Streaming Platform Recommendation System Development
Faisal Ahmad Gifari
Laporan Proyek Machine Learning - Faisal Ahmad Gifari
Project Overview
Platform streaming film telah menjadi bagian integral dari hiburan saat ini. Dengan akses internet yang semakin luas, platform-platform tersebut memberikan kemudahan bagi penggunanya dalam menikmati berbagai film dari seluruh dunia. Adanya platform streaming memungkinkan penonton untuk memilih konten yang ingin ditonton kapan saja dan di mana saja[1]. Hal ini memberikan fleksibilitas yang tidak dapat ditawarkan oleh bioskop atau televisi tradisional. Namun, untuk meningkatkan pengalaman pengguna dalam menggunakan layanan tersebut juga perlu diperhatikan. Jika dibiarkan, penonton bisa saja tidak ingin lagi menggunakan layanan platform streaming tersebut atau memberhentikan langganannya. Maka dari itu, salah satu solusi dari masalah ini adalah pembuatan sistem rekomendasi.
Salah satu contoh nyata efektivitas sistem rekomendasi adalah keberhasilan Netflix dalam mempertahankan dan meningkatkan basis pelanggannya. Dengan menggunakan sistem rekomendasi yang canggih, Netflix dapat menganalisis preferensi pemirsa dan perilaku menonton untuk memberikan saran film dan acara TV yang relevan[2]. Hasilnya, sekitar 75% tontonan di Netflix berasal dari rekomendasi sistem. Hal ini menunjukkan betapa pentingnya sistem rekomendasi dalam membantu pengguna menemukan konten yang mereka sukai, yang pada akhirnya meningkatkan kepuasan dan loyalitas pengguna terhadap platform
Sistem rekomendasi telah terbukti menjadi salah satu bagian utama yang meningkatkan pengalaman pengguna di platform streaming[3]. Sistem menggunakan algoritma untuk menganalisis preferensi pengguna dan memberikan saran film yang relevan[4]. Sistem rekomendasi memberikan dampak yang signifikan bagi pengguna atau penonton karena membantu pengguna menemukan film yang sesuai dengan seleranya tanpa harus mencari terlebih dahulu, sehingga meningkatkan kepuasan pengguna dan potensi waktu menonton.
Ada beberapa pendekatan yang dapat digunakan dalam membuat model sistem rekomendasi film. Pendekatan berbasis konten memanfaatkan fitur-fitur seperti genre untuk merekomendasikan film serupa [5]. Sementara itu, pendekatan pemfilteran kolaboratif mengumpulkan dan menganalisis data dari banyak pengguna untuk menemukan pola dan preferensi bersama[6]. Perkembangan model ini terus berkembang seiring dengan kemajuan teknologi dan analisis data.
Business Understanding
Pengguna dari platform streaming film dapat berhenti menggunakan sebuah layanan streaming film jika pengalaman yang didapatkannya tidak begitu baik. Salah satu untuk meningkatkan pengalaman pengguna paltform streaming film adalah dengan adanya sistem rekomendasi agar penonton bisa mendapatkan konten yang sesuai dengan preferensinya atau riwayat tontonannya. Ada beberapa pendekatan yang dapat digunakan untuk membangun model sistem rekomendasi. Salah satunya adalah sistem rekomendasi dengan content-based learning yang memberikan rekomendasi berdasarkan item serupa. Kemudian, sistem rekomendasi dengan collaborative filtering yang bekerja dengan cara mengumpulkan dan menganalisis data dari banyak pengguna untuk menemukan pola dan preferensi secara kolektif. Dengan adanya sistem rekomendasi pada platfom streaming film, pengguna dapat mendapatkan pengalaman pengguna yang baik.
Problem Statements
Bagaimana memahami dan mengetahui terkait data dari dataset digunakan untuk pembuatan model sistem rekomendasi?
Bagaimana membuat model sistem rekomendasi dengan pendekatan content-based filtering?
