Machine Learning Model for Water Quality Classification
Faisal Ahmad Gifari
LAPORAN PROYEK MACHINE LEARNING - Klasifikasi Kualitas Air Minum
Domain Proyek
Air merupakan salah satu kebutuhan yang harus dipenuhi dalam kehidupan manusia[1]. Kehadirannya sangat penting untuk kesehatan dan vitalitas tubuh kita karena tubuh manusia membutuhkan air untuk berfungsi dengan baik[2]. Air berguna untuk pencernaan, penyerapan nutrisi, dan pembuangan sisa[3]. Air juga berfungsi untuk mengontrol suhu tubuh, tekanan darah, dan melumasi persendian[4]. Kekurangan air tubuh bahkan dapat menyebabkan dehidrasi, yang jika tidak diatasi dapat fatal [5]. Oleh karena itu, sangat penting bagi setiap orang untuk selalu mengonsumsi jumlah air yang cukup setiap hari agar tubuh tetap sehat.
Di Indonesia, masalah air yang tidak memenuhi standar kualitas masih menjadi perhatian serius. Baik di kota-kota maupun desa, kondisi air tahan di Indonesia semakin buruk [6]. Berdasarkan riset dari Kemenkes pada tahun 2020, 74,4% rumah tangga di Indonesia akses air minumnya tercemar oleh bakteri E.coli [7]. Air minum yang bersifat basa atau asam dapat mempengaruhi pencernaan dan gangguan lambung, ginjal, dan pembuluh darah [8]. Maka dari itu, memastikan ketersediaan air yang layak untuk diminum harus menjadi prioritas utama pemerintah dan lembaga terkait demi kesejahteraan dan kesehatan seluruh masyarakat Indonesia.
Untuk memastikan bahwa air aman untuk dikonsumsi, proses penting harus dilakukan berdasarkan berbagai parameter untuk mengukur kualitas air dengan pembuatan model machine learning [9] machine learning dapat memastikan keamanan konsumsi air karena dapat mendeteksi kualitas air dengan sangat baik dengan mengenali pola dari data historis yang dikumpulkan dari berbagai sumber [10]. Dalam machine learning, banyak algoritma yang dapat digunakan untuk melakukan klasifikasi, seperti KNN, SVM, dan Random Forest[11]. Dengan memanfaatkan berbagai data untuk setiap variabel yang didapat dan menggunakan algoritma klasifikasi, pembuatan model untuk mengklasifikasikan kualitas air dapat dilakukan[12].
Business Understanding
Angka konsumsi air minum yang tidak layak di Indonesia masih tinggi. Maka dari itu, dibutuhkannya pengembangan model machine learning untuk mengklasifikasikan kualitas air minum sebagai sarana untuk membantu dan memastikan apakah air minum yang ingin dikonsumsi layak atau tidak. Salah satu manfaat dari adanya model klasifikasi kualitas air ini adalah model ini dapat digunakan oleh pemerintah atau pihak perusahaan air minum untuk memastikan apakah air yang mereka distibrusikan layak untuk diminum atau tidak. Oleh karena itu, dengan melakukan pengecekan kualitas air minum, konsumen atau masyarakat luas dapat terhindar dari konsumsi air tidak layak minum yang dapat menyebabkan berbagai masalah kesehatan.
Problem Statements
Berdasarkan eksplorasi terhadap dataset, fitur-fitur apa saja yang dapat menentukan atau memberi pengaruh terhadap klasifikasi layak atau tidaknya air minum?
Bagaimana memproses dataset agar dapat digunakan untuk pembuatan model machine learning klasifikasi kualitas air minum?
Bagaimana cara medapatkan model klasifikasi kuaitas air minum dengan performa terbaik?
Goals
Melakukan eksplorasi semua fitur-fitur yang terdapat pada dataset dan melihat fitur-fitur mana saja yang memiliki pengaruh besar atau memiliki korelasi tinggi terhadap label klasifikasi air.
Melakukan data preparation untuk mempersiapkan model untuk proses training.
Melakukan proses training dengan baseline model dari berbagai algoritma dan menggunakan baseline model dengan performa terbaik untuk melakukan hyperparameter tuning. _
Solution statements
Untuk melakukan eksplorasi fitur dilakukan analisis univariat dan multivariat untuk menemukan hubungan antar fitur baik data numerik maupun data kategorikal. Kemudian, menggunakan barchart, heatmap, dan correlation matrix untuk medapatkan informasi lebih lanjut
Untuk mendapatkan data yang bersih untuk diproses ke tahap modelling, dilakukannya proses data preparation yang terdiri dari data cleaning, train test split, dan data transformation. Kebersihan data dapat mempengaruhi performa model yang akan dibuat.
Untuk mendapatkan model dengan performa terbaik, digunakan 3 algoritma sebagai baseline model, yaitu
KNN, SVM, dan Random Forest. Kemudian, untuk dapat mengetahui baseline model mana yang memiliki performa terbaik dapat dilakukan evaluasi menggunakan Confusion Matrix (Accuracy, Precision, Recall, F1 Score) yang juga divisualisasikan. Selanjutnya, model yang terpilih akan dibantu dengan grid search untuk menemukan hyperparameter yang memiliki performa terbaik. Terakhir, model tersebut dilakukan evaluasi menggunakan Confusion Matrix (Accuracy, Precision, Recall, F1 Score).Data Undestanding
Dataset yang digunakan untuk pembangunan model machine learning ini adalah dataset "Water Quality and Potability" yang tersedia di situs web Kaggle. Dataset tersebut adalah dataset kuantitatif yang berisi kolom-kolom yang dapat menentukan sebuah kualitas air layak diminum atau tidak. Dataset ini memiliki 3276 baris dan 10 kolom data.
Dataset ini cocok untuk membangun model supervised learning, khususnya binary classification. Dalam kasus ini adalah untuk mengklasifikasinya sampel sebuah air layak diminum (Potable) atau tidak layak diminum (Not Potable)
Dataset tersebut dapat diunduh disini.
Berikut ini adalah informasi lainnya mengenai variabel-variabel yang terdapat di dataset tersebut:
Variabel-variabel pada Dataset "Water Quality and Potability" adalah sebagai berikut:
pH: Tingkat pH air.Hardness: Ukuran kandungan mineral.Solids: Total padatan terlarut dalam air.Chloramines: Konsentrasi kloramin dalam air.Sulfate: Konsentrasi sulfat dalam air.Conductivity: Konduktivitas listrik di air.Organic_carbon: Kandungan karbon organik dalam air.Trihalomethanes: Konsentrasi trihalometan dalam air.Turbidity: Tingkat kekeruhan, ukuran kejernihan air.Potability: Variabel target. menunjukkan potabilitas air dengan nilai 1 (layak minum) dan 0 (tidak layak minum).Kemudian, untuk meningkatkan pemahaman atas data terkait, dilakukannya exploratory data analysis dan Visualisasi Data.
Exploratory Data Analysis
Exploratory Data Analysis (EDA) adalah pendekatan analisis data yang bertujuan untuk memahami karakteristik utama dari kumpulan data. EDA melibatkan penggunaan teknik statistik dan visualisasi grafis untuk menemukan pola, hubungan, atau anomali untuk membentuk hipotesis. Proses ini sering kali tidak terstruktur dan dianggap sebagai langkah awal penting dalam analisis data yang membantu menentukan arah analisis lebih lanjut.
