Knowledge Graph RAG: 6-Stage Retrieval on Neo4j
Sergiu Nicoara
Knowledge Graph RAG
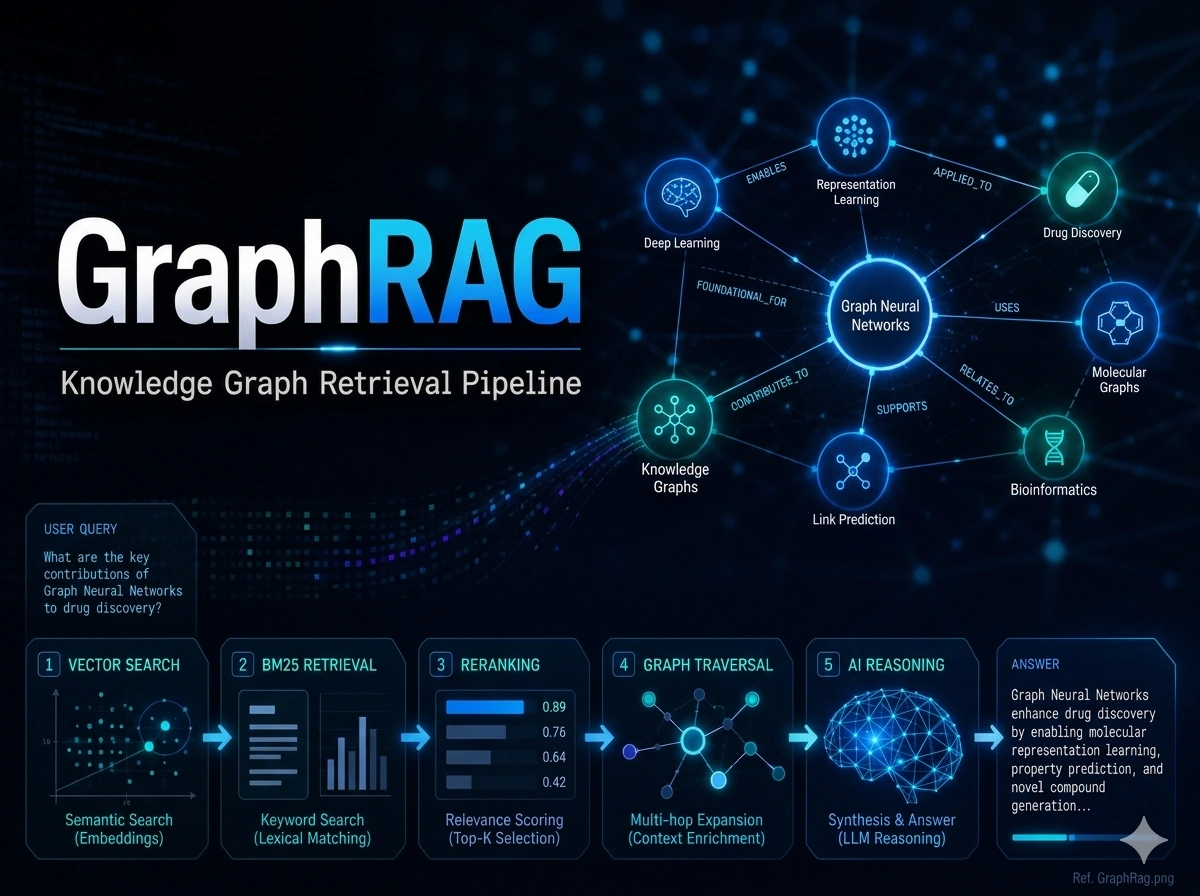
A 6-stage knowledge graph retrieval pipeline on Neo4j that combines vector search, lexical search, graph traversal, and neural re-scoring into a single grounded generation system. Classical RAG retrieves flat chunks with no understanding of relationships, no multi-hop reasoning, and no way to connect evidence across documents. This system does all three.
Why GraphRAG
Standard RAG fails on real documents. Ask "What did the founder's logistics company achieve in Southeast Asia?" and the answer is spread across 3 documents: Doc 1 says Sarah Chen founded Meridian Capital in 2009, Doc 2 says Meridian acquired Crestline Logistics in 2015, Doc 3 says Crestline reduced regional delivery times by 40% in 2023. Vector search finds similar chunks. It cannot connect the dots.
This system can. Multi-hop graph traversal bridges "Sarah Chen" to "Meridian Capital" to "Crestline Logistics" to "40% improvement" across documents. The graph reasons over relationships (ownership, acquisition, causality) that text similarity misses entirely.
