Fake News Detection with DistillBERT
Balaj Khalid
In today’s digital age, the spread of fake news is a pressing concern. Accurate detection of fake news is crucial for maintaining trust in media outlets and for safeguarding the public from misinformation. As part of my portfolio project, I utilized the WELFake dataset—a comprehensive dataset containing 72,134 news articles (35,028 real and 37,106 fake) from Kaggle, McIntire, Reuters, and BuzzFeed Political datasets.
Project Overview
The WELFake dataset was curated to prevent overfitting and provide a rich and varied source of text data. The dataset includes four columns:
• Serial Number: A unique identifier for each record.
• Title: The headline of the news article.
• Text: The content of the news article.
• Label: A binary label (0 for fake news and 1 for real news).
Given the substantial size of the dataset (78,098 entries), I downsampled it to 20,000 news articles to optimize for memory and computational constraints, particularly focusing on my available RAM and GPU resources.
Data Preprocessing
To prepare the data for machine learning, I performed several preprocessing steps:
1. Removed Missing Values: Rows with null titles or text were discarded to ensure quality data.
2. Text Tokenization: The raw text was tokenized into individual words, ensuring that the text could be processed by machine learning models.
3. URL Removal: URLs were removed as they do not contribute to the textual content in a meaningful way for fake news classification.
4. Stop Words Removal: Common but unimportant words (e.g., “the”, “and”, “is”) were removed to enhance model performance by reducing noise.
5. Stemming: Words were reduced to their root form to standardize variations and increase the model’s ability to generalize.
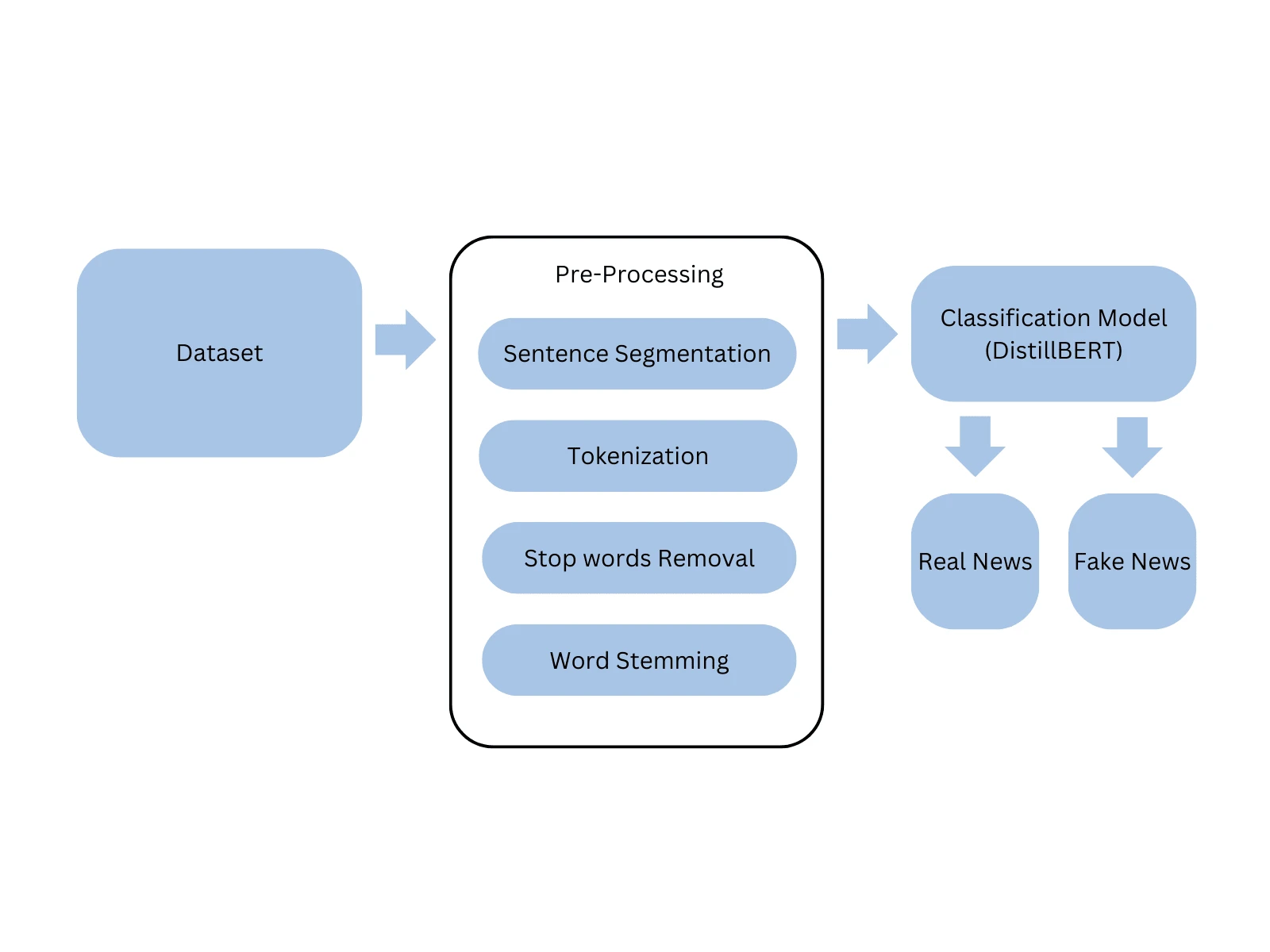
Approach for Fake News Classification
Model Development and Training
For the model, I chose DistillBERT, a lightweight version of the powerful BERT model that excels in natural language understanding tasks. It was fine-tuned on the preprocessed data to classify the articles as real or fake news.
I split the dataset into:
• Training Set (64%): Used to train the model.
• Validation Set (16%): Used to validate and tune the model during training.
• Test Set (20%): Used for evaluating the final model’s performance.
The model was trained for 3 epochs, providing a balanced trade-off between computation time and model performance.
Results
After training the model, I evaluated its performance on the test set. The test accuracy achieved was 98.19%, showcasing the model’s exceptional ability to distinguish between real and fake news articles. This high level of accuracy is a testament to the quality of the preprocessing and the power of the DistillBERT model for NLP tasks.
Conclusion
This project highlights my ability to manage large datasets, apply effective text preprocessing techniques, and leverage advanced machine learning models such as DistillBERT for real-world applications like fake news detection. With a test accuracy of 98.19%, the model demonstrates great promise for practical deployment in detecting fake news, making it an essential tool for media organizations and online platforms to combat misinformation.
View full notebook on Github.
Like this project
Posted Feb 10, 2025
Built a fake news detection model using WELFake dataset, achieving 98.19% test accuracy with DistillBERT after extensive data preprocessing and model training.
Likes
0
Views
20