Web Scraper Selenium web driver
Sameh Hasan
Web Scraper Selenium web driver
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites.
Scraping a web page involves fetching it and extracting from it. Fetching is the downloading of a page (which a browser does when a user views a page). Therefore, web crawling is a main component of web scraping, to fetch pages for later processing. Once fetched, extraction can take place. The content of a page may be parsed, searched and reformatted, and its data copied into a spreadsheet or loaded into a database. Web scrapers typically take something out of a page, to make use of it for another purpose somewhere else. An example would be finding and copying names and telephone numbers, companies and their URLs, or e-mail addresses to a list (contact scraping).
This application that I've built collects information about the solar radiance in each country, the direct normal irradiance. The purpose was to implement a database for one of my projects (Solar panel calculator). Which was my final project for cs50.
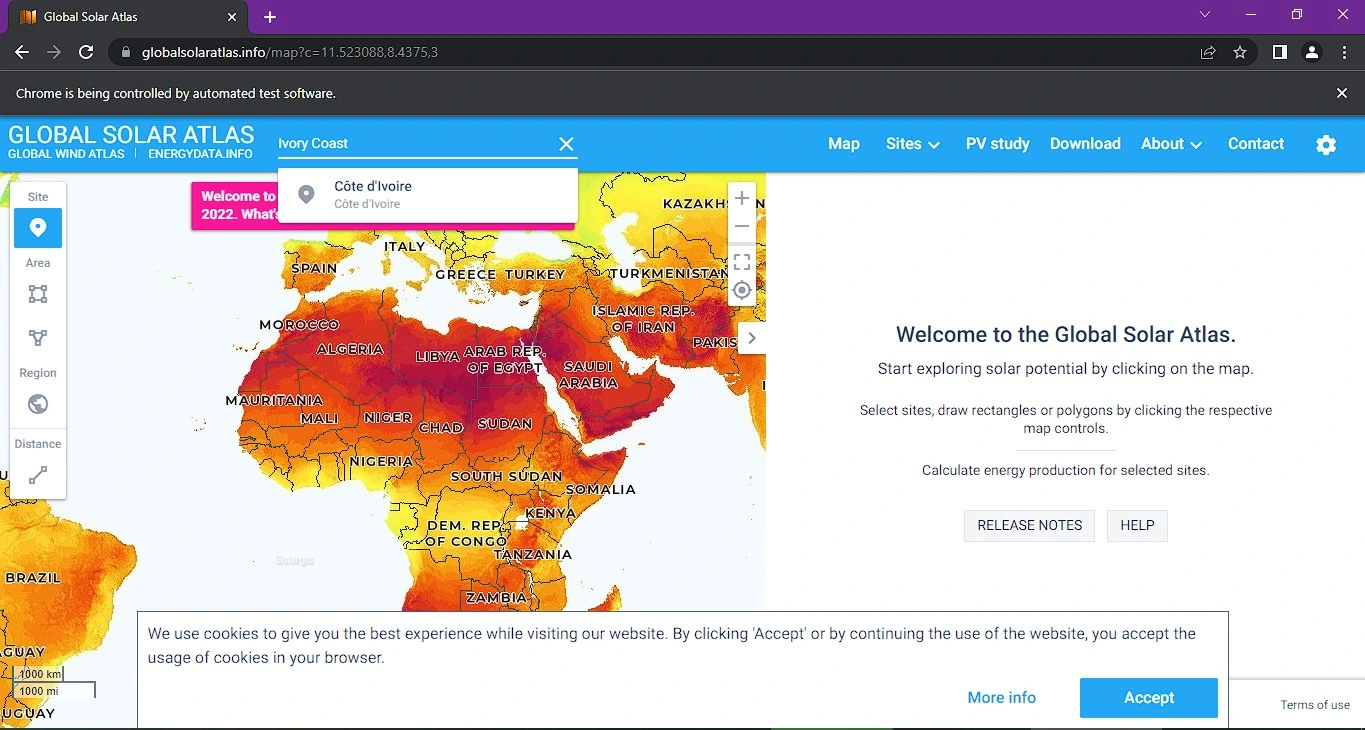
How it works:
The web driver is initialized and opens up the web page
It looks for the search bar and inserts the name of the country using a list saved with in the files attached to the python script
Searches for the country name and extracts the information in the units I preferred
Saves this information in a json file for ease of usage later in the project
Repeats the same process for all the countries in the list
To use this program, simply run the scraper.py file and wait for the program to complete. Once the program is finished, the extracted data will be available in the output.json file, which can be opened and viewed in any text editor or JSON viewer.
Like this project
Posted Mar 17, 2024
This application that I've built collects information about the solar radiance in each country and the direct normal irradiance.
Likes
0
Views
14