Multilayer Perceptron model vs CNN
Saumyadeepta Sen
Multilayer Perceptron model vs CNN

·
Published in
·
3 min read
·
Aug 4, 2020
--

Multilayer perceptrons are sometimes colloquially referred to as “vanilla” neural networks, especially when they have a single hidden layer. — MLP Wikipedia
A multilayer perceptron (MLP) is a class of feedforward artificial neural network. A MLP consists of at least three layers of nodes: an input layer, a hidden layer and an output layer. Except for the input nodes, each node is a neuron that uses a nonlinear activation function. MLP utilizes a supervised learning technique called backpropagation for training. Its multiple layers and non-linear activation distinguish MLP from a linear perceptron. It can distinguish data that is not linearly separable.
Multilayer Perceptron (MLP)
This is used to apply in computer vision, now succeeded by Convolutional Neural Network (CNN). MLP is now deemed insufficient for modern advanced computer vision tasks. It has the characteristic of fully connected layers, where each perceptron is connected with every other perceptron. The disadvantage is that the number of total parameters can grow to very high (number of perceptron in layer 1 multiplied by # of p in layer 2 multiplied by # of p in layer 3…). This is inefficient because there is redundancy in such high dimensions. Another disadvantage is that it disregards spatial information. It takes flattened vectors as inputs. A light weight MLP (2–3 layers) can easily achieve high accuracy with MNIST dataset.
Convolutional Neural Network (CNN)
The incumbent, current favorite of computer vision algorithms, winner of multiple ImageNet competitions. Can account for local connectivity (each filter is panned around the entire image according to certain size and stride, allows the filter to find and match patterns no matter where the pattern is located in a given image). The weights are smaller, and shared — less wasteful, easier to train than MLP. It is more effective too, can also go deeper. Layers are sparsely connected rather than fully connected. It takes matrices as well as vectors as inputs. The layers are sparsely connected or partially connected rather than fully connected. Every node does not connect to every other node.
Now , let us see how MLP and CNN models work in our MNIST dataset. You can find the dataset in Kaggle:https://www.kaggle.com/c/digit-recognizer/data
First of all let us import all the libraries required. Then we read the data and reshape the image dimensions. Finally we will take a look at a few samples from our dataset.

