Machine Learning: A Comprehensive Guide for Beginners
Paul Abulu Jr
Hello and welcome! Today, we're going to discuss the world of machine learning. Think of this as your friendly guide, where we'll explore how this fascinating technology has grown from its early days in the 1950s to becoming a huge part of modern artificial intelligence. I've put together some simple explanations of key terms like algorithms, features, agents, and hyperparameters to make things easier as we go along.
Our journey will take us through the exciting evolution of machine learning, showing how it's become useful in industries like healthcare and cybersecurity. We'll also break down the main types of machine learning, supervised, unsupervised, and reinforcement learning, in a way that's easy to understand. Plus, I'll walk you through how a machine learning project comes to life, from collecting data to putting the final model to work.
So, whether you're just getting started or looking to brush up on your knowledge, this article is designed to clear up the complication of machine learning and show you how cool and impactful this tech really is. This is just a comprehensive overview.
You do not need to know math or programming to understand this article!
Cool...
Now breathe.
Let's get started!

Key Terms
Algorithms: It's a set of step-by-step instructions that tells the computer how to solve a problem or perform a task. In machine learning, algorithms are the methods or techniques used to interpret data, learn from it, and make decisions or predictions. Just like how different recipes give you different dishes, different algorithms can be used to tackle various types of problems in computing.
Features : Individual pieces of data that you use to train your machine learning models. For example, if you're trying to predict house prices, the features might include the size of the house, its age, and its location. These features are what the model uses to understand patterns and make predictions. Essentially, they're the important data points that help your models make sense of what they're learning.
Agents : Think of an agent as a learner or decision-maker. It's like a character in a video game that learns to make better moves through trial and error. The agent interacts with its environment, makes decisions, and learns from the outcomes of its actions. Over time, the agent learns to make better decisions that earn it rewards, much like a player learns to navigate a game more effectively.
Hyperparameter: Hyperparameters can be thought of as the settings or dials on a machine that you can adjust to fine-tune its performance. In machine learning, hyperparameters are the configuration settings used to structure the learning process. They're not learned from the data but are set prior to the training process. Adjusting these hyperparameters can significantly affect the behavior and performance of your machine learning models You can then adjust these parameters throughout your experiments.
Now that you have an understanding of these terms, lets start our exploration.
How Machine Learning Has Changed Over Time
Arthur Samuel was the first person to use the term and idea of machine learning in 1959. At first, it was thought of as computers' ability to learn and change on their own, without being directly designed to do so. This new idea was the first step toward computers that are smarter. As time has gone on, this basic idea has grown, changing into a deeper understanding that is the basis of all current AI applications.

On February 24, 1956, Arthur Samuel’s Checkers program, which was developed for play on the IBM 701, was demonstrated to the public on television
Not only has technology improved, but machine learning has also changed in many ways. In a way, it changes how we think about and use data and programs. It has become a major force in many areas and has changed how we do things and figure out hard problems. Machine learning has a big effect on many areas, from healthcare to banking, and from hacking to customer service.
Machine learning goes beyond traditional computing and gives you a more flexible way to solve problems and look at data.
Core Types of Machine Learning
When you first start looking into machine learning, there are 3 main types of machine learning algorithms you should become familiar with. They are: Supervised learning , Unsupervised learning, and reinforcement learning.
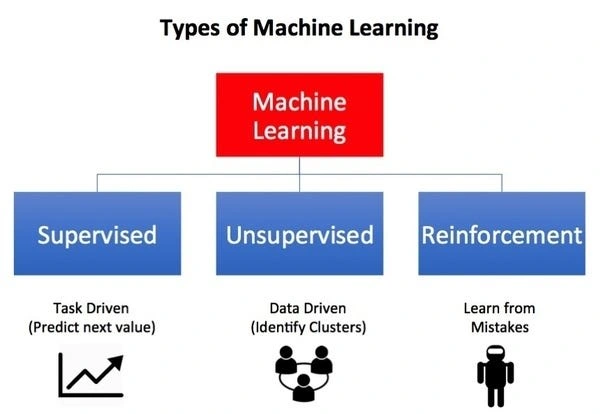
Types of Machine Learning
One of the main types of machine learning is supervised learning, which works a lot like guided learning process. In this approach, machine learning models are trained using labeled data sets, where each data point is tagged with the correct answer. This method resembles a teacher giving a student practice problems and the answers to them. This helps the student learn and guess what will happen with new problems that are similar.
If you know what will happen and want to train the model to find patterns that lead to that result, this method works exceptionally well. Despite its effectiveness, supervised learning can be limited by the availability of large, accurately labeled data sets, which can be time-consuming and costly to prepare.
