Text Generation Using GPT-2
Sherry Jasal
To fine-tune the GPT-2 model using the complete works of Shakespeare.
Methodology:
Dataset Preparation: Collecting and preparing the complete works of Shakespeare for training.
Data Preprocessing: by creating a tokenizer, encoding the text, and batching the dataset.
Model Fine-Tuning: Load a pre-trained GPT-2 model using the transformers library. Set up the training loop, including defining the optimizer and loss function. Train the model on the Shakespeare Dataset.
Evaluation: Generate some text using the trained model. Establishing metrics for evaluating the success of the fine-tuning in emulating Shakespearean style.
Tools and Technologies:
GPT-2 Model
Python for scripting
Various NLP and machine learning libraries like TensorFlow, PyTorch, and Hugging Face Transformers.
Project Overview With Snippets:
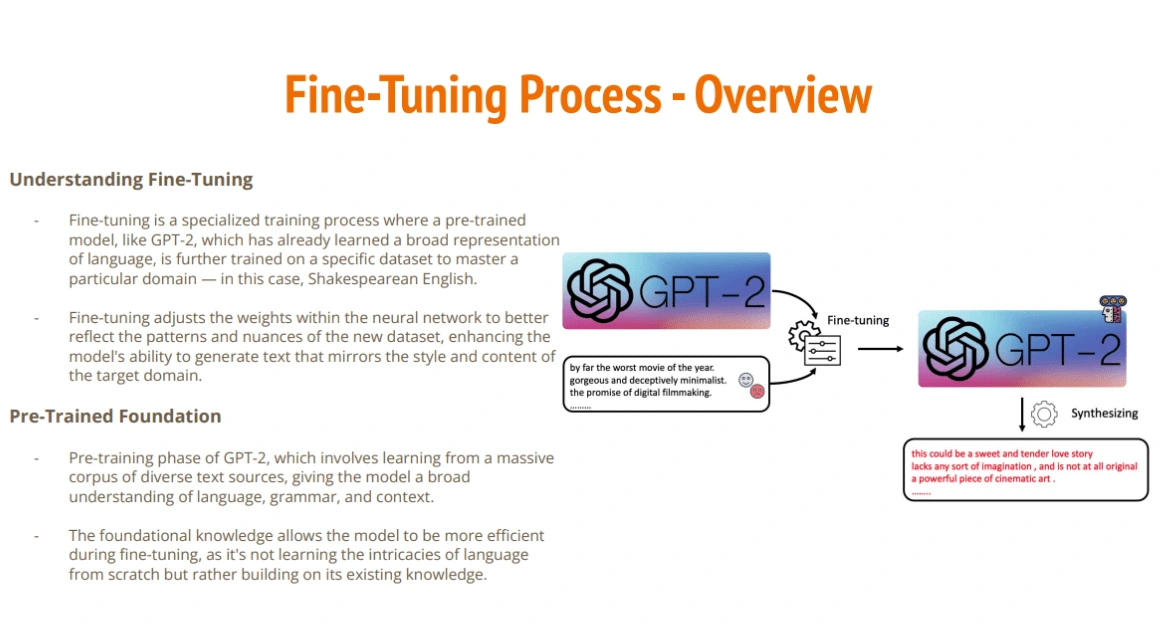
Fine Tuning Process

GPT-2 Transformer

Fine Tuning Results
Like this project
Posted Apr 3, 2024
Fine-tune the GPT-2 model using the complete works of Shakespeare.
Likes
0
Views
4