Berikut ini adalah EDA yang dilakukan:
ph Hardness Solids Chloramines Sulfate Conductivity Organic_carbon Trihalomethanes Turbidity Potability count 2785 3276 3276 3276 2495 3276 3276 3114 3276 3276 mean 7.08079 196.369 22014.1 7.12228 333.776 426.205 14.285 66.3963 3.96679 0.39011 std 1.59432 32.8798 8768.57 1.58308 41.4168 80.8241 3.30816 16.175 0.780382 0.487849 min 0 47.432 320.943 0.352 129 181.484 2.2 0.738 1.45 0 25% 6.09309 176.851 15666.7 6.12742 307.699 365.734 12.0658 55.8445 3.43971 0 50% 7.03675 196.968 20927.8 7.1303 333.074 421.885 14.2183 66.6225 3.95503 0 75% 8.06207 216.667 27332.8 8.11489 359.95 481.792 16.5577 77.3375 4.50032 1 max 14 323.124 61227.2 13.127 481.031 753.343 28.3 124 6.739 1
Berdasarkan output tersebut, didapatkan informasi mengenai statistika deskriptif dari dataset yang digunakan. Berikut ini adalah keterangan untuk setiap bagian:
count : Jumlah data dari sebuah kolommean : Rata-rata dari sebuah kolomstd : Standar deviasi dari sebuah kolommin : Nilai terendah pada sebuah kolom25% : Nilai kuartil pertama (Q1) dari sebuah kolom50% : Nilai kuartil kedua (Q2) atau median atau nilai tengah dari sebuah kolom75% : Nilai kuartil ketiha (Q3) dari sebuah kolommax : Nilai tertinggi pada sebuah kolomVisualisasi Data
Univariate Analysis
Univariate Analysis adalah jenis analisis data yang memeriksa satu variabel (atau bidang data) pada satu waktu. Tujuannya adalah untuk menggambarkan data dan menemukan pola yang ada dalam distribusi variabel tersebut. Ini termasuk penggunaan statistik deskriptif, histogram, dan box plots untuk menganalisis distribusi dan memahami sifat dari variabel tersebut.
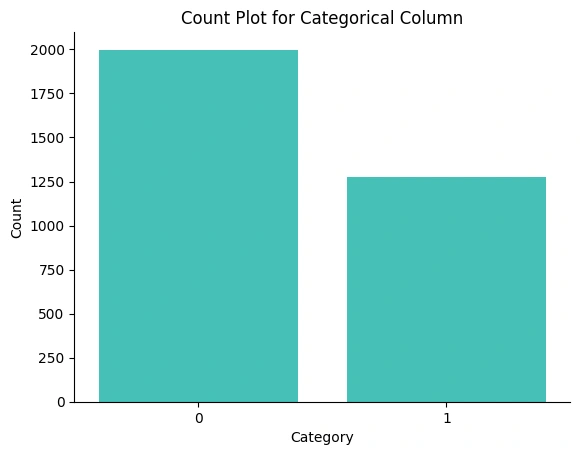
Gambar 1a - Univariate Analysis Categorical Column
Berdasarkan
Gambar 1a , terlihat bahwa Potability memiliki dua unique value, yaitu '1' yang menyatakan air layak minum dan '0' yang menyatakan air tidak layak minum. Namun, terlihat juga bahwa adanya imbalance data atau ketidakseimbangan data. nilai '0' memiliki baris data hingga nyaris 2000 baris data, sedangkan nilai '1' hanya memiliki sekitar 1250 baris data. Berangkat dari informasi ini, perlu dilakukan penyeimbangan agar tidak terjadi bias pada model machine learning yang akan dibangun.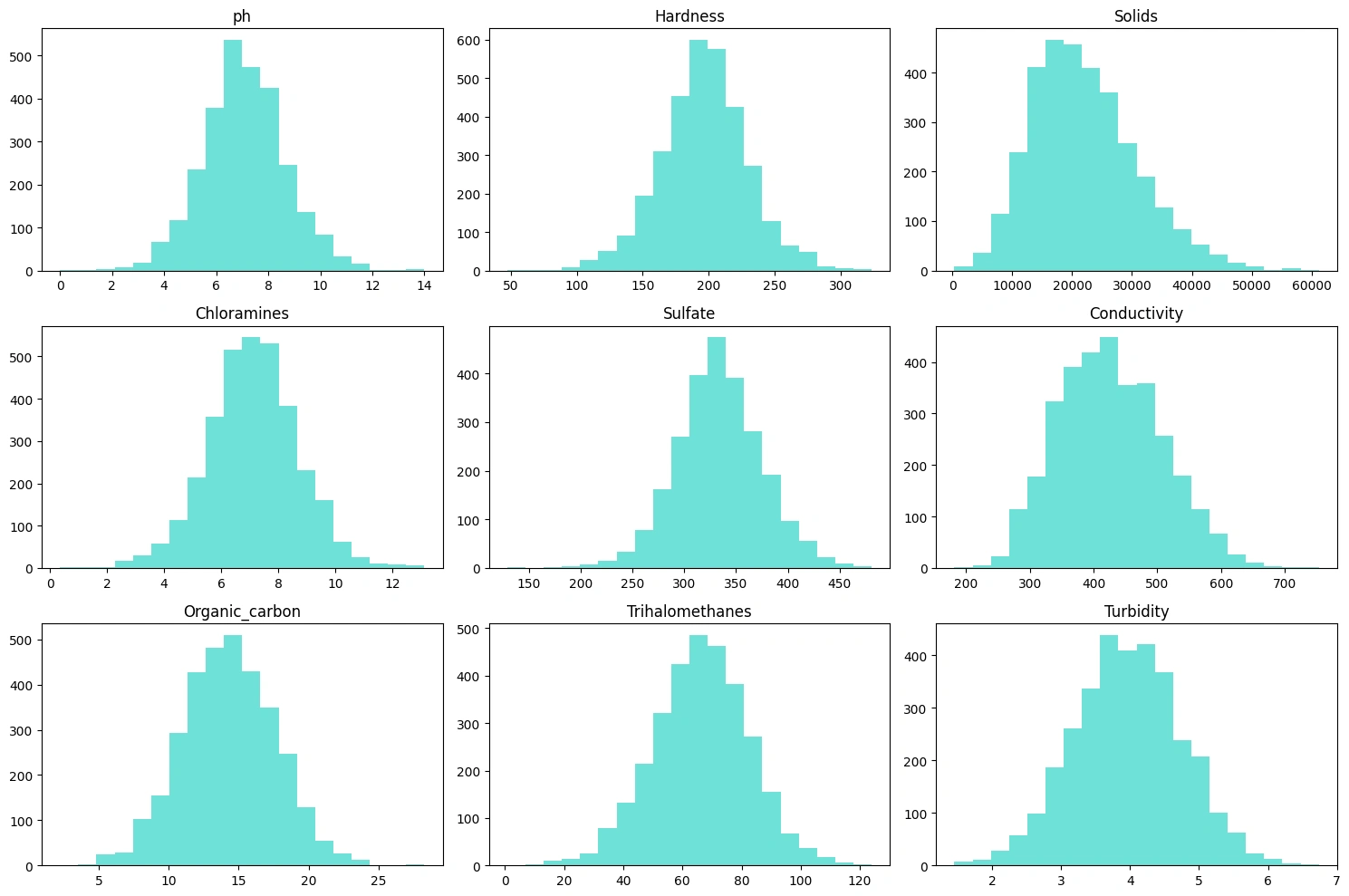
Gambar 1b - Univariate Analysis Numeric Column
Berdasarkan
Gambar 1b, gambar ini menampilkan setiap kolom numerik yang ada pada dataset, seperti pH, Hardness, Solids, Chrolamines, Sulfate, Conductivity, Organic_carbon, Trihalomethanes, Turbidity. Dari semua kolom yang ditampilkan, hanya kolom Solids dan Conductivity yang memiliki skewness ke arah kiri. Berikut adalah informasi singkat yang didapatkan dari visualisasi diatas:pH: Tingkat pH berkisar antara 0 hingga 14, dengan sebagian besar sampel memiliki pH sekitar 7, yang merupakan netral.Hardness: Kesadahan air bervariasi, dengan sejumlah besar sampel menunjukkan tingkat kesadahan sekitar 200.Solids: Terdapat kisaran total padatan terlarut dalam sampel, dengan konsentrasi puncak mendekati 20.000.Chloramines: Kadar kloramin dalam sampel mencapai puncaknya mendekati 7 atau 8.Sulfate: Konsentrasi sulfat mencapai puncaknya sekitar 300.Conductivity: Konduktivitas sampel menunjukkan puncak pusat mendekati 400.Organic_carbon: Nilai paling umum untuk kandungan karbon organik adalah sekitar 14 hingga 15.Trihalomethanes: Frekuensi kadar trihalomethane paling tinggi sekitar 65 hingga 70.Turbidity: Tingkat kekeruhan mencapai puncaknya sekitar 3,5.Multivariate Analysis
Multivariate Analysis adalah prosedur statistik yang digunakan untuk memeriksa hubungan antara beberapa variabel secara bersamaan. Teknik ini mencakup berbagai metode seperti regresi berganda, analisis faktor, dan analisis kluster, yang membantu dalam memahami struktur dan pola yang kompleks dalam data dengan lebih dari satu variabel.