Unsupervised learning, on the other hand, offers a more exploratory approach. In this case, data is given to to the machine learning model without clear directions on what to do with it. The model learns on its own to find patterns and relationships in the data. This way of learning is like looking through a big dataset without a clear goal in mind. This lets the program find hidden patterns and insights. It's especially helpful when you don't know ahead of time how the data in the set is related to each other.
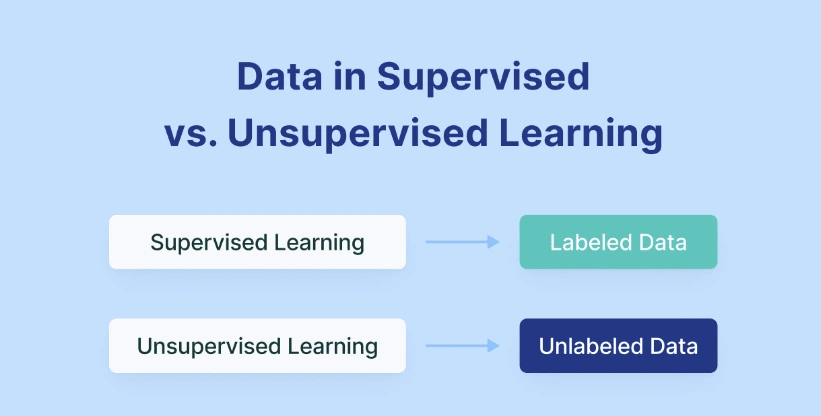
Unsupervised learning can be used for many things, from marketing to finding strange behavior in networks to customer analysis. But, it can be hard to figure out what the results mean because the data isn't labeled, which can make the results less clear.
Machine learning gets more complex with reinforcement learning. This method is based on trial and error, with the model learning from interacting with its surroundings. In this setup, the algorithm decides what to do. It gets input in the form of rewards or punishments, and then changes its strategy to match. This method resembles showing a robot how to get through a complicated maze and every choice has an effect.
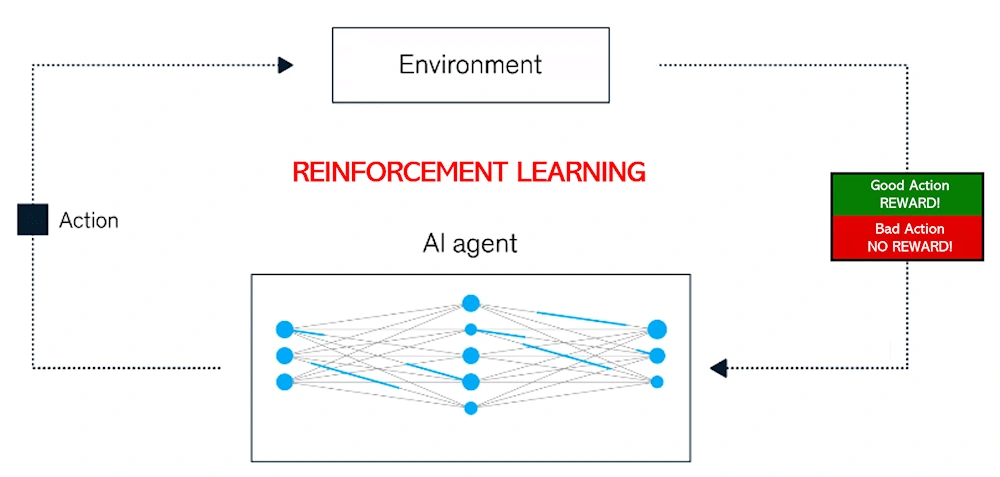
The goal is to find the fastest way through the maze. In situations where making decisions in real time is important, such as self-driving cars for example, reinforcement learning works really well. It does, however, need a clear reward system and a good environment for the model to work in, which at times can be hard to set up.
How Machine Learning Is Used in the Real World
The impacts of machine learning on the real world are intriguing and important innovations . In fields like healthcare, machine learning algorithms assist in diagnosing diseases and predicting patient outcomes. This improves the level of care.
The technology sector heavily relies on machine learning for developing smarter applications, enhancing user experience, and improving software capabilities. These examples only scratch the surface of the potential that machine learning holds.
They are also used to find scams and evaluate risk in the financial world and markets, making things safer and predictable. Since I have a love for cybersecurity I definitely want to talk about the impact of machine learning in this industry.
Because these machine learning models can learn from data, they are very useful for finding online risks and trends. They can look at patterns within network data to find odd phenomena, guess where vulnerabilities might be, and suggest ways to stop breaches before they happen.

Adding machine learning to cybersecurity has been a big step forward in how well we can protect digital assets and practice good computer habits. There is still a lot more to innovate, but slow and steady wins the race.
Aside from that, machine learning is playing a bigger part in daily life. Machine learning is slowly making our everyday lives better. It's used in everything from voice helpers on our phones to recommendation systems on streaming services. It makes hard jobs easier, gives people more unique experiences, and creates new ways for people to come up with new ideas. I'm still dedicated to studying and using machine learning to its best potential so that more people can benefit from it.