Bagaimana membuat model sistem rekomendasi dengan pendekatan collaborative filtering?
Bagaimana cara mengukur performa model sistem rekomendasi yang sudah dibuat?
Goals
Melakukan langkah-langkah untuk memahami dataset terlebih dahulu, seperti EDA dan Visualisasi Data.
Membuat sistem rekomendasi film dengan content-based filtering.
Membuat sistem rekomendasi film dengan collaborative filtering.
Melakukan evaluasi terhadap model sistem rekomendasi yang telat dibuat.
Solution Approach
Melakukan EDA untuk mengeksplorasi fitur menggunakan fungsi
shape, key, info pada dataset. Kemudian, dilakukan visualisasi data seperti count plot dan pie chart untuk mendapatkan gambaran atau ilustrasu lebih jelas mengenai dataset yang digunakan.Membangun sistem rekomendasi dengan
content-based filtering yang memberikan rekomendasi kepada pengguna berdasarkan kesamaan pada item yang ada. Data yang digunakan berisi data dari genre dari setiap film. Dataset tersebut juga melewati tahap Data Preparation agar dataset dapat digunakan untuk proses pembangunan model seperti, menangani data duplikat, missing value, dan mengganti beberapa data agar sesuai. Kemudian, data yang sudah siap, diproses ke tahap modelling yang memanfaatkan Tfidvectorizer, cosine similarity, dan fungsi buatan yang mengembalikan rekomendasi berdasarkan kesamaan pada item. Pendekatan ini berfokus pada karakteristik atau konten dari item yang direkomendasikanMembangun sistem rekomendasi dengan
collaborative filtering yang memberikan rekomendasi kepada pengguna dengan menganalisis perilaku dan preferensi pengguna. Data yang digunakan berisi data review untuk film-film dari user. Dataset tersebut juga melewati tahap Data Preparation agar dataset dapat digunakan untuk proses pembangunan model seperti, menangani data duplikat, missing value, encoding, dan train test split. Kemudian, data yang sudah siap, diproses ke tahap modelling yang menggunakan RecommenderNet dan Early Stopper dalam proses training-nya. Pendekatan ini membutuhkan data terkait user.Melakukan perhitungan skor presisi untuk mengukur performa dari model sistem rekomendasi film dengan content-based learning. Kemudian, menggunakan skor RMSE atau root mean squared error untuk mengukur performa dari model sistem rekomendasi film dengan colaborative filtering.
Data Understanding
Dataset yang digunakan untuk pembuatan model system recommendation ini adalah dataset "MovieLens Latest" yang tersedia di situs grouplens yang berisi data-data mengenai film-film beserta rating yang diberikan oleh para pengguna. Dataset ini terakhir di-update pada September 2018
Terdapat banyak file didalamnya, tetapi yang digunakan hanya dataset
movie.csv dan rating.csv. movie.csv terdiri dari 9078 baris data dan 3 kolom data. Kemudian, rating.csv terdiri dari 100836 baris data dan 4 kolom data.Kedua dataset tersebut dapat digunakan untuk membuat system recommendation, baik
Content-Based Filtering maupun Collaborative FilteringDataset tersebut dapat diunduh disini
Berikut ini adalah infomasi lainnya mengenai atribut-atribut yang terdapat pada dua dataset tersebut:
Atribut-atribut pada
movie.csv:movieId: Id filmtitle: Judul filmgenres: Genre filmAtribut-atribut pada
rating.csv :userId: Id usermovieId: Id filmrating: Skor rating yang sebuah filmtimestamp: Waktu kapan film diberikan skor ratingDataset
movie.csv ditampung dalam variabel movie_dfDataset
rating.csv ditampung dalam variabel review_dfExploratory Data Analysis
Exploratory Data Analysis (EDA) adalah pendekatan analisis data yang bertujuan untuk memahami karakteristik utama dari kumpulan data. EDA melibatkan penggunaan teknik statistik dan visualisasi grafis untuk menemukan pola, hubungan, atau anomali untuk membentuk hipotesis. Proses ini sering kali tidak terstruktur dan dianggap sebagai langkah awal penting dalam analisis data yang membantu menentukan arah analisis lebih lanjut.