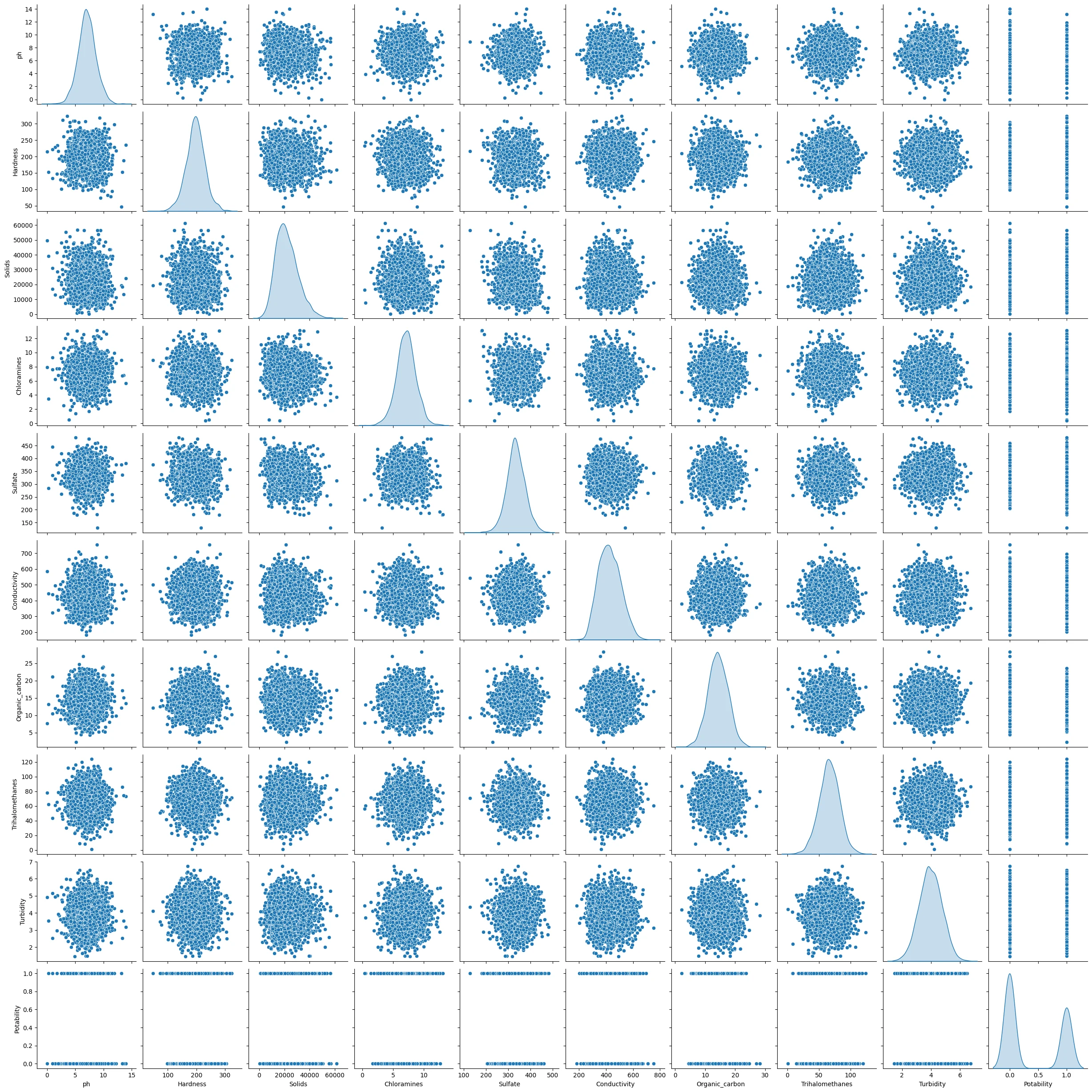
Gambar 2a - Multivariate Analysis Categorical Column - Every Numeric Column
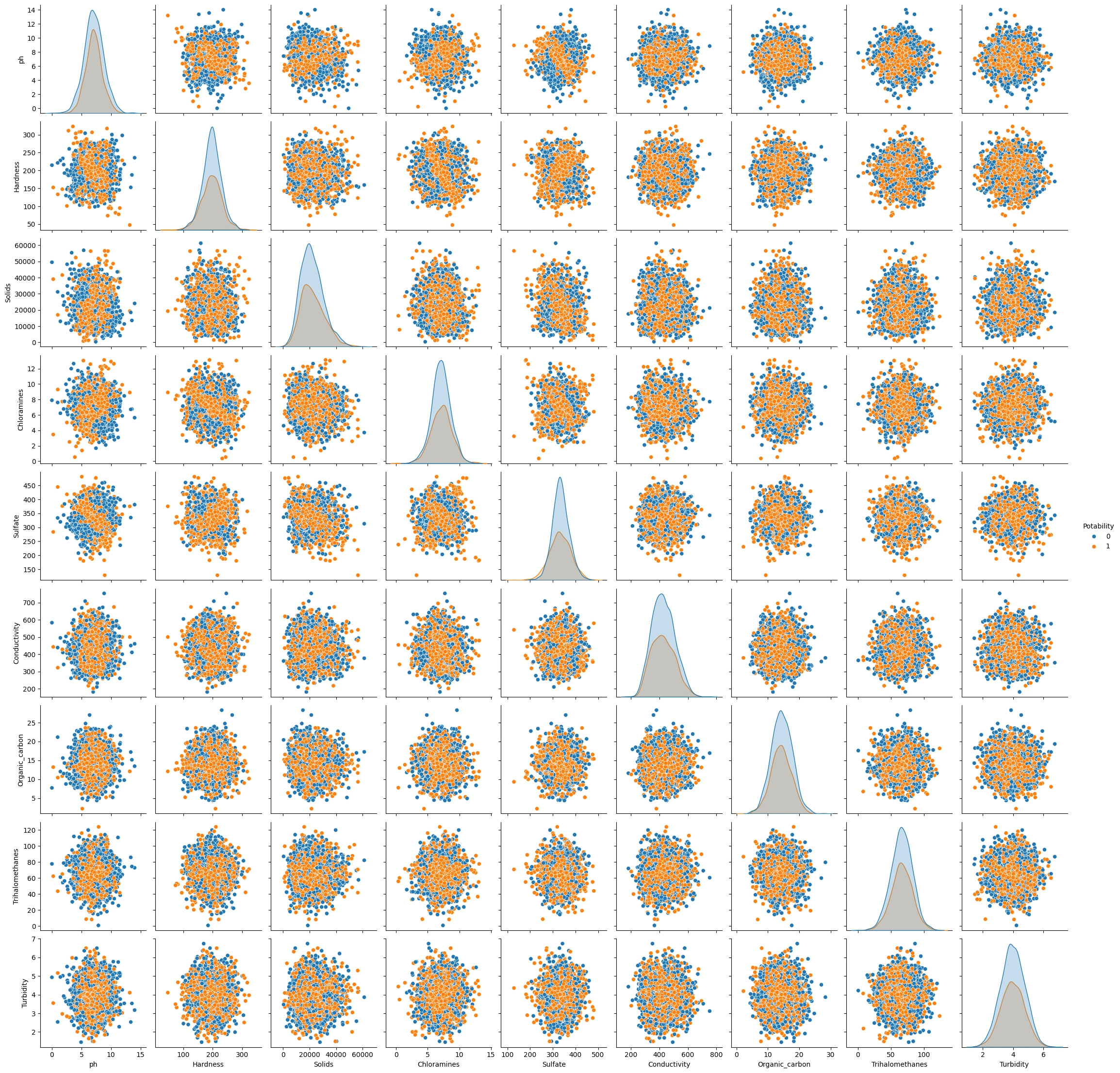
Gambar 2b - Multivariate Analysis Categorical Column - Numeric Column based on Potability
Berdasarkan gambar
Gambar 2a dan Gambar 2b, dapat terlihat nyaris semua variabel berkumpul di tengah dan tidak menunjukkan karakteristik atau pola khusus terhadap variabel label, yaitu 'Potability'. Bahkan, pada Gambar 2b sekalipun yang sudah di kategorikan berdasarkan 0 dan 1 (ditandai dengan warna oren dan biru) masih tidak terlihat karakterisik atau pola untuk value pada label tertentu. Kejadian ini mengindikasikan rendahnya korelasi antar fitur, bahkan dengan variabel label sekalipun.Correlation
Uji Korelasi adalah metode statistik yang digunakan untuk menentukan apakah ada hubungan antara dua variabel kuantitatif dan seberapa kuat hubungan tersebut. Uji ini menghasilkan nilai koefisien korelasi, seperti Pearson atau Spearman, yang berkisar antara -1 hingga +1. Nilai mendekati +1 menunjukkan korelasi positif yang kuat, sedangkan nilai mendekati -1 menunjukkan korelasi negatif yang kuat. Nilai mendekati 0 menunjukkan tidak adanya korelasi. Uji korelasi penting dalam menentukan arah dan kekuatan hubungan antar variabel, yang dapat membantu dalam pemodelan prediktif dan analisis penyebab.