Application of machine learning in our daily lives
From Data to Setup and Use
A machine learning project starts with gathering data, which is the basis of all machine learning projects. In this step, you will collect data that will be used to train the model. The nature, quality, and quantity of the data collected can significantly impact the model's performance. It's important to ensure that the data is representative of the problem being solved, as this forms the basis for the learning that will follow.
After the data is gathered, it goes through preparation (preprocessing). This step is very important for getting the data ready for training. Cleaning the data to get rid of or fix any mistakes, dealing with missing numbers, and changing factors as needed are all parts of it.
Preprocessing also involves normalizing or scaling the data, ensuring that all features contribute equally to the model's outcomes. This step is very important to the machine learning process because it sets the model up to learn well.
Data Pipeline
The next step is exploratory data analysis (EDA), where the data is explored and visualized to uncover patterns, anomalies, or relationships. EDA is important for getting information that can help with choosing models, technical features, and learning algorithms to use. It includes using statistical tools and graphs to look at the data from different perspectives to figure out the basic framework and patterns within the data. What we now know helps us choose the best model and traits for the job, which is an important part of creating machine learning.
The next step is feature engineering, which changes the raw data into a shape that is better machine learning models to understand. This involves creating new features from the existing data, selecting the most relevant features, and possibly reducing the dimensionality of the data. Feature engineering is a mix of art and science because the goal is to make the model better at learning from data.
Choosing the right model (algorithm) is the next step. This decision is based on the nature of the problem being solved, the type of data available, and the desired outcome. The choice of model can significantly impact the results. This step often involves experimenting with different models to find the one that best fits the data and the problem.

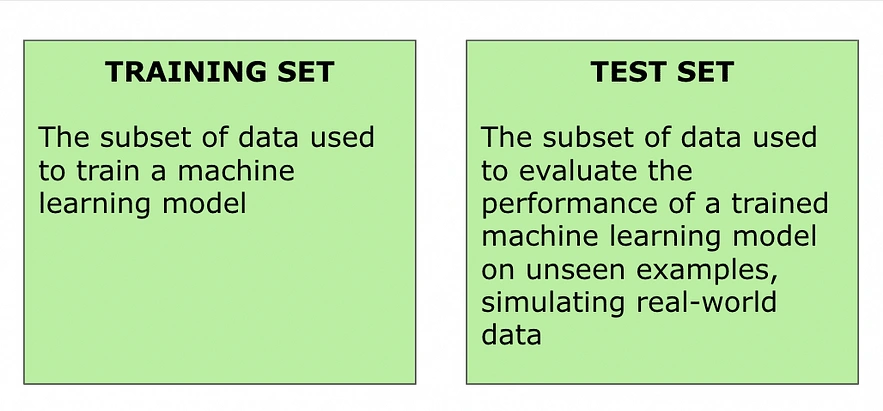
Training the model is where the algorithm learns from the data. The model is shown the input data, and it adjusts its internal parameters to learn the patterns present in the data. This step is iterative, with the model gradually improving its performance as it processes more data. Training a model requires balancing the need for the model to learn effectively without overfitting to the training data.
After training, the model is evaluated. This is done by testing the model on a different set of data, which is called the test dataset. There are different ways to measure how well a solution works, but some of the most popular ones are accuracy, precision, memory, F1 score, and the area under the ROC curve. This step is very important for figuring out how well the model will work with new data that it hasn't seen before.
Hyperparameter tuning is the process of fine-tuning the model's settings to get the best results. To do this, you have to try out different sets of features together to see which ones work best for the model. Tuning hyperparameters has a big effect on how the model works, so it's a key component of the machine learning process.
The final step is deploying the model. This involves integrating the model into a production environment, where it can start making predictions or decisions based on new data. After the model is deployed, it needs to be constantly monitored and tweaked. Over time, models can degrade due to changes in the underlying data, a phenomenon known as model drift. Regular monitoring and updates are necessary to ensure the model remains relevant and effective.
The process of machine learning is ongoing and changes over time. To get the best model for the job, it's common to go back and forth between steps, making changes and improving things.
To wrap up, it's clear that this field is a transformative force, reshaping not just technology but our entire world. From its early conceptualization by Arthur Samuel to today’s advanced algorithms, machine learning has evolved from a novel idea to a useful tool in problem-solving across various sectors.
Whether it's enhancing healthcare, revolutionizing finance, or evolving cybersecurity, machine learning is simplifying tasks and opening new innovation avenues. Let's continue to explore and innovate!
Like this project
Posted Jan 4, 2024
Join me on a friendly journey through machine learning's growth, from 1950s concepts to today's AI marvels, made simple for everyone to grasp.
Likes
0
Views
49