Now, we will create a MLP model using
Sequential class in Keras.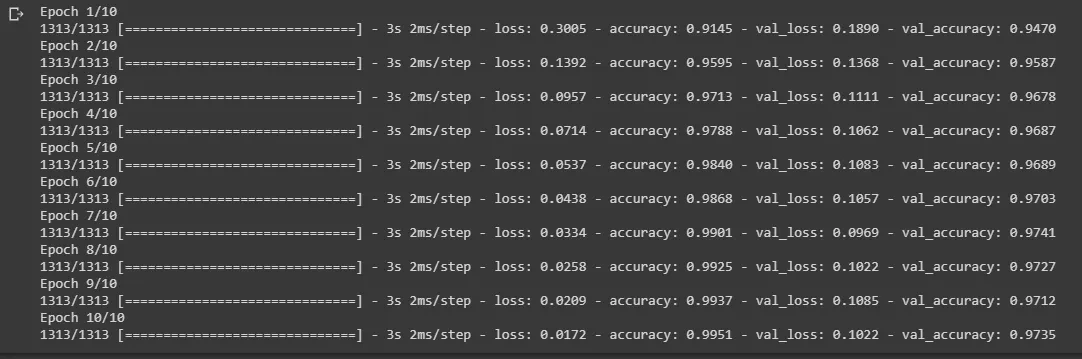
We finally visualize our training model after using MLP.
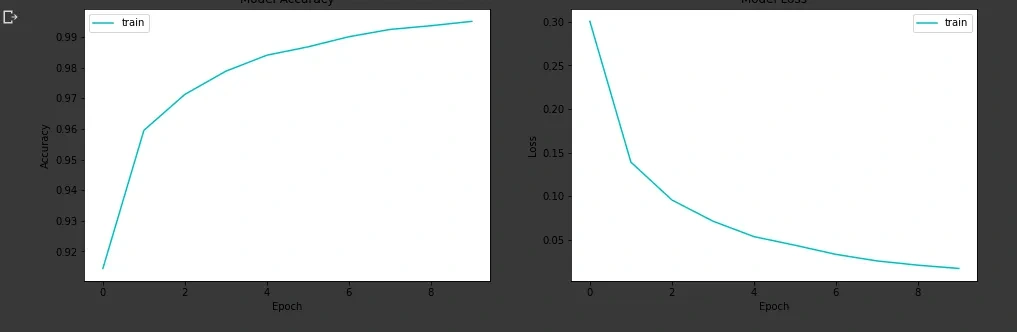
Convolutional Neural Network
Lets see how to build a CNN model using Keras.
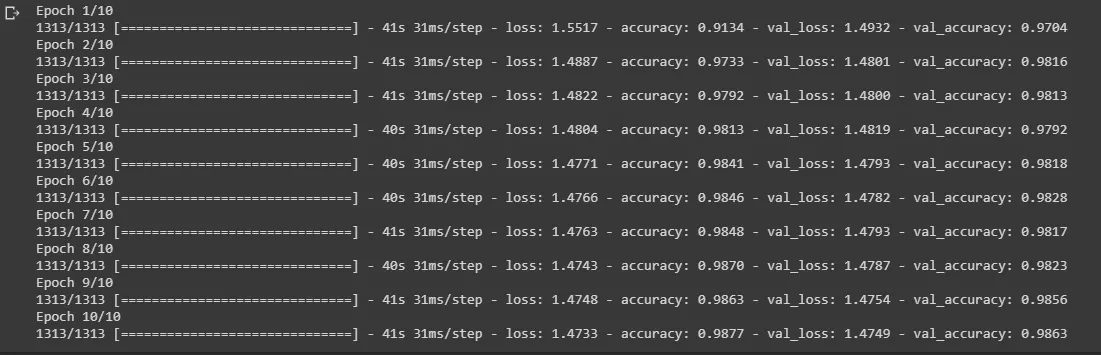
Next, we plot the metrics after training the CNN model.
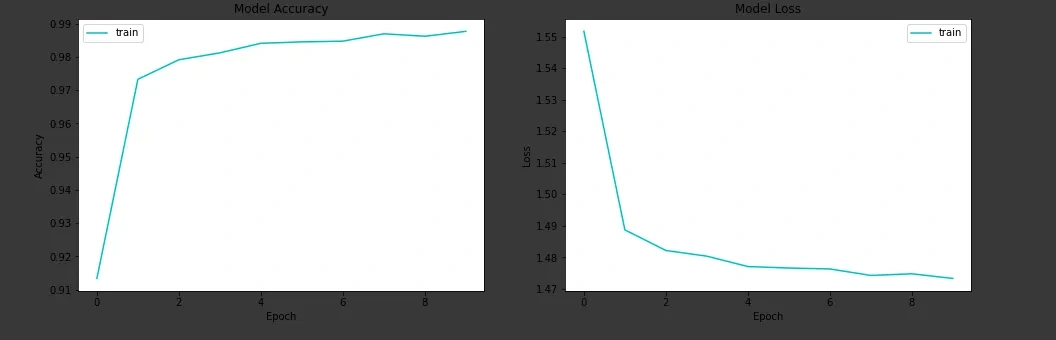
It is clearly evident that the CNN converges faster than the MLP model in terms of epochs but each epoch in CNN model takes more time compared to MLP model as the number of parameters is more in CNN model than in MLP model in this example. The accuracy in both the cases is more or less the same, but for better results in other datasets we always prefer CNN model.
Like this project
Posted Aug 27, 2024
Multilayer perceptrons are sometimes colloquially referred to as “vanilla” neural networks, especially when they have a single hidden layer. — MLP Wikipedia Th…
Likes
0
Views
23