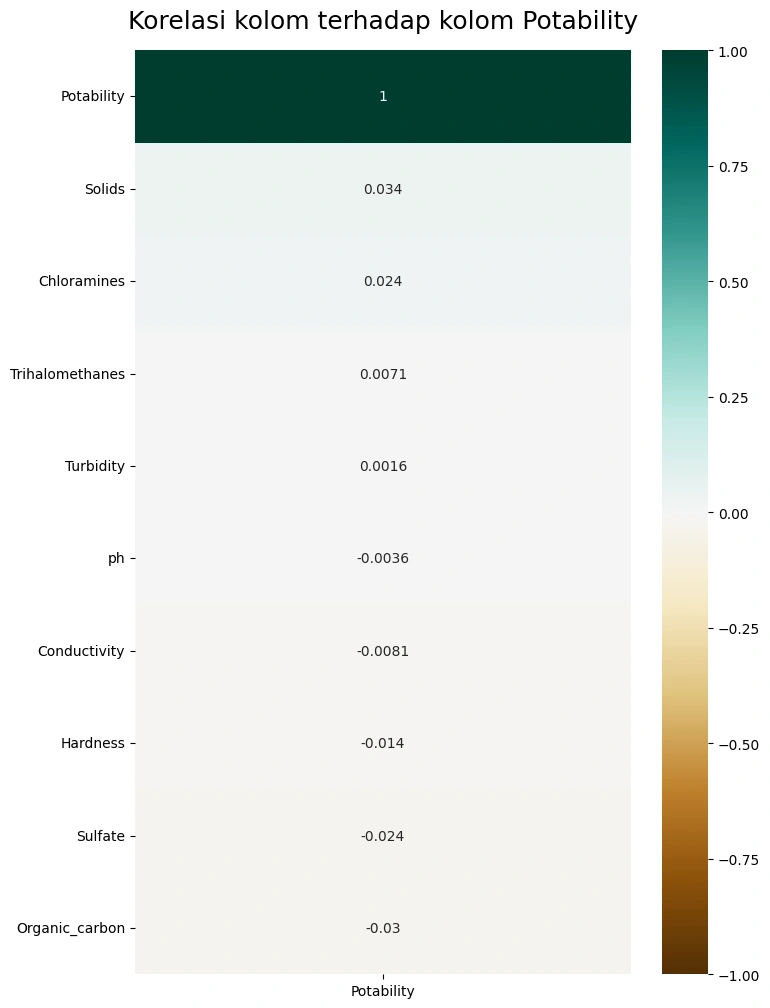
Gambar 3a - Multivariate Analysis Categorical Column - Numeric Column based on Potability
Berdasarkan
Gambar 3a, terlihat bahwa kolom pH, Conductivity, Trihalomethanes, Turbidity memiliki skor korelasi yang paling kecil terhadap label. Kolom yang semacam ini baiknya di-drop saja untuk meringankan beban komputasi dan mengurangi dimensi dari dataset yang akan digunakan dalam pelatihan model.Missing Value
Missing Values adalah data yang hilang atau tidak tercatat dalam dataset. Hal ini bisa terjadi karena berbagai alasan, seperti kesalahan entri data, kerusakan data, atau tidak tersedianya informasi saat pengumpulan data. Missing values dapat mempengaruhi kualitas model machine learning dan hasil analisis statistik. Oleh karena itu, penting untuk mengidentifikasi, menganalisis, dan mengatasi missing values dengan metode seperti imputasi, di mana nilai yang hilang diganti dengan estimasi, atau dengan menghapus baris atau kolom yang terdampak.
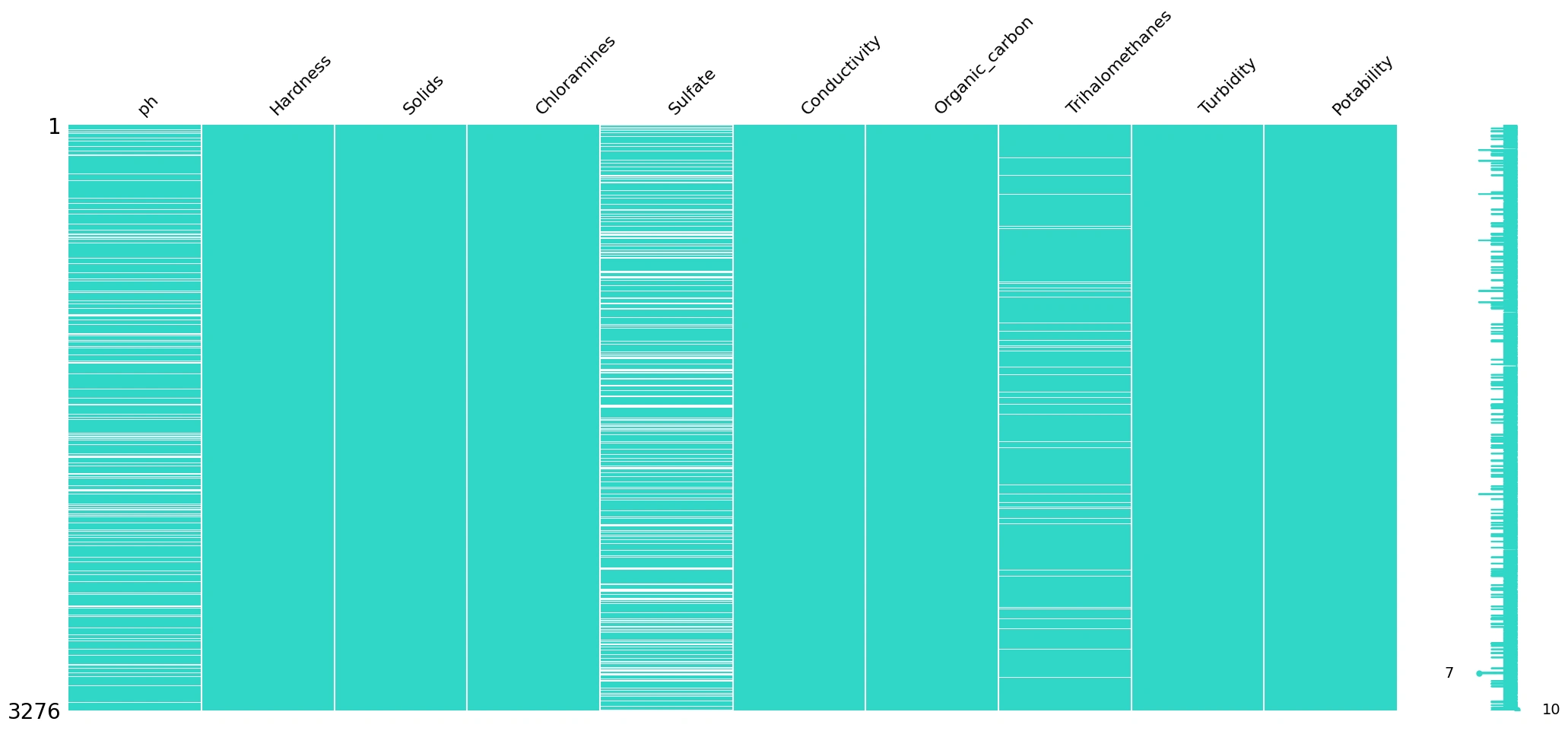
Gambar 4a - Multivariate Analysis Categorical Column - Numeric Column based on Potability
Berdasarkan
Gambar 4a, terlihat jelas bahwa memang terdapat banyak kekosongan data atau missing value pada ketiga kolom, yaitu Sulfate, ph, dan Trihalomethanes. Kondisi ini perlu tindakan lebih lanjut agar tidak mempengaruhi performa model.Data Preparation
Data Preparation adalah proses pembersihan, transformasi, dan pengorganisasian data mentah ke dalam format yang dapat dipahami oleh algoritma pembelajaran mesin. Berikut ini adalah urutan langkah-langkah Data Preparation yang dilakukan beserta penjelasan dan alasannya:
Data Cleaning
Data cleaning adalah adalah langkah penting dalam proses Machine Learning karena melibatkan identifikasi dan penghapusan data yang hilang, duplikat, atau tidak relevan yang terdapat pada dataset. Proses ini memiliki berbagai langkah yang perlu dilakukan supaya dataset siap digunakan untuk pembangunan model Machine Learning.