Berikut ini adalah EDA yang dilakukan untuk
movie_df:9742 baris data
3 kolom data
movieIdtitlegenresmovieId = int64title = objectgenres = objectMasih ada beberapa tindakan yang perlu dilakukan untuk
movie_df. Proses pembersihan dan persiapan dataset akan dikerjakan lebih lanjut pada tahap selanjutnya.Berikut ini adalah EDA yang dilakukan untuk
review_df:100836 baris data
4 kolom data
userIdmovieIdreviewtimestampuserId = int64movieId = int64review = float64timestamp = int64count : Jumlah data dari sebuah kolommean : Rata-rata dari sebuah kolomstd : Standar deviasi dari sebuah kolommin : Nilai terendah pada sebuah kolom25% : Nilai kuartil pertama (Q1) dari sebuah kolom50% : Nilai kuartil kedua (Q2) atau median atau nilai tengah dari sebuah kolom75% : Nilai kuartil ketiha (Q3) dari sebuah kolommax : Nilai tertinggi pada sebuah kolom Walaupun kolom selain review ada yang tetap bisa diproses menggunakan fungsi describe() karena bertipe data int64 dan float64, tetapi yang benar-benar kolom numerik hanyalah kolom review.Visualisasi Data
Visualisasi Data untuk
movie_df:Univariate Analysis
Univariate Analysis adalah jenis analisis data yang memeriksa satu variabel (atau bidang data) pada satu waktu. Tujuannya adalah untuk menggambarkan data dan menemukan pola yang ada dalam distribusi variabel tersebut. Ini termasuk penggunaan statistik deskriptif, histogram, dan box plots untuk menganalisis distribusi dan memahami sifat dari variabel tersebut.
Count Plot dari setiap Genre
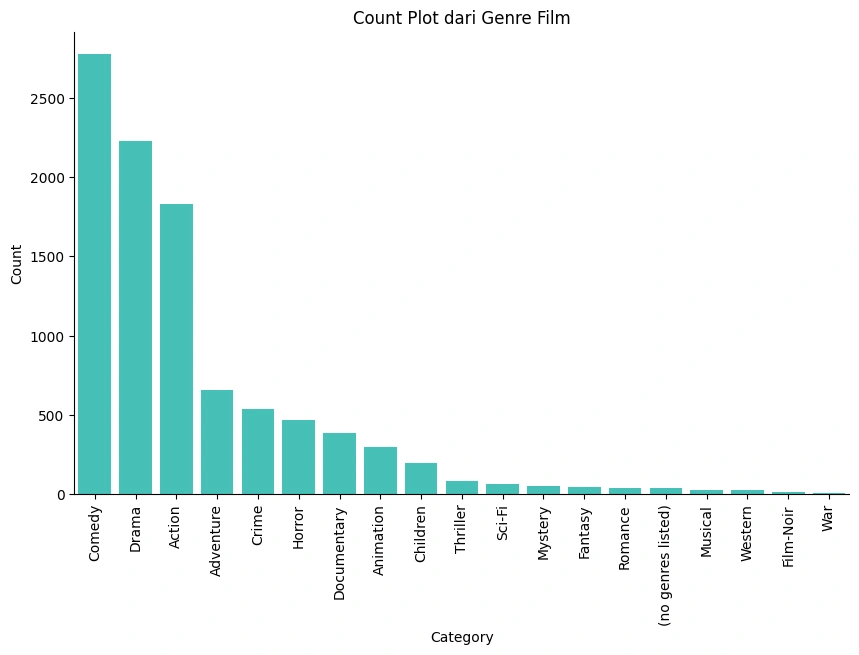
Gambar 1a - Count Plot Genre
Pie Chart dari Genre
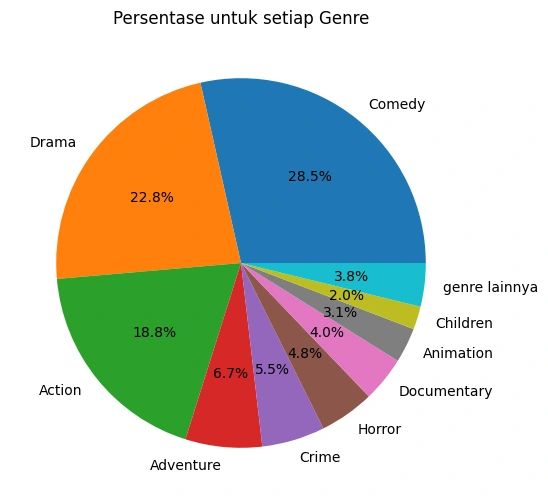
