AIrtisan - Hallucination-free LLM-based chatbots
Aidan Tilgner

What's the problem?
With the sudden burst in popularity and accessibility of large language models such as ChatGPT, it was only a matter of time before derived products began to appear. One such type of product early on was the "ChatGPT for your website" value proposition, which promised more organic and flexible chatbots for customers to interact with. However, there was and is an Achilles' heal to such products: hallucination.
Unfortunately as it stands language models are prone to making things up. The way that an LLM works is for all intents and purposes, non-deterministic, that is, unpredictable. This is actually the main value of such models, since they're not constrained to preset text responses, but rather can be a bit creative. However, this becomes a problem when you have a user-facing solution tasked with providing accurate and helpful conversation. A chatbot which hallucinates information is bound to introduce friction and confusion a significant percentage of the time.
Ok cool, so how do we fix it?
The challenge becomes pulling the lever of increased determinism, without the need to compromise flexibility. That's where AIrtisan comes in, a chatbot creation platform which leverages the traditional natural language processing power's of nlp.js, alongside OpenAI's generative transformers. The idea is to combine more symbolic artificial intelligence intent-classification with the neural network based language models.
Essentially, text-classification is the process of classifying the intent of some language against a predefined set of intents, which you can then assign to certain responses. Language models, on the other hand, take a prompt and recursively predict the next word based on their training data. This means that text-classification can essentially guarantee that certain questions are met with specific responses, whereas transformer-based language models can make more organic and "intelligent" predictions. In AIrtisan, text-classification is used by default, but when more flexibility is needed, GPT-4 completes the response.
How does it work?
The frontend comprised of React, Mantine UI, and Typescript, bundled with Esbuild into a performant single page application. On the backend, I used Typescript again, with Express.js and TypeORM making up the REST API. A manager process oversees all of the chatbots, which have their own configuration files, and sees to their synchronized training.
The chatbots are setup with text-classification as the primary response generator, where responses are then enhanced by a language model. If the text-classification doesn't have a high confidence, then the system will instruct a language model to generate a response for the user. This functionality is customized in the chatbot creation studio, which allows you to train chatbots through conversation:
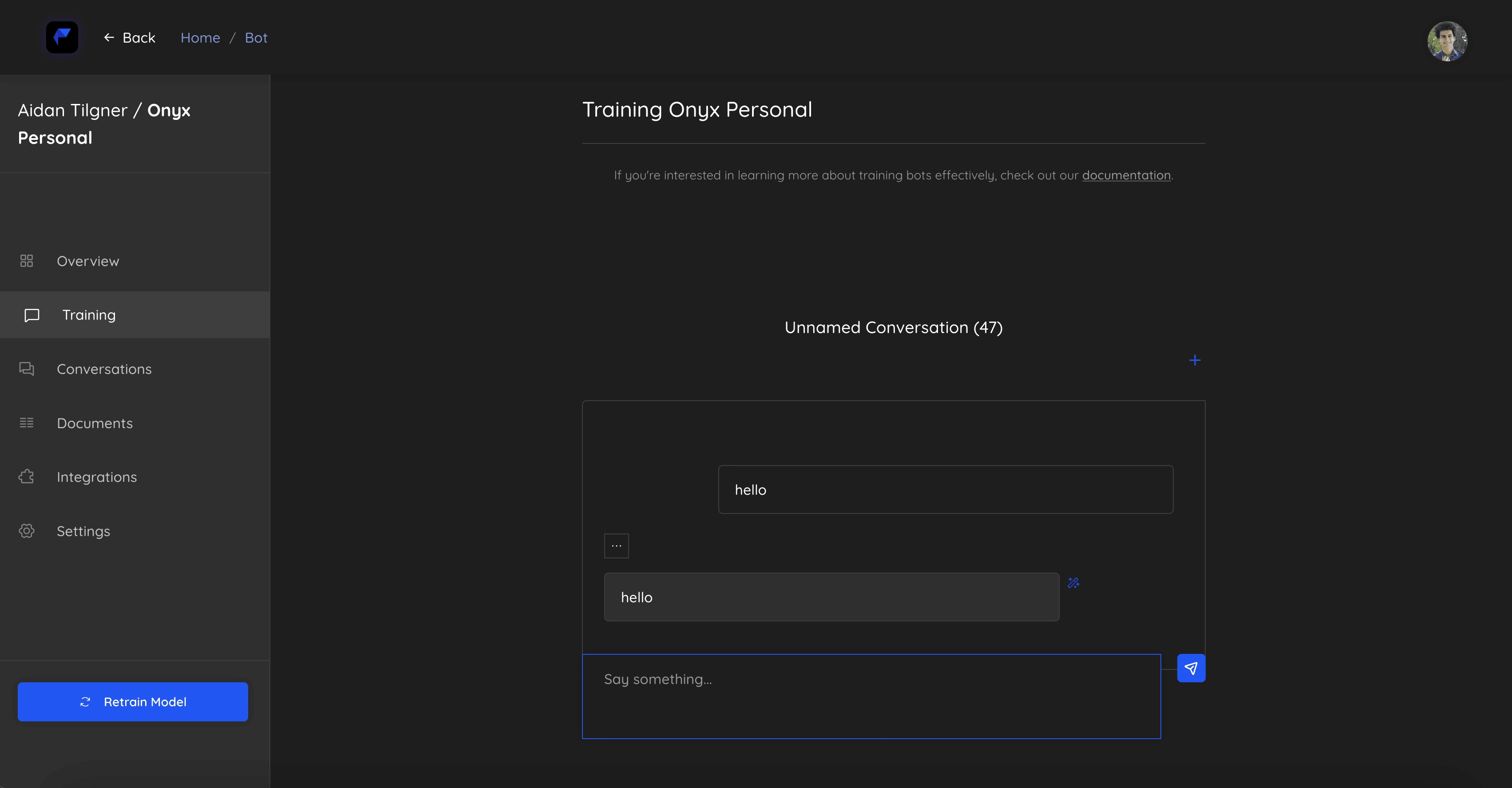
My admittedly very developer-y training interface
If you're interested in a more in-depth tour of the application, I'd recommend this tutorial on how to build a chatbot with AIrtisan:
Having essentially completed the project, I have since moved AIrtisan to a more dormant form. The source code is available on my GitHub profile:
Like this project
Posted May 7, 2024
Harnessing the power of ChatGPT for business chatbots, AIrtisan brings hallucination free conversational AI with low level control.


