Parallelizing Modern Machine Learning Pipelines
Pratishthit Choudhary
Abstract
In the new generation, with high-performance computing machines with thousands of cores, machine learning pipelines made the process of training large amounts of data (talking in petabytes). However, a general person or a small business owner does not usually have access to such computational power, but only to a machine with 6 or 8 cores on average. These machines are sufficient for light to medium machine learning training processes but fail to scale such applications. This is where we take advantage of High-Performance Computing practices such as parallelization on multiple processes/cores to scale machine learning applications and reduce time spent on training the models.
Introduction
For the machine learning problem statement, I have picked up the Covid-19 dataset for the confirmed number of cases in the United States. Our aim is to run and train a machine learning regression model for each state to predict the number of cases for the upcoming week. The idea behind this project was taken from a Towards Data Science article.
In this project, I worked with a newly introduced machine learning library called PyCaret, an open-source, low-code library in python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that exponentially speeds up the experiment cycle and makes you more productive. PyCaret is essentially a Python wrapper around several machine libraries and frameworks such as scikit-learn, LightGBM, CatBoost, and many more.
Platform
The project has been placed on a Docker container that has a Linux distro and comes built-in with Python:3.8
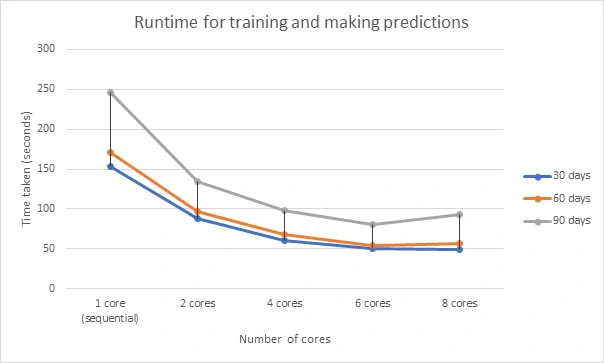
Runtime comparison with the number of cores
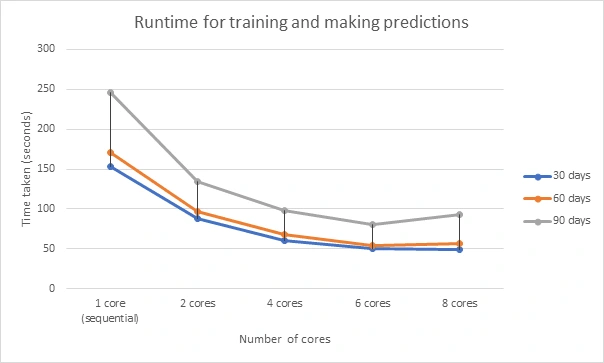
Speedup comparison
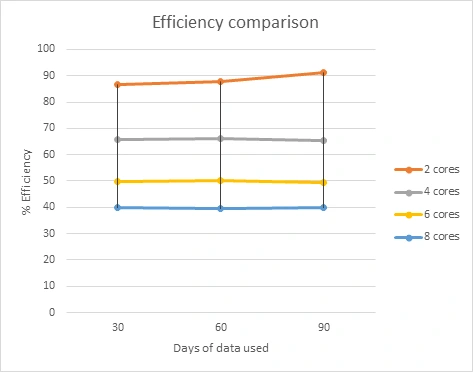
Efficiency Comparison
Like this project
Posted Jan 20, 2022
Likes
0
Views
85