Gambar 1b - Pie Chart Genre
Berdasarkan kedua visualisasi data diatas, terlihat bahwa genre
Comedy, Drama, dan Action memiliki proporsi dan jumlah terbesar secara keseluruhan dibandingkan genre lainnya pada `movie_dfVisualisasi Data untuk
review_df:Univariate Analysis
Univariate Analysis adalah jenis analisis data yang memeriksa satu variabel (atau bidang data) pada satu waktu. Tujuannya adalah untuk menggambarkan data dan menemukan pola yang ada dalam distribusi variabel tersebut. Ini termasuk penggunaan statistik deskriptif, histogram, dan box plots untuk menganalisis distribusi dan memahami sifat dari variabel tersebut.
Count Plot dari Setiap Nilai Review
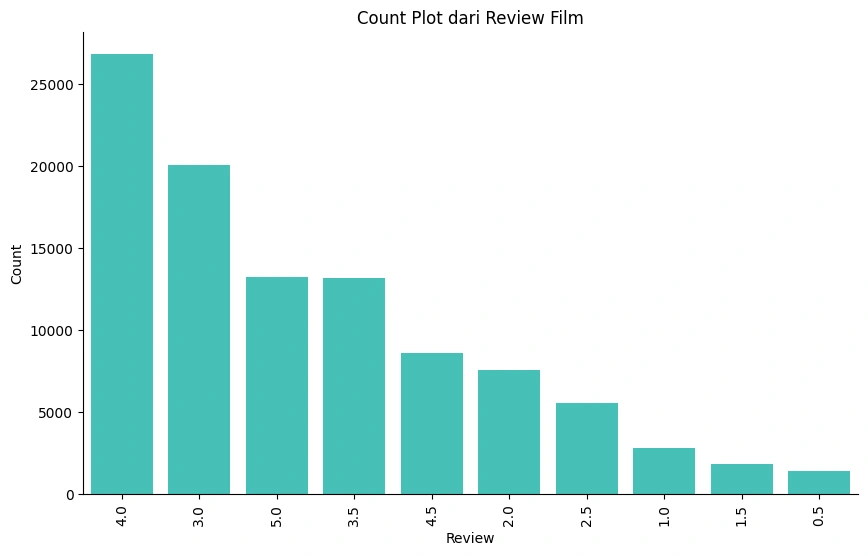
Gambar 1c - Count Plot Review
Pie Chart dari Review
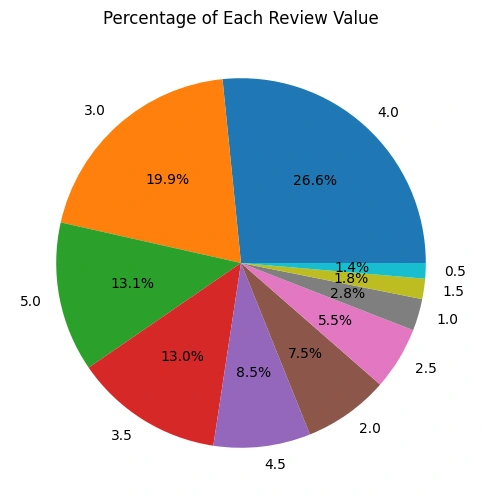
Gambar 1d - Pie Chart Genre
Berdasarkan visualisasi data diatas, terlihat bahwa review dengan skor
4.0 dan 3.0 memiliki proporsi dan jumlah terbesar secara keseluruhan dibandingkan skor lainnya pada review_df.Top 10 Movie dengan Review Terbanyak
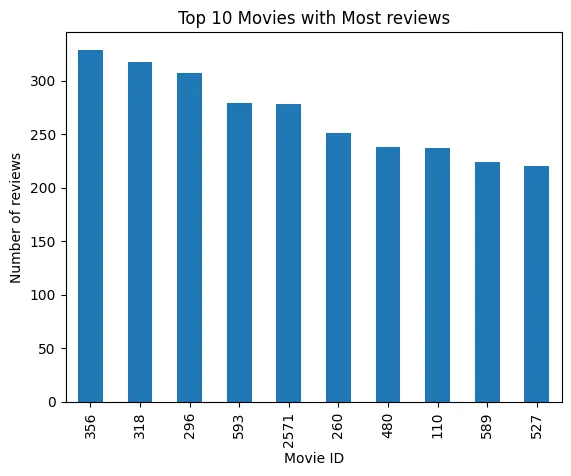
Gambar 1e - Top 10 Most Review Movie
Berdasarkan visualisasi data diatas, berikut adalah daftar
movieId dengan review terbanyak pada dataset review_df.Berikut adalah hasilnya:
10 film dengan
movieId diatas memiliki review terbanyak pada dataset.Data Preparation
Data Preparation adalah proses pembersihan, transformasi, dan pengorganisasian data mentah ke dalam format yang dapat dipahami oleh algoritma machine learning. Bagian ini menjelaskan urutan langkah-langkah Data Preparation yang dilakukan beserta penjelasan dan alasannya untuk setiap dataset.
