Predict Remaining Life of Pipe
Michael Tawk
Objective
The client sought to predict how long a pipe transporting fluids will still serve before leaking. The goal was to develop, train and tune Machine Learning algorithms and find the best performing algorithm. The client had a large dataset of pipelines failing due to different causes.
Methodology
The dataset had a lot of outliers and blanks. In addition to that the dataset contained a lot of redundant predictors that don't have add value to the problem at hand. After dropping outliers and filling the missing data with the most recurring values, the numerical predictors were normalized to not give advantage to predictors with a bigger scale range and categorical predictors were transformed to numerical classes.
After the data was made ready the search for the best algorithm can be initiated. Deep Neural Networks with different architectures were evaluated, in addition to that Ensemble Models like ExtraTrees, RandomForest, XGB were evaluated and proved to perform better for this specific problem
Results
Using ExtraTrees an R2 score of 90.36% and RMSE of 2.72 was achieved.
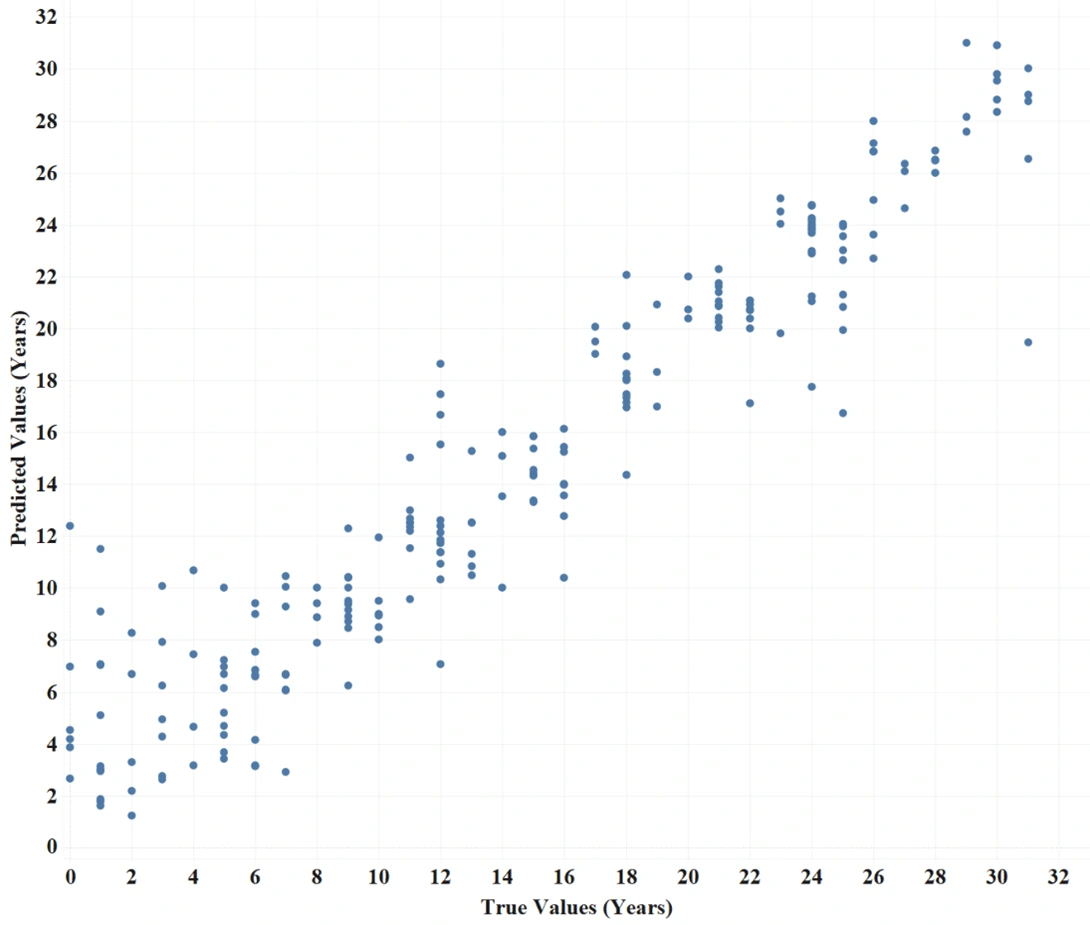
Predicted values function of true values for tuned XTR model.
The client also requested to provide the most contributing predictor in his dataset. For this purpose SHAP Values were used.
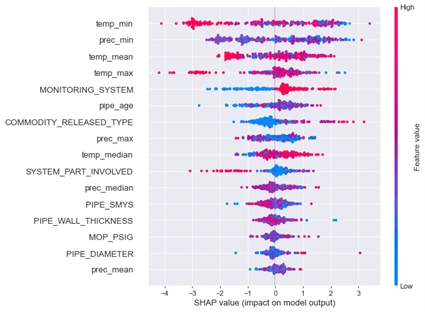
SHAP Values for the XTR model.
Finally a detailed report was written that provides intricate details on the algorithms used and on the flow of work.
Like this project
Posted Jul 14, 2024
Developed the best performing Machine Learning algorithm to provide most accurate result about remaining time before pipe fails.
Likes
0
Views
22