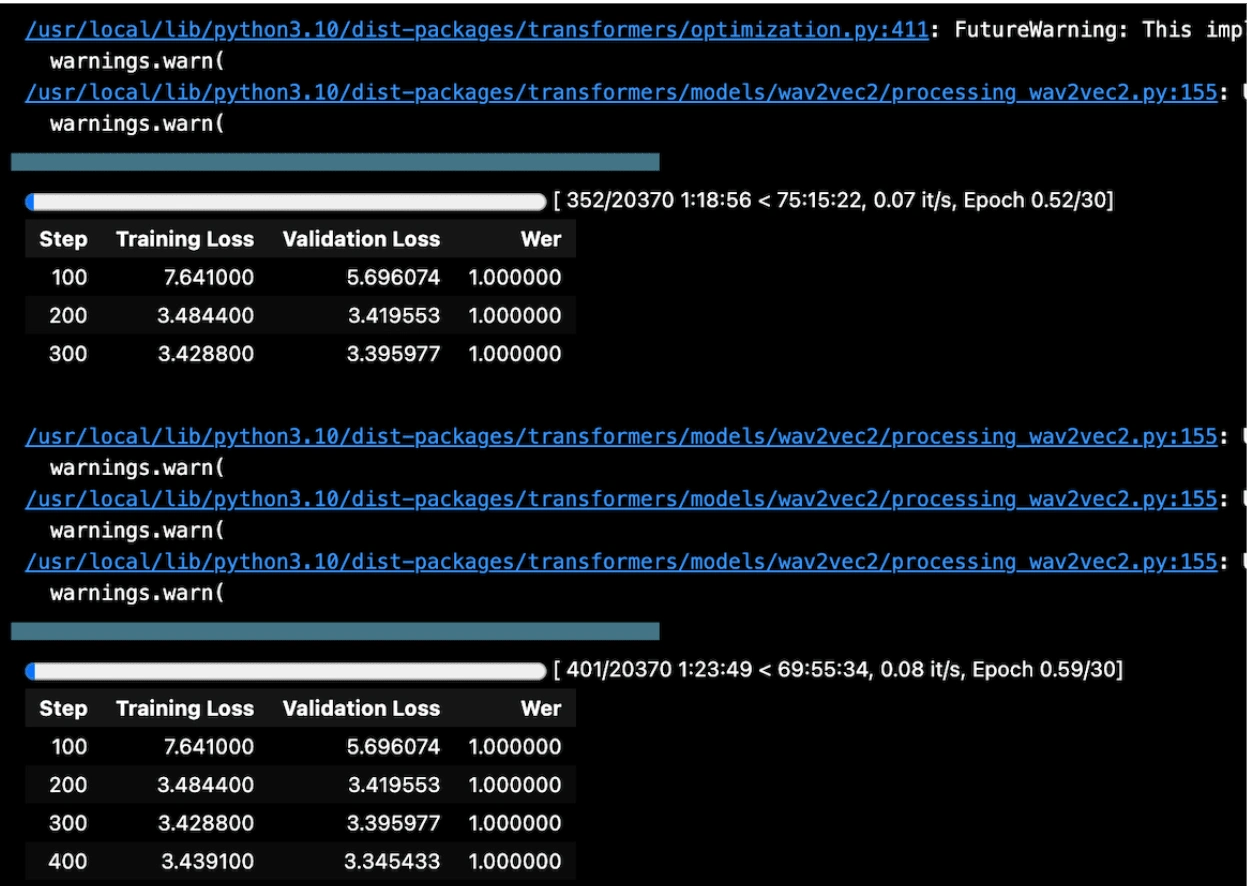
Fine Tuned Arabic Data with WER score
Like this project
Posted Apr 3, 2024
Fine-tuning XLSR-Wav2Vec2 for Arabic ASR with 🤗 Transformers
Likes
0
Views
1