RAG Failure Modes: 10 Breaks and Their Fixes
Sergiu Nicoara
RAG Failure Modes
I deliberately broke RAG to understand exactly how to fix it. Most tutorials only show the happy path, the few cases where every query returns a perfect answer. To master RAG, you have to look at the edge cases and the silent failures that happen when data gets complex.
I stress-tested RAG architectures to identify the 10 most common failure modes, then built a playbook of runnable scripts that demonstrate each failure in action alongside the specific engineering fix.
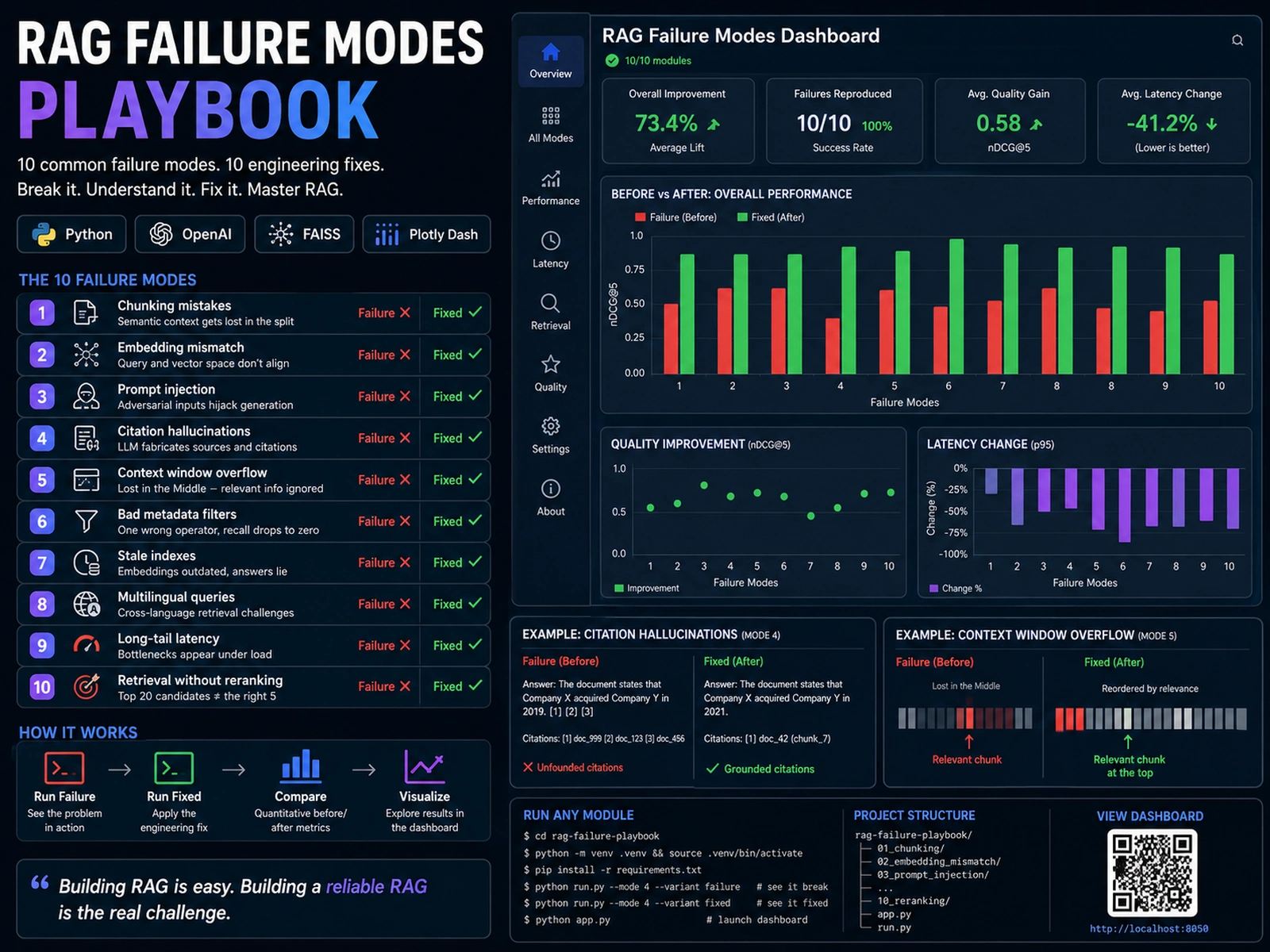
The 10 failure modes
Chunking mistakes. Semantic context gets lost in the split. The fix restructures chunk boundaries around meaning, not character counts.
Embedding mismatch. Query and vector space don't speak the same language. Alignment between query formulation and embedding model training distribution matters.
Prompt injection. Hardening RAG against adversarial inputs that hijack the generation step.
Citation hallucinations. Stopping the LLM from fabricating sources. Grounding citations to actual retrieved chunk IDs.
Context window overflow. The "Lost in the Middle" phenomenon: relevant chunks buried in a long context get ignored by the model.
Bad metadata filters. Filter logic that returns empty results for relevant data. One wrong operator and recall drops to zero.
Stale indexes. The temporal gap in vector databases. Documents updated, embeddings not. The system confidently answers from outdated information.
Multilingual queries. Cross-language retrieval challenges where the query language and document language don't match.
Long-tail latency. Performance bottlenecks that only surface under load or with specific query patterns.
Retrieval without reranking. Using cross-encoders for high-precision results. The difference between "top 20 candidates" and "the right 5."
How it works
Each module includes a "Failure" script that demonstrates the problem and a "Fixed" version showing the optimized implementation. An interactive Plotly dashboard visualizes the results across all 10 modes, so you can see the before/after impact quantitatively.
Building RAG is easy. Building a reliable RAG is the real challenge.
Stack: Python, OpenAI, FAISS, Plotly Dash.
Like this project
Posted Jun 11, 2026
10 deliberate RAG failure modes with runnable scripts showing each break and its fix. Chunking, prompt injection, citation hallucinations, stale indexes, and more, with an interactive dashboard.
Likes
0
Views
1