Alasan: Data Cleaning diperlukan agar data yang digunakan akurat, konsisten, dan bebas kesalahan, karena data yang salah atau tidak konsisten dapat berdampak negatif terhadap performa model Machine Learning
Detection and Removal Duplicates
Data duplikat adalah baris data yang sama persis untuk setiap variabel yang ada. Dataset yang digunakan perlu diperiksa juga apakah dataset memiliki data yang sama atau data duplikat. Jika ada, maka data tersebut harus ditangani dengan menghapus data duplikat tersebut.
Alasan: Data duplikat perlu didektesi dan dihapus karena jika dibiarkan pada dataset dapat membuat model Anda memiliki bias, sehingga menyebabkan overfitting. Dengan kata lain, model memiliki performa akurasi yang baik pada data pelatihan, tetapi buruk pada data baru. Menghapus data duplikat dapat membantu memastikan bahwa model Anda dapat menemukan pola yang ada lebih baik lagi.
Berikut ini adalah proses pendeteksian dan penghapusan data duplikatnya:
Berikut ini adalah hasilnya:
Berdasarkan hasil tersebut, tidak ditemukan adanya data duplikat, maka tidak ada juga proses penghapusannya.
Dropping Column with Low Correlation
Pada bagian ini adalah proses penghapusan fitur-fitur yang memiliki korelasi rendah terhadap variabel target dari dataset. Langkah ini diambil berdasarkan asumsi bahwa fitur dengan korelasi rendah tidak memberikan kontribusi signifikan terhadap prediksi yang dibuat oleh model.
Alasan: Tahapan ini perlu dilakukan karena fitur dengan korelasi rendah terhadap variabel target cenderung tidak memberikan informasi yang berguna untuk prediksi dan dapat menambahkan kebisingan yang tidak perlu ke dalam model. Dengan menghilangkan fitur-fitur ini, kita dapat mengurangi kompleksitas model, yang dapat membantu dalam mencegah overfitting dan mempercepat waktu pelatihan. Selain itu, model yang lebih sederhana dengan fitur yang lebih sedikit lebih mudah untuk diinterpretasikan, yang memungkinkan kita untuk lebih memahami bagaimana fitur-fitur tersebut mempengaruhi variabel target.
Berikut ini adalah proses penghapusan kolom dengan korelasi yang rendah:
Berikut ini adalah tampilan dataframe setelah penghapusan beberapa kolom:
Hardness Solids Chloramines Sulfate Organic Carbon Potability 204.890455 20791.31898 7.300212 368.516441 10.379783 0 129.422921 18630.057858 6.635246 NaN 15.180013 0 224.236259 19909.541732 9.275884 NaN 16.868637 0 214.373394 22018.417441 8.059332 356.886136 18.436524 0
Penghapusan kolom dengan korelasi rendah sudah berhasil dilakukan.
Handle Missing Value
Missing Value terjadi ketika variabel atau barus tertentu kekurangan titik data, sehingga menghasilkan informasi yang tidak lengkap. Nilai yang hilang dapat ditangani dengan berbagai cara seperti imputasi (mengisi nilai yang hilang dengan mean, median, modus, dll), atau penghapusan (menghilangkan baris atau kolom yang nilai hilang)
Alasan: Missing Value perlu ditangani karena jika dibiarkan dapat berpengaruh ke rendahnya akurasi model yang akan dibuat. Maka dari itu, penting untuk mengatasi missing value secara efisien untuk mendapatkan model Machine Learning yang baik juga.
Berikut ini adalah kode untuk mencari tahu kolom mana saja dan berapa jumlah missing value-nya:
Berikut ini adalah output-nya:
Berikut ini kode untuk menghapus baris data yang memiliki missing value:
Penanganan missing value sudah berhasil dilakukan.
Outliers Detection and Removal
Outliers adalah titik data yang secara signifikan berbeda dari sebagian besar data dalam kumpulan data. Outliers dapat muncul karena variasi dalam pengukuran atau mungkin menunjukkan kesalahan eksperimental; dalam beberapa kasus, outliers bisa juga menunjukkan variabilitas yang sebenarnya dalam data. Penting untuk menganalisis outliers karena mereka dapat memiliki pengaruh besar pada hasil analisis statistik.
Proses pembersihan outliers menggunakan metode IQR (Interquartile Range) melibatkan beberapa langkah:
Menghitung Kuartil: Tentukan kuartil pertama (Q1) dan kuartil ketiga (Q3) dari data. Kuartil ini membagi data menjadi empat bagian yang sama.
Menghitung IQR: Hitung IQR dengan mengurangi Q1 dari Q3: $$IQR=Q3−Q1$$
Menentukan Batas Outliers:
Batas bawah untuk outliers: $$Q1−1.5×IQR$$
Batas atas untuk outliers: $$Q3+1.5×IQR$$
Identifikasi Outliers: Data yang berada di luar batas bawah dan atas ini dianggap sebagai outliers.
Pembersihan Outliers yang teridentifikasi kemudian dapat dibersihkan dari dataset, baik dengan menghapusnya atau melakukan transformasi tertentu.
Alasan:Outliers perlu dideteksi dan dihapus karena jika dibiarkan dapat merusak hasil analisis statistik pada kumpulan data sehingga menghasilkan performa model yang kurang baik. Selain itu, Mendeteksi dan menghapus outlier dapat membantu meningkatkan performa model Machine Learning menjadi lebih baik.
Gambar 5a - Boxplots Outlier
Berikut ini adalah kode untuk menghapus outliers yang ada pada dataframe:
Penghapusan outliers sudah berhasil dilakukan.
Imbalance Data
Imbalance data adalah kondisi di mana kelas atau kategori dalam dataset tidak diwakili secara merata, dengan satu kelas mendominasi yang lain. Jika hal ini dibiarkan hingga proses pelatihan model dapat mengakibatkan bias pada model. Hal ini bisa diatasi dengan oversampling atau undersampling.
