CV/job offer analyzer and compatibility evaluation
Valentin Forestier
During my time at Neuligent, I worked on a tool to evaluate resumes and job offers. The system I've designed allows you to summarize CVs and job offers and also assess whether a candidate is suitable for a position.
First I had to design the document importation system. The supported formats are PDF, DOC, DOCX and TXT. PDFs can be read thanks to an OCR (Optical Character Recognition) tool that I have implemented thanks to Tesseract. After importation, we can then view the generated CV or job summaries. In the example below, where I've imported my own CV, we can see that the information has been correctly rendered and grouped: there are the skills I've mentioned, as well as my diplomas, work experience and other information.
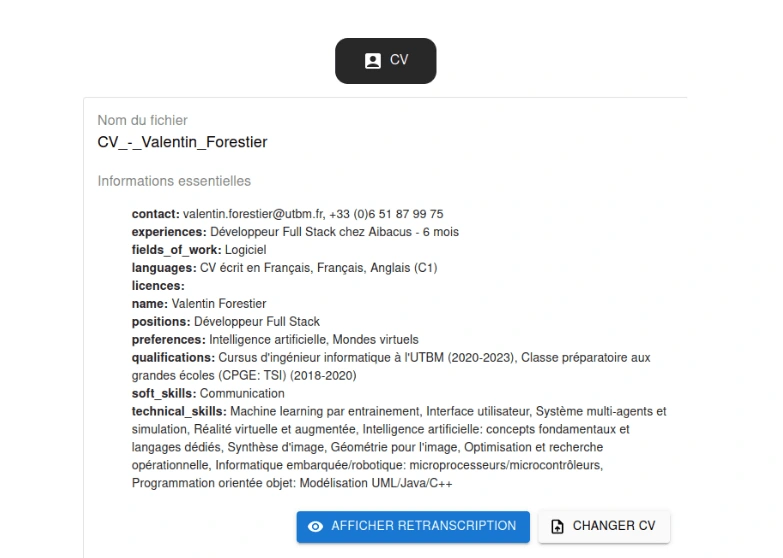
To generate these CV and job advert summaries, GPT (Generative Pre-trained Transformer) was used. It is a natural language processing model based on neural networks that has been pre-trained on a large amount of textual data.
Writing the query to ask GPT to generate a summary required a lot of fine-tuning, for two reasons. Firstly, the quality of the summary can vary according to the wording of the query: in some cases, GPT may omit information or create false information. Secondly, it is necessary to retrieve the information in a precise format so that it can be reused later, but GPT can have difficulty generating a requested format. After much trial and error, I finaly found the right query and automatized a lot of modification to the request result to achieve the final result you can observe above.
One of the main tools I worked on was the fitting tool, which consisted of using several adverts and resumes to sort each possible association into three categories: the first category made up of associations for which the candidate is a good candidate for the job. The second category for cases where the candidate is not perfect but could be considered. And a final category for incompatible candidates.
The initial strategy for creating the fitting was to fine-tune GPT. Fine-tuning is a technique commonly used in machine learning to adapt pre-trained neural network models to specific tasks. This technique involves adjusting the weights and biases of an existing model so that it performs optimally on a new task.
After a lot of research and trial and error, the best solution I found consisted in using both GPT, BERT, and a decision tree to finaly obtain a 95.5% precision on the test dataset.
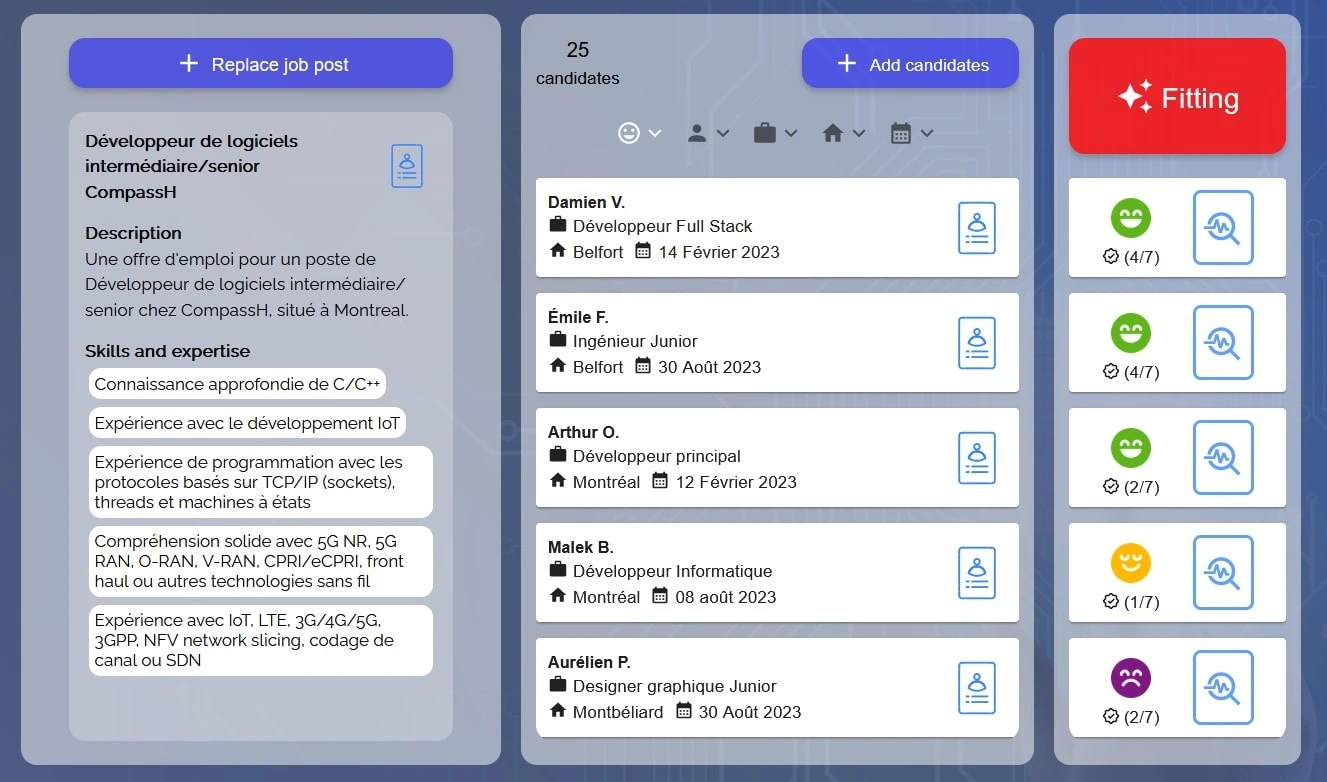
Now that we can sort the resumes by compatibility, we need to justify the result, for this, I used BERT to sort skills/languages/experiences according to which ones a relevant for the job. I also used GPT to generate comments on the result and a sentiment analysis model I trained to write in green positive comments and red negative ones. We obtain a summarized resume with commentaries and highlighted relevant information:

To justify even further, a criteria-based matching feature has been added to see which required elements stated in the job offer the candidate meets:

Other features has been added such as a search engine for resumes, a filtering system, a sorting system, or a psychometric evaluation of a candidate.
Like this project
Posted Apr 12, 2024
Creation of a platform for evaluating CVs and job offers to determine which candidates are suitable for which positions.
Likes
0
Views
23