jhonatangopereira/Predict-Energy-Behavior-of-Prosumers
Jhonatan Pereira
Energy Prediction Model for Prosumers
Overview
The objective of this project is to create an energy forecasting model for prosumers in order to reduce energy imbalance costs. This work was developed based on a challenge proposed on Kaggle, which aims to address the issue of energy imbalance, a scenario in which the energy expected to be used does not correspond to the actual energy used or produced. Prosumers, who consume and generate energy, contribute significantly to this imbalance, causing logistical and financial problems for energy companies.
Description
The number of prosumers is increasing rapidly, and solving the problems of energy imbalance and its rising costs is vital. If not addressed, this can lead to higher operating costs, potential grid instability and inefficient use of energy resources. If this problem is effectively resolved, it will significantly reduce imbalance costs, improve grid reliability, and make the integration of prosumers into the energy system more efficient and sustainable. Furthermore, it can potentially encourage more consumers to become prosumers, knowing that their energy behavior can be managed appropriately, thus promoting the production and use of renewable energy.
Datasets
The data used in this project was provided by Kaggle and can be found here. The data is divided into 2 files:
train.csv: contains the training data, with more than 2,000,000 rows and 9 columns;test.csv: contains the test data, with 12,480 lines and 9 columns;The columns present in the datasets are:
county: the county in which the prosumer is located;is_business: whether the prosumer is commercial or not;product_type: identification code to map different types of energy contracts;target: energy consumption or production for that line;is_consumption: whether the line is energy consumption or production;datetime: date and time of measurement;data_block_id: data block identifier;prediction_unit_id: prediction unit identifier;Methodology