Alasan: Hal ini dapat menjadi masalah adalah karena imbalance data dapat menyebabkan model bias terhadap kelas mayoritas (lebih banyak) dan menghasilkan performa yang buruk pada kelas minoritas lebih sedikit)
Berikut ini adalah untuk memeriksa ada berapa baris data untuk masing-masing kelas pada kolom
'Potability':Berikut ini adalah hasilnya:
Dalam hal ini, perlunya dilakukannya undersampling terhadap kelas
'0' agar menyesuaikan jumlah baris datanya dengan kelas '1'Berikut ini adalah bagian untuk melakukan proses undersampling:
Berikut ini adalah untuk memeriksa ada berapa baris data untuk masing-masing kelas pada kolom
'Potability' setelah dilakukan undersampling:Berikut ini adalah hasil setelah dilakukannya undesampling:
Proses penyeimbangan dataset sudah berhasil dilakukan.
Train Test Split
Train Test Split adalah metode yang digunakan untuk membagi dataset menjadi dua bagian: satu untuk melatih model (training set) dan satu lagi untuk menguji model (testing set). Biasanya, data dibagi dengan proporsi tertentu, misalnya 80% untuk training dan 20% untuk testing.
Alasan: Proses ini dilakukan agar dapat mengevaluasi kinerja model secara objektif. Dengan memisahkan data uji, kita dapat mengukur seberapa baik model memprediksi data baru yang tidak pernah dilihat sebelumnya, yang merupakan indikator penting dari kemampuan generalisasi model.
Berikut adalah bagian untuk membagi dataset menjadi train set dan test set:
Berikut ini adalah bagian untuk memeriksa ada berapa baris data untuk train dan test pada dataframe variabel non-label:
Berikut ini adalah hasilnya:
Berikut ini adalah bagian untuk memeriksa ada berapa baris data untuk train dan test pada dataframe variabel label:
Berikut ini adalah hasilnya:
Train Test Split sudah berhasil dilakukan.Data Transformation
Data Transformation adalah proses mengubah data dari satu format atau struktur ke format atau struktur lainnya. Proses ini biasanya dari format sistem sumber menjadi yang dibutuhkan oleh sistem tujuan. Data Transformation dapat dilakukan dengan berbagai cara, seperti mengubah satuan ukuran data, mengubah distribusi data, atau mengubah bentuk data.
Alasan: Data Tranformasi perlu dilakukan karena dapat meningkatkan efisiensi dan meningkatkan kualitas data yang digunakan dalam pembuatan model Machine Learning.
Standardization
Standardisasi adalah proses mengubah data menjadi format yang lebih seragam dan dapat dibandingkan. Ini biasanya melibatkan pengurangan rata-rata (mean) dan pembagian dengan simpangan baku (standard deviation) untuk setiap fitur, sehingga fitur tersebut akan memiliki rata-rata nol dan varians satu.
Alasan: Standardisasi perlu dilakukan karena banyak algoritma machine learning yang berperforma lebih baik jika fitur-fitur berada pada skala yang sama. Standardisasi membantu dalam hal ini dengan memastikan bahwa setiap fitur berkontribusi secara proporsional ke hasil akhir dan menghindari bias terhadap fitur dengan skala yang lebih besar.
Berikut ini adalah penerapan standardisasinya:
Setelah dilakukannya standardisasinya, dapat kita cek hasilnya perubahannya dengan melihat mean dan standar deviasinya
Berikut ini adalah keadaan setelah dilakukan standardisasi:
Hardness Solids Chloramines Sulfate Organic_carbon count 354 354 354 354 354 mean 0 0 0 0 -0 std 1.0014 1.0014 1.0014 1.0014 1.0014 min -2.5788 -2.1347 -2.614 -2.6012 -2.8722 25% -0.5844 -0.7659 -0.6995 -0.6544 -0.6918 50% 0.0714 -0.1126 -0.0591 0.0374 -0.0836 75% 0.6127 0.7476 0.6919 0.6888 0.6359 max 2.6081 2.5987 2.6845 2.5396 2.7042
Standardisasi sudah berhasil dilakukan
Modelling
Pada bagian ini, data yang yang sudah dibagi menjadi dua bagian menjadi training dataset dan test dataset siap untuk digunakan untuk pembangunan model Machine Learning-nya. Untuk kasus ini, digunakan 3 (tiga) baseline model dari 3 algoritma yang berbeda. Berikut ini adalah ketiga algoritma tersebut:
Random Forest
Kelebihan
Akurasi tinggi
Dengan menggunakan banyak pohon keputusan, Random Forest dapat mencapai tingkat akurasi yang tinggi dalam klasifikasi dan regresi.
Dapat menangani data dengan dimensi tinggi
Mampu menangani masalah dengan sejumlah besar fitur dan data tanpa perlu pemilihan fitur.
Robust terhadap noise dan _outliers
Tidak mudah dipengaruhi oleh noise dan outliers karena menggunakan metode bagging dan ensemble.
Kekurangan
Mahal secara komputasi
Membutuhkan lebih banyak sumber daya komputasi karena melibatkan pembangunan banyak pohon.
Butuh waktu lebih lama
Proses pembelajaran dan prediksi bisa memakan waktu yang lama karena kompleksitas model.
Interpretabilitas
Sulit untuk diinterpretasikan dan dipahami karena kompleksitas dari banyak pohon keputusan.
KNN
Kelebihan
Sederhana dan Mudah Dipahami
Algoritma ini intuitif dan mudah diimplementasikan.
Non-parametric
Tidak membuat asumsi tentang distribusi data, cocok untuk data yang tidak normal.
Tidak perlu pelatihan
Tidak ada fase pelatihan yang eksplisit, yang berarti baru pada saat prediksi data diuji
Kekurangan
Sensitif terhadap outliers
Kinerja bisa terpengaruh oleh keberadaan outliers.
Mahal secara komputasi
Memerlukan perhitungan jarak dari setiap titik data ke titik lainnya, yang bisa sangat mahal secara komputasi.
Memerlukan pilihan K yang baik
Pemilihan jumlah tetangga (K) yang tepat sangat penting untuk kinerja algoritma.
SVM
Kelebihan
Efektif untuk data dengan dimensi tinggi
Bekerja dengan baik pada data yang memiliki banyak fitur.
Serbaguna
Kernel yang berbeda dapat digunakan untuk keputusan batas yang berbeda.
Robust
Tidak terlalu dipengaruhi oleh outliers dan mampu menghasilkan model yang optimal dengan margin yang maksimal.
Kekurangan
Sensitif terhadap pilihan Kernel
Pemilihan kernel yang tepat sangat penting dan bisa mempengaruhi kinerja model.
Membutuhkan penyetelan Hyperparameter
Penyetelan hyperparameter seperti C, gamma, dan kernel memerlukan waktu dan usaha.
Training Cost
Biaya pelatihan bisa tinggi, terutama untuk dataset yang besar.