Berikut ini adalah Data Preparation untuk
movie_df:Detection and Removal Duplicates
Data duplikat adalah baris data yang sama persis untuk setiap variabel yang ada. Dataset yang digunakan perlu diperiksa juga apakah dataset memiliki data yang sama atau data duplikat. Jika ada, maka data tersebut harus ditangani dengan menghapus data duplikat tersebut.
Alasan: Data duplikat perlu didektesi dan dihapus karena jika dibiarkan pada dataset dapat membuat model Anda memiliki bias, sehingga menyebabkan overfitting. Dengan kata lain, model memiliki performa akurasi yang baik pada data pelatihan, tetapi buruk pada data baru. Menghapus data duplikat dapat membantu memastikan bahwa model Anda dapat menemukan pola yang ada lebih baik lagi.
Berikut ini proses pendeteksian dan penghapusan nilai duplikat:
Berikut adalah output-nya:
Berdasarkan hasil tersebut, tidak ditemukan adanya data duplikat, maka tidak ada juga proses penghapusannya.
Handle Missing Value
Missing Value terjadi ketika variabel atau barus tertentu kekurangan titik data, sehingga menghasilkan informasi yang tidak lengkap. Nilai yang hilang dapat ditangani dengan berbagai cara seperti imputasi (mengisi nilai yang hilang dengan mean, median, modus, dll), atau penghapusan (menghilangkan baris atau kolom yang nilai hilang)
Alasan: Missing Value perlu ditangani karena jika dibiarkan dapat berpengaruh ke rendahnya akurasi model yang akan dibuat. Maka dari itu, penting untuk mengatasi missing value secara efisien untuk mendapatkan model Machine Learning yang baik juga.