The project was developed using the Python language and the Scikit-Learn library. The development process was divided into 3 stages:
Exploratory Data Analysis (EDA);
Data Pre-processing;
Modeling;
Exploratory Data Analysis
After importing the necessary libraries and datasets, the EDA, or Exploratory Data Analysis, stage begins. Exploratory data analysis was carried out with the aim of better understanding the data and extracting relevant information for the development of the model. For this, data visualization techniques were used, such as histograms, heat maps, bar graphs and scatter plots.
Furthermore, a correlation analysis was carried out between the variables, in order to identify which variables have the highest correlation with the target variable, and which variables have the highest correlation with each other. From this analysis, it was possible to identify that the variables product_type and is_business have a high correlation with each other, and that the variable is_consumption has a high correlation with the target variable target, which represents the consumption or production of energy for that line.
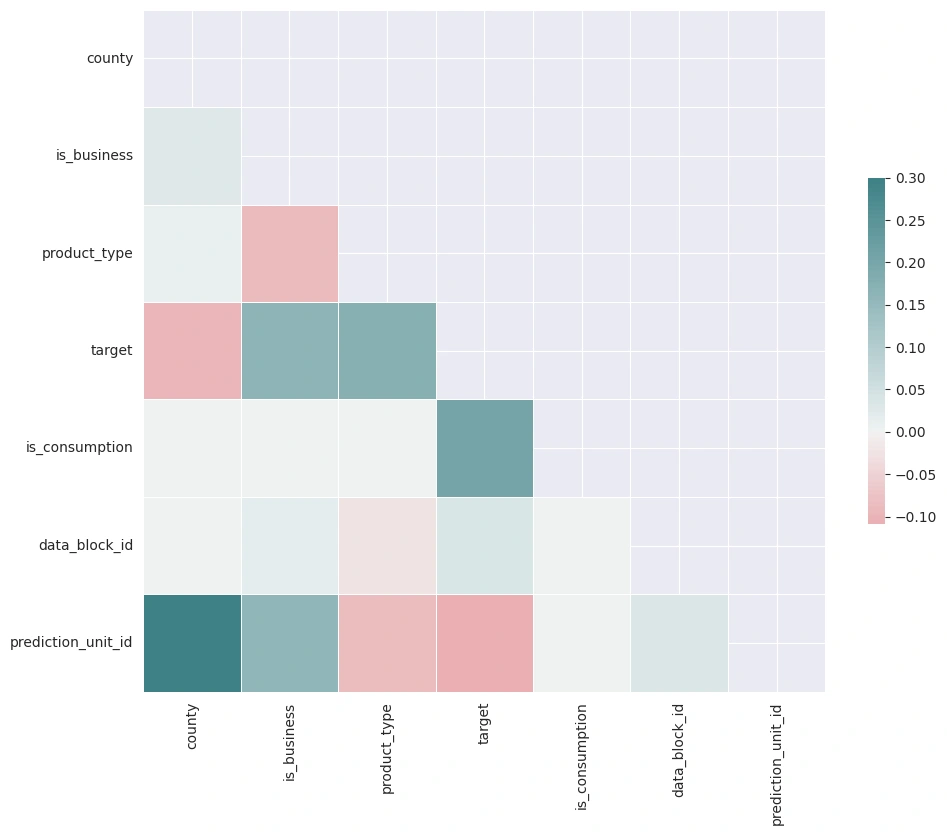
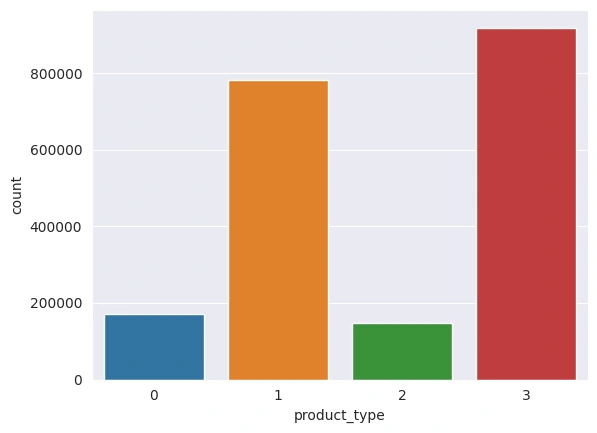
Using other data visualization techniques, it was possible to identify that the is_consumption and is_business variables have a balance between the classes, and that the product_type variable has an imbalance between the classes, with classes 1 and 3 having a number of records much larger than other classes.
Data Pre-processing
After the EDA stage, the data pre-processing stage began. At this stage, the following tasks were carried out:
Removing unnecessary columns;