Kemudian, baseline model dari ketiga algoritma tersebut yang memiliki akurasi tertinggi digunakan untuk ke tahap selanjutnya. Selanjutnya, algoritma tersebut digunakan kembali untuk pembangunan model, tetapi dengan memanfaatkan hyperparameter yang ada sehingga mendapatkan hasil terbaik. Untuk menemukan hyperparamter yang memberikan hasil terbaik,
GridSearch digunakan ke model yang terpilih.Berikut ini adalah hasil dari baseline model untuk ketiga model:
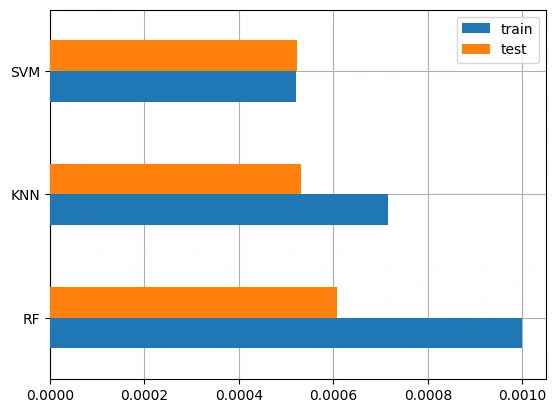
train test KNN 0.000716 0.000531 SVM 0.00052 0.000523 RF 0.001 0.000607
Gambar 6a - Baseline Model Train Test Results
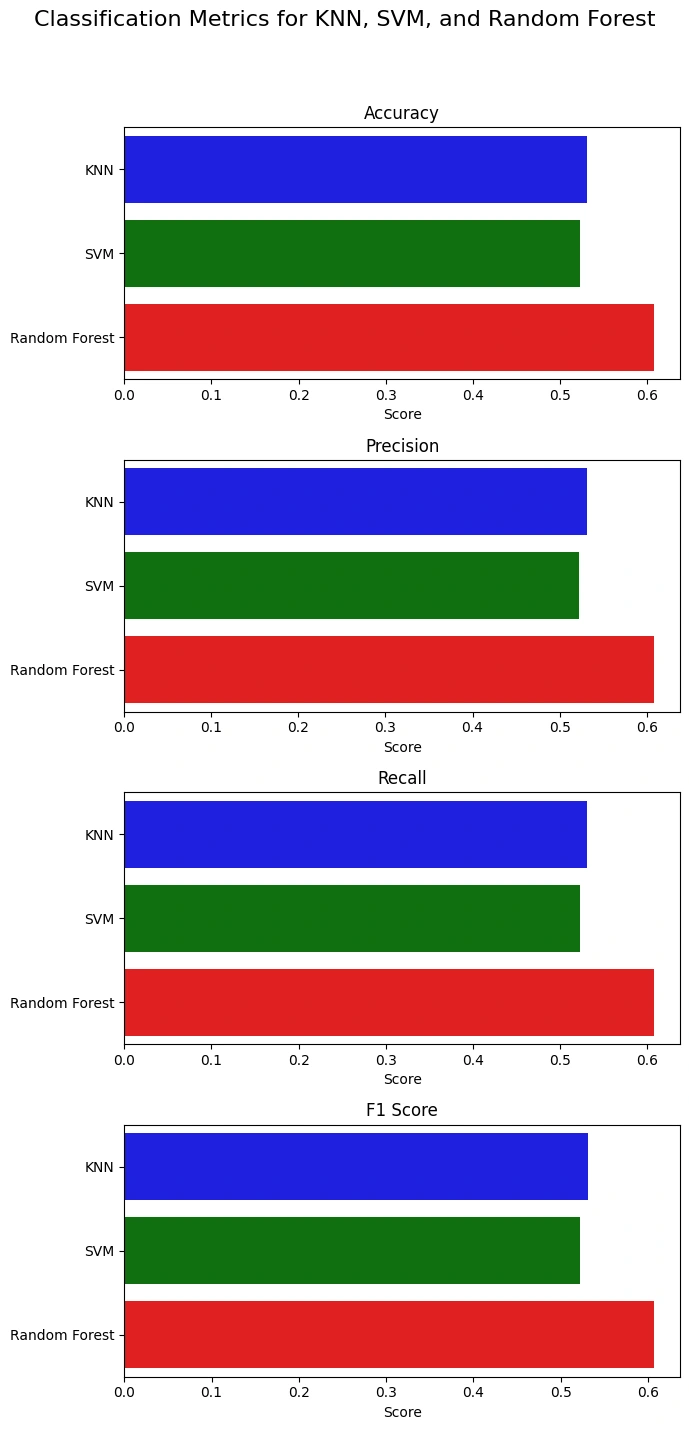
Gambar 6b - Baseline Model All Results
Model
Random Forest terpilih sebagai model yang akan digunakan lebih lanjut dengan hyperparamter tuning karena memiliki performa train dan test yang tertinggi dibandingkan dengan 2 model lainnya. Kemudian, hasil Accuracy, Precision, Recall, dan F1 Score dari Random Forest juga menunjukkan hasil yang terbaik.Berikut ini adalah proses improvement hyperparameter tuning menggunakan
GridSearch:Berikut ini adalah hasil dari grid search:
Berdasarkan hasil dari proses
GridSearch, kombinasi parameter yang terbaik adalah:max_depth: 10min_samples_leaf: 2min_samples_split: 5,n_estimators: 400Berikut ini adalah penjelasan dari keempat parameter tersebut:
max_depth: 10 Ini menentukan kedalaman maksimum pohon. Dalam kasus ini, pohon tidak akan tumbuh lebih dari 10 tingkat. Kedalaman yang lebih besar bisa meningkatkan keakuratan model tetapi juga meningkatkan risiko overfitting.min_samples_leaf: 2 Ini adalah jumlah sampel minimum yang diperlukan untuk menjadi daun pohon. Jadi, setiap daun harus memiliki setidaknya 2 sampel. Parameter ini membantu mengontrol overfitting dengan memastikan bahwa daun tidak terlalu spesifik hanya pada sampel pelatihan.min_samples_split: 5, Ini menunjukkan jumlah sampel minimum yang diperlukan untuk membagi simpul internal. Sebuah simpul akan dibagi jika memiliki 5 atau lebih sampel. Ini juga membantu mencegah overfitting dengan memastikan bahwa pembagian tidak terlalu spesifik.n_estimators: 400 Ini menunjukkan jumlah pohon dalam forest. Di sini, model akan menggunakan 400 pohon. Biasanya, semakin banyak pohon, semakin stabil prediksi model, tetapi juga akan membutuhkan lebih banyak waktu komputasi dan memori.Hasil dari
GridSearc tersebut digunakan sebagai hyperparameter pembangunan model.Evaluation
Ketika model sudah dibangun dan sudah melakukan uji dengan data test, perlu dilakukan evaluasi untuk melihat performa dari model tersebut. Untuk melakukan proses evaluasi model klasifikasi biner digunakan metrik
Accuracy, Precision, Recall, dan F1 Score dari Confusion Matrix.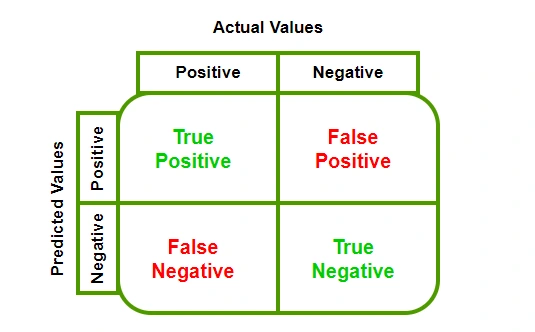
Gambar 7a - Confusion Matrix
Confusion Matrix adalah tabel yang digunakan untuk mengevaluasi performa model klasifikasi. Ini adalah tabel yang menunjukkan jumlah prediksi yang benar dan salah yang dibuat oleh model dengan membaginya ke dalam empat kategori:
True Positives (TP):
Ini adalah kasus-kasus di mana model dengan benar mengidentifikasi kelas positif. Misalnya, dalam konteks klasifikasi air ketika air yang layak minum dan model juga meprediksi hal yang sama.
True Negatives (TN):
Ini adalah kasus-kasus di mana model dengan benar mengidentifikasi kelas negatif. Menggunakan contoh yang sama, ini ketika air yang tidak layak minum dan model juga meprediksi hal yang sama.
False Positives (FP):
Dikenal juga sebagai ‘Type I error’, ini adalah kasus-kasus di mana model salah mengidentifikasi kelas negatif sebagai positif. Dalam konteks klasifikasi air ketika air yang tidak layak minum, tetapi model memprediksikan bahwa air tersrbut layak minum.
False Negatives (FN):
Dikenal juga sebagai ‘Type II error’, ini adalah kasus-kasus di mana model salah mengidentifikasi kelas positif sebagai negatif. Dalam konteks klasifikasi air ketika air yang layak minum, tetapi model memprediksikan bahwa air tersebut tidak layak minum.
Kemudian, berikut ini terkait
Accuracy, Precision, Recall, dan F1 Score dan cara kerjanya:Accuracy$$Accuracy = TP + TN / TP + TN + FP + FN$$
Akurasi adalah ukuran seberapa sering prediksi model benar dan dihitung sebagai jumlah prediksi yang benar dibagi dengan jumlah total prediksi. Akurasi memberikan informasi umum tentang performa model di semua kelas.