Berikut ini adalah kode untuk mencari tahu kolom mana saja dan berapa jumlah missing value-nya:
Berikut adalah output-nya:
Berdasarkan output diatas, tidak adanya missing value pada
movie_dfDelete Some Data Point
Pada sebuah dataset, ada saatnya beberapa baris data atau kolom perlu dihapus karena satu dan lain hal. Salah satunya agar tidak menghambat proses training dan performa dari sebuah model yang akan dibangun. Ada value pada dataset
movie_df, khususnya kolom genre, yang perlu dihapus karena nama nilainya itu sendiri, yaitu `(no genres listed)'.Alasan: Hal ini perlu dilakukan karena nilai tersebut tidak mewakili genre apapun untuk sebuah film. Jika dibiarkan, ini dapat mempengaruhi performa model yang akan dibuat. Maka dari itu, baris data yang memiliki nilai ini, perlu dihapus
Berikut adalah kodenya untuk menghapus beberapa baris data yang perlu dihapus:
Berikut adalah output-nya:
Berdasarkan output diatas,
(no genres listed) terbukti sudah tidak ada lagi pada datasetAdapun tahap selanjutnya, yaitu penghapusan baris data yang hanya ada kurang dari 6 data point:
Berikut ini adalah kodenya:
Berikut adalah output-nya:
Berdasarkan output diatas,
War pada kolom genre hanya memiliki 4 data point. Dalam kasus ini, value yang kurang dari 6 data dalam dataset perlu dihilangkana karena tidak dapat digunakan. Hal ini akan ditindak lebih lanjut pada bagian selanjutnya.Berikut ini adalah kodenya:
Berhasil dilakukannya penghapusan data point pada kolon
genre yang bernilai WarChanging Certain Value
Pada sebuah dataset, ada kalanya beberapa nilai perlu diproses terlebih dahulu agar proses training atau pembuatan model dapat berjalan seperti seharusnya. Salah satunya adalah pengubahan beberapa nilai yang dirasa akan mengganggu jika dibiarkan. Ada value pada dataset
movie_df, khususnya kolom genre, yang perlu diganti namanya, yaitu Sci-Fi dan Film-Noir.Alasan: Hal ini perlu dilakukan karena jika dibiarkan ketika proses embedding akan terdeteksi sebagai 2 bagian yang berbeda. Maka dari itu, string dari kedua nilai tersebut harus dimodifikasi agar pada saat proses encoding tidak terpecah menjadi 2 bagian berbeda.
Berikut ini adalah proses pengubahan beberapa nilai tertentu:
Nilai
Sci-Fi dan Film-Noir sudah berhasil diubah dengan menghilangkan tanda - pada kedua nilai tersebut. Maka dari itu, nilai tersebut sudah siap untuk diproses pada tahap selanjutnya.Berikut adalah kode untuk mengecek proses perubahan:
Berikut ini adalah output-nya:
Berdasarkan output diatas, dapat dilihat bahwa sudah terlihat nilai yang baru saja diubah, yaitu
SciFi dan FilmNoirSetelah beberapa proses yang sudah dilakukan, maka
movie_df masih memiliki:Outputnya:
Setelah beberapa proses yang sudah dilakukan, maka
movie_df masih memiliki:9708 baris data
3 kolom data
Berikut ini adalah Data Preparation untuk
review_df :Detection and Removal Duplicates
Data duplikat adalah baris data yang sama persis untuk setiap variabel yang ada. Dataset yang digunakan perlu diperiksa juga apakah dataset memiliki data yang sama atau data duplikat. Jika ada, maka data tersebut harus ditangani dengan menghapus data duplikat tersebut.
Alasan: Data duplikat perlu didektesi dan dihapus karena jika dibiarkan pada dataset dapat membuat model Anda memiliki bias, sehingga menyebabkan overfitting. Dengan kata lain, model memiliki performa akurasi yang baik pada data pelatihan, tetapi buruk pada data baru. Menghapus data duplikat dapat membantu memastikan bahwa model Anda dapat menemukan pola yang ada lebih baik lagi.