Removing records with null values;
Transformation of categorical variables into numerical ones;
Data normalization;
Grouping data by date and time;
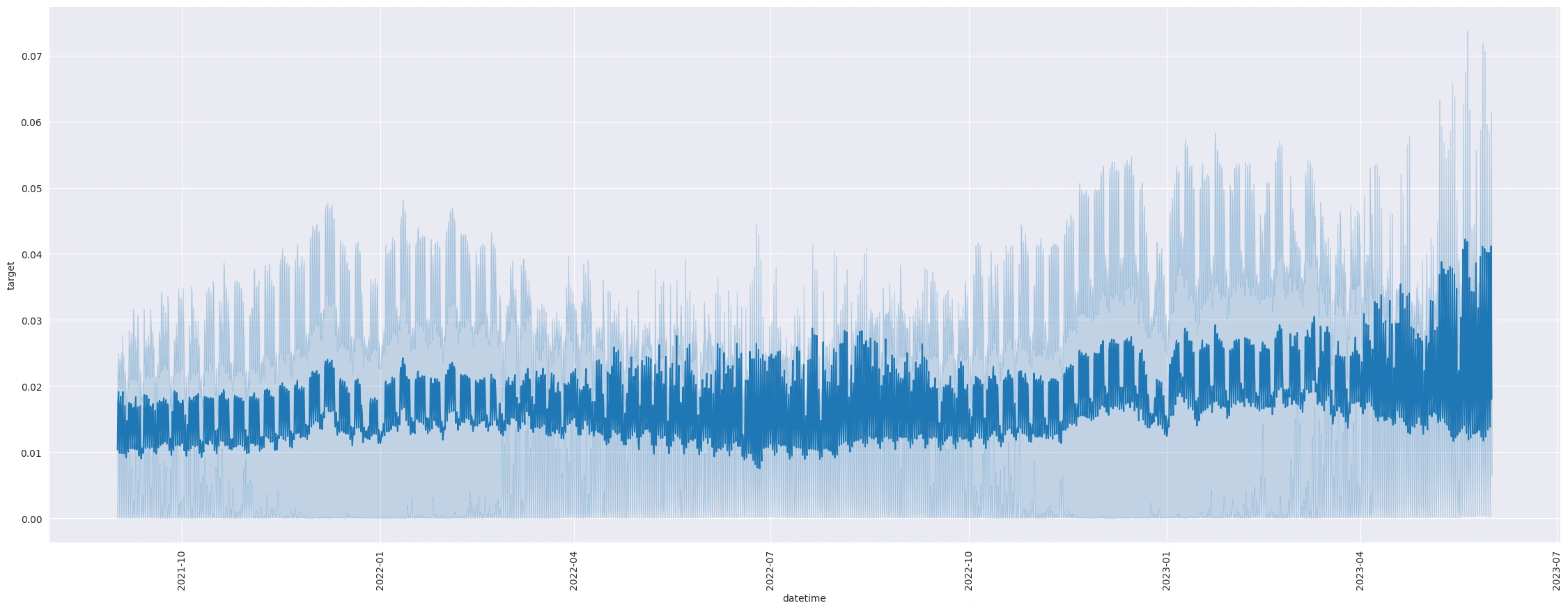
Decomposition of data into trend, seasonality and residual;
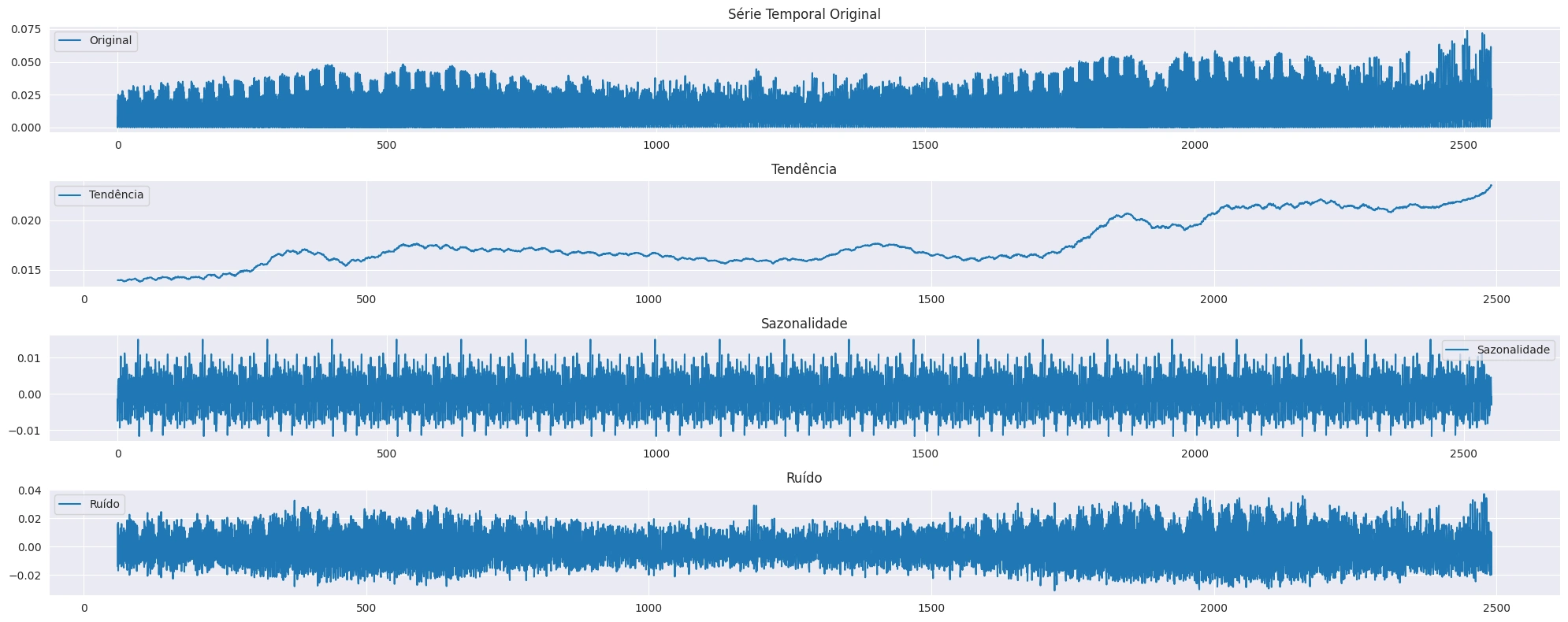
Separation of data in training and testing;
Modeling
After the data pre-processing stage, the modeling stage began. At this stage, the following regression models were used:
Decision Tree Regressor;
K-Nearest Neighbors Regressor;
Multi-layer Perceptron Regressor;
Support Vector Regressor;
Random Forest Regressor;
Gradient Boosting Regressor;
For each model, it was necessary to apply the make_reduction method from the Sktime library, with the aim of making the model capable of making predictions in time series. Furthermore, it was necessary to pass the parameter window_length=40, to inform the model that the forecast window is 40 records, representing the forecast month.
Results
After the modeling stage, it was possible to identify that the model that achieved the best performance was DecisionTreeRegressor, with an MSE of 141089.1, RMSE of 375.52 and MAE of 300.02.
Conclusion
The DecisionTreeRegressor model achieved the best performance, with an MSE of 141089.1, RMSE of 375.52 and MAE of 300.02. Despite the application of several models, there is still room for improvement, such as the use of feature engineering techniques to create new variables that can improve the model's performance. Furthermore, it is possible to use feature selection techniques to identify which variables are most important for the model, and thus reduce the dimensionality of the data.
Referências
Like this project
Posted Jul 7, 2024
The objective is to predict a customer's energy consumption and production, based on historical energy consumption and production data.
Likes
0
Views
9