Precision$$Precision = TP / TP + FP$$
Precision mengukur proporsi prediksi positif yang benar-benar positif dan dihitung sebagai jumlah True Positives dibagi dengan jumlah True Positives dan False Positives. Precision penting ketika kita ingin meminimalisir False Positives
Recall$$Recall = TP / TP + FN$$
Recall mengukur proporsi positif aktual yang diidentifikasi dengan benar dan dihitung sebagai jumlah True Positives dibagi dengan jumlah True Positives dan False Negatives. Recall penting ketika biaya dari False Negative tinggi, seperti di kasus medis atau keamanan.
F1 Score$$F1 Score = Precision . Recall / Precision + Recall$$
F1 Score adalah rata-rata harmonik dari presisi dan recall, memberikan keseimbangan antara keduanya, terutama ketika ada distribusi kelas yang tidak seimbang. F1 Score berguna ketika kita membutuhkan keseimbangan antara presisi dan recall, dan ketika distribusi kelas tidak seimbang.
Berikut ini adalah hasil evaluasi model menggunakan metrik
Accuracy, Precision, Recall, dan F1 Score dari Confusion Matrix:Berikut ini adalah
Accuracy dengan menggunakan dataset test:Berikut ini adalah hasilnya:
Hasil diatas menujukkan bahwa
Accuracy model menggunakan dataset test sebesar 61%. Hasilnya lebih besar dibandingkan dengan baseline model dari Random Forest tanpa hyperparameter tuning.Berikut ini adalah Visualisasi dari
Confusin Matrix: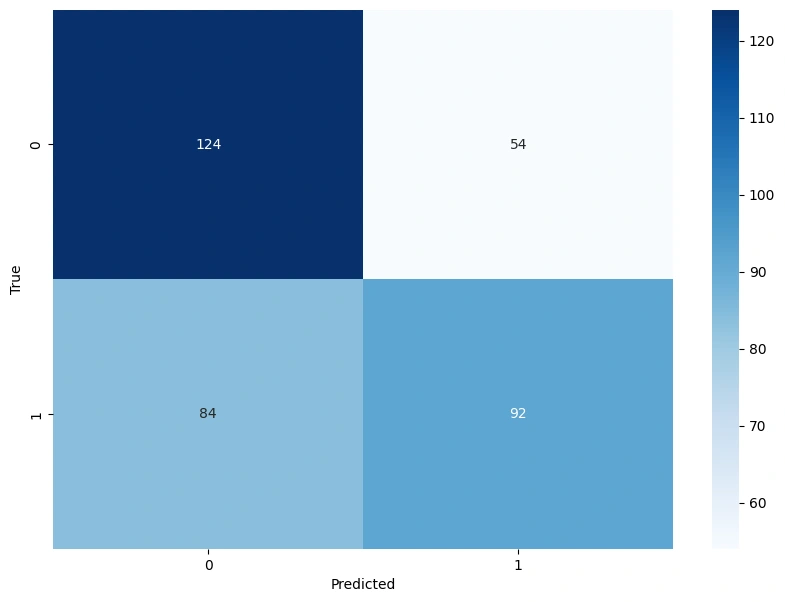
Gambar 7b - Confusion Matrix Results
Berdasarkan visualisasi data diatas, hasilnya dapat dirincikan sebagai berikut:
True Positive (TP): 124
True Negative (TN): 92
False Positive (FP): 84
False Negative (FN): 54
Berikut ini adalah laporan lengkap terkait evaluasi model dengan metrik lainnya yang juga digunakan:
Berikut ini adalah hasil dari kode diatas:
Berdasarkan output diatas, berikut ini adalah hasil akhir dari model yang dibangun dengan algoritma
Random Forest dengan hyperparameter tuning:Accuracy : 0.61Precision: 0.61Recall: 0.61F1-Score: 0.61Referensi
[1] Z. Ab, Ismail Efendy, D. Syamsul, and I. wati, “FAKTOR YANG BERHUBUNGAN TINGKAT KONSUMSI AIR BERSIH PADA RUMAH TANGGA DI KECAMATAN PEUDADA KABUPATEN BIREUN,” vol. 7, no. 2, Nov. 2019, doi: https://doi.org/10.32672/jbe.v7i2.1592.
[2] M. Mititelu et al., “Water, the indispensable component for the health and functioning of the human body,” Farmacist.ro, vol. 1, no. 210, pp. 30–30, Jan. 2023, doi: https://doi.org/10.26416/farm.210.1.2023.7760.
[3] B. Fairchild and C. Ritz, “Poultry Drinking Water Primer.” Available: https://secure.caes.uga.edu/extension/publications/files/pdf/B%201301_4.PDF
[4] R. Salim and T. Taslim, “EDUKASI MANFAAT AIR MINERAL PADA TUBUH BAGI ANAK SEKOLAH DASAR SECARA ONLINE,” JPKM, vol. 27, no. 2, Mar. 2021.
[5] A. Buanasita, A. Yanto, and I. Sulistyowati, “Perbedaan Tingkat Konsumsi Energi, Lemak, Cairan, dan Status Hidrasi Mahasiswa Obesitas dan Non Obesitas,” Indonesian Journal of Human Nutrition, vol. 2, no. 1, pp. 11–22, Jun. 2015, doi: https://doi.org/10.21776/ub.ijhn.2015.002.01.2.
[6] Mega Fia Lestari, Muhammad Ilham Al’Wahid, Muhammad, None Yusriadi, Baiq Amelia Riyandari, and Devi Nur Anisa, “Analysis of mineral water quality based on SNI 3553:2015 and its consequences from legal perspectives,” IOP Conference Series: Earth and Environmental Science, vol. 1190, no. 1, pp. 012041–012041, Jun. 2023, doi: https://doi.org/10.1088/1755-1315/1190/1/012041.
[7] “Riset: 74,4% Sumber Air Minum Rumah Tangga RI Tercemar Tinja,” dataindonesia.id. https://dataindonesia.id/kesehatan/detail/riset-744-sumber-air-minum-rumah-tangga-ri-tercemar-tinja (accessed Mar. 05, 2024).
[8] E. B. Sasongko, E. Widyastuti, and R. E. Priyono, “KAJIAN KUALITAS AIR DAN PENGGUNAAN SUMUR GALI OLEH MASYARAKAT DI SEKITAR SUNGAI KALIYASA KABUPATEN CILACAP,” Jurnal Ilmu Lingkungan, vol. 12, no. 2, p. 72, Oct. 2014, doi: https://doi.org/10.14710/jil.12.2.72-82.
[9] Generosa Lukhayu Pritalia, “Analisis Komparatif Algoritme Machine Learning dan Penanganan Imbalanced Data pada Klasifikasi Kualitas Air Layak Minum,” KONSTELASI: Konvergensi Teknologi dan Sistem Informasi, vol. 2, no. 1, Apr. 2022, doi: https://doi.org/10.24002/konstelasi.v2i1.5630.
[10] I. Fitriyaningsih, Y. Basani, and L. M. Ginting, “MACHINE LEARNING: PROSPERITY OF RAINFALL, WATER DISCHARGE, AND FLOOD WITH WEB APPLICATION IN DELI SERDANG,” JURNAL PENELITIAN KOMUNIKASI DAN OPINI PUBLIK, vol. 22, no. 2, Dec. 2018, doi: https://doi.org/10.33299/jpkop.22.2.1752.
[11] K Abirami, P. Radhakrishna, and M. Venkatesan, “Water Quality Analysis and Prediction using Machine Learning,” Apr. 2023, doi: https://doi.org/10.1109/csnt57126.2023.10134661.
[12] S. Iyer, S. Kaushik, and Poonam Nandal, “Water Quality Prediction Using Machine Learning,” MR International Journal of Engineering and Technology, vol. 10, no. 1, pp. 59–62, May 2023, doi: https://doi.org/10.58864/mrijet.2023.10.1.8.
Like this project
Posted Jul 14, 2025
Developed a machine learning model for classifying drinking water quality.