Berikut ini adalah proses pendeteksian dan penghapusan data duplikatnya:
Output-nya:
Berdasarkan hasil tersebut, tidak ditemukan adanya data duplikat, maka tidak ada juga proses penghapusannya.
Handle Missing Value
Missing Value terjadi ketika variabel atau barus tertentu kekurangan titik data, sehingga menghasilkan informasi yang tidak lengkap. Nilai yang hilang dapat ditangani dengan berbagai cara seperti imputasi (mengisi nilai yang hilang dengan mean, median, modus, dll), atau penghapusan (menghilangkan baris atau kolom yang nilai hilang)
Alasan: Missing Value perlu ditangani karena jika dibiarkan dapat berpengaruh ke rendahnya akurasi model yang akan dibuat. Maka dari itu, penting untuk mengatasi missing value secara efisien untuk mendapatkan model Machine Learning yang baik juga.
Berikut ini adalah kode untuk mencari tahu kolom mana saja dan berapa jumlah missing value-nya:
Output-nya :
Berdasarkan output diatas, tidak adanya missing value pada
review_df. Maka, tidak perlu dilakukan pengisian pada data hilang.Outliers Detection and Removal
Outliers adalah titik data yang secara signifikan berbeda dari sebagian besar data dalam kumpulan data. Outliers dapat muncul karena variasi dalam pengukuran atau mungkin menunjukkan kesalahan eksperimental; dalam beberapa kasus, outliers bisa juga menunjukkan variabilitas yang sebenarnya dalam data. Penting untuk menganalisis outliers karena mereka dapat memiliki pengaruh besar pada hasil analisis statistik.
Outliers adalah titik data yang secara signifikan berbeda dari sebagian besar data dalam kumpulan data. Outliers dapat muncul karena variasi dalam pengukuran atau mungkin menunjukkan kesalahan eksperimental; dalam beberapa kasus, outliers bisa juga menunjukkan variabilitas yang sebenarnya dalam data. Penting untuk menganalisis outliers karena mereka dapat memiliki pengaruh besar pada hasil analisis statistik.
Proses pembersihan outliers menggunakan metode IQR (Interquartile Range) melibatkan beberapa langkah:
Menghitung Kuartil: Tentukan kuartil pertama (Q1) dan kuartil ketiga (Q3) dari data. Kuartil ini membagi data menjadi empat bagian yang sama.
Menghitung IQR: Hitung IQR dengan mengurangi Q1 dari Q3: $$IQR=Q3−Q1$$
Menentukan Batas Outliers:
Batas bawah untuk outliers: $$Q1−1.5×IQR$$
Batas atas untuk outliers: $$Q3+1.5×IQR$$
Identifikasi Outliers: Data yang berada di luar batas bawah dan atas ini dianggap sebagai outliers.
Pembersihan Outliers yang teridentifikasi kemudian dapat dibersihkan dari dataset, baik dengan menghapusnya atau melakukan transformasi tertentu.
Alasan:Outliers perlu dideteksi dan dihapus karena jika dibiarkan dapat merusak hasil analisis statistik pada kumpulan data sehingga menghasilkan performa model yang kurang baik. Selain itu, Mendeteksi dan menghapus outlier dapat membantu meningkatkan performa model Machine Learning menjadi lebih baik.
Berikut ini adalah salah satu cara mendeteksi adanya outliers atau tidak:
Output-nya:
Sebelum memulai dengan proses interquartile. Perlu dilihat terlebih dahulu secara sekilas secara statistika deskriptif.