Retrieval pipeline
Stage 1-2: Vector ANN (3072d cosine) + BM25 lexical search run in parallel
Stage 3: RRF fusion combining both ranked lists
Stage 4: Cross-encoder reranking (ms-marco-MiniLM-L-6-v2)
Stage 5: Depth-2 multi-hop graph traversal on Neo4j (Chunk → Entity → RELATES_TO → Entity → Chunk)
Stage 6: GAT GNN re-scoring with query-adaptive α/β weights
Why a GNN scoring layer
Most RAG systems rank by text similarity alone. But entities have relationships that text misses. Query: "What rockets did Elon Musk's company launch?" The cross-encoder score for the Falcon 9 chunk is -6.74 (weak text match, "Elon" isn't in it). The GAT score: 0.73, because the graph knows SpaceX → Falcon 9 → Starship are connected. The chunk stays in results. Without GNN, it drops out entirely.
The blend: final = 0.6 × sigmoid(rerank) + 0.4 × gnn. The graph compensates for what text can't see.
Knowledge base
Formally modeled with OWL ontology enforcement and OWL-RL reasoning. Features bitemporal provenance, 4-stage entity resolution (exact → fuzzy → embedding cosine ≥ 0.92), 5-typed contradiction detection, and document authority hierarchy with SUPERSEDES chains.
Agentic fallback
IRCoT dual-LLM fallback (8B routing + 70B synthesis) auto-triggers on hedge signals or zero-citation responses, replacing hallucinated answers with explicit "insufficient context" refusal. Up to 4 iterative retrieval steps before honest refusal.
The trigger logic matters. My first implementation used OR logic: fall back if the answer hedged OR had zero citations. On a sparse corpus, that fired on ~40% of queries. Average latency looked fine, so I almost missed it. The fix was one line: OR → AND. Fall back only when the answer hedges AND has no citations. Trigger rate dropped to ~9%, without hurting sampled answer quality.
Trigger rate is the metric I now watch hardest. If it climbs from 9% to 25%, combined p95 barely moves (hybrid p95: 2.2s, agentic fallback p95: 3.4s, combined: 2.7s). But the system is quietly failing more often and paying an agent to cover for it. Combined metrics hide the modes that matter.
Debugging the eval, not the model
My faithfulness score said 0.785. The real number was 0.940. The model wasn't broken. My measurement was.
After a re-ingestion, one eval question collapsed from 1.0 to 0.0. I assumed regression. I found two bugs instead, neither in the model.
Bug 1: RAGAS never saw what the LLM saw. The retriever builds context from three sources: local chunks, entity context, community summaries. The LLM got all three. The eval judged against local chunks only. Correct claims grounded in the other two sections looked like hallucinations.
Bug 2: Community summaries didn't know a regulation was superseded. The graph knew: 2024 directive supersedes 2022 supersedes 2020. Edges all correct. The summarizer didn't look. It called the 2020 directive "the key directive" and the LLM trusted it, answering compliance questions from a dead regulation. Summaries are caches. They go stale like any cache.
Two fixes. 0.785 → 0.940. Same model, same retrieval, same corpus. When a metric drops, "the system got worse" and "the measurement is lying" are equally likely.
Self-audit: 11 silent bugs
I audited my own implementation. Found 11 bugs. None crashed. All corrupted data silently.
Formula bugs: Documented GNN blend (final = α·text + β·gnn) skipped α when entity data was missing. Wrong scores, no warning. Session context stored every turn, but answer was always "" because recording happened before LLM generation.
Tenant isolation: Relations matched by (name, tenant) instead of (name, type, tenant). "Apple" the ORG and "Apple" the PRODUCT silently merged. Health metrics aggregated across all tenants, so a struggling tenant looked fine because a healthy one averaged it out.
Silent degradation: Redis unreachable triggered silent in-memory fallback. Sessions die on restart, no log, no alert. graspologic missing caused Leiden to fall back to connected components. Global search degrades. You won't notice until recall drops.
Config drift: Three feature flags in settings.yml. All documented. None read at runtime.
None of these throw exceptions. None show up in RAGAS on happy-path queries. Most only surface at scale. The architecture was right. The details weren't.
Results on real aerospace regulatory data
Faithfulness: 0.937
Context precision: 0.907
Context recall: 0.867
All measured with RAGAS, not eyeballed.
Stack: Python, FastAPI, Neo4j, LangChain, Redis, RabbitMQ, Docker, GCP, Google ADK, RAGAS, Plotly Dash.
Like this project
Posted Jun 9, 2026
6-stage retrieval pipeline combining vector search, BM25, graph traversal, and GNN re-scoring. 0.937 faithfulness on real aerospace regulatory data, measured with RAGAS.
Likes
0
Views
3