Hanya kolom
review yang dicek karena hanya kolom tersebut yang tergolong sebagai kolom numeric dan perlu dilakukan pemeriksaan outliers-nya.Berdasarkan output diatas, terlihbat bahwa nilai terkecil dari
review adalah 0.5 dan terbesarnya adalah 5.0. Kedua nilai tersebut masih di ambang wajar untuk sebuah review film. Jadi, tidak ada outliers dan tidak ada penghapus outliers untuk kolom reviewDropping Uneeded Column
Pada bagian ini adalah proses penghapusan kolom yang tidak digunakan untuk proses pembuatan model. Langkah ini diambil berdasarkan asumsi bahwa kolom yang akan dihapus tidak memberikan kontribusi terhadap prediksi yang dibuat oleh model.
Alasan: Tahapan ini perlu dilakukan karena kolom yang tidak digunakan cenderung tidak memberikan informasi yang berguna untuk prediksi dan dapat menambah informasi yang tidak perlu ke dalam model. Dengan menghilangkan fitur-fitur ini, kita dapat mengurangi kompleksitas model dan mempercepat waktu pelatihan.
Berikut ini adalah proses penghapusan kolom yang tidak diperlukan atau digunakan:
Kolom
timestamp telah berhasil dihapus. Kolom tersebut dihapus karena tidak diperlukan untuk proses pembuatan sistem rekomendasi secara collaborative filtering.Berikut dilakukan pengecekan ukuran dari
review_df:Output-nya:
Berdasarkan output tersebut, maka
review_df masih memiliki:100836 baris data
3 kolom data
Encoding
Encoding adalah proses konversi informasi dari satu bentuk atau format ke bentuk lain, yang sering kali dilakukan untuk memastikan kompatibilitas dan pemrosesan yang tepat oleh berbagai sistem komputer. Proses ini sangat penting dalam dunia digital, di mana berbagai jenis data, seperti teks, gambar, dan suara, harus diubah menjadi format yang dapat dipahami oleh perangkat keras dan perangkat lunak.
Alasan: Tahap ini perlu dilakukan karena Encoding memungkinkan data dari berbagai sumber dan format untuk diubah menjadi format standar yang dapat dipahami dan memastikan bahwa informasi dapat diproses
Berikut ini adalah proses dari encoding yang dilakukan:
Encoding
userIdEncoding
userId berhasil dilakukan. Output tersedia di notebook dan tidak dapat ditampilkan disini karena terlalu panjang.Encoding
movieIdEncoding
movieId berhasil dilakukan. Output tersedia di notebook dan tidak dapat ditampilkan disini karena terlalu panjang.Mapping hasil encoding
userId dan movieId:Hasil encoding tadi, di-mapping ke dalam dataframe
review_df dengan menempati kolom baru untuk masing-masing hasil.Berikut dilakukan pengecekan pada
review_df:Proses mapping berhasil dilakukan karena sudah terdapat dua kolom baru, yaitu
user dan movieBerikut adalah pengecekan kembali pada
movie_df dari beberapa aspek lainnya:Outputnya:
Berdasarkan output diatas, dapat dilihat bahwa pada
review_df terdapat:total user: 610
total review: 9724
MIN review: 0.5
MAX review: 5.0
Proses encoding telah berhasil dilakukan
Train Test Split
Train Test Split adalah metode yang digunakan untuk membagi dataset menjadi dua bagian: satu untuk melatih model (training set) dan satu lagi untuk menguji model (testing set). Biasanya, data dibagi dengan proporsi tertentu, misalnya 80% untuk training dan 20% untuk testing.
Alasan: Proses ini dilakukan agar dapat mengevaluasi kinerja model secara objektif. Dengan memisahkan data uji, kita dapat mengukur seberapa baik model memprediksi data baru yang tidak pernah dilihat sebelumnya, yang merupakan indikator penting dari kemampuan generalisasi model.
Berikut ini adalah proses Train Test Split yang dilakukan:
Dilakukan pengacakan pada dataset agar teracak merata
Pemisahan bagian atribur dan label ke dua variabel
Pemisahan
review_df menjadi dua bagian ke x_df dan y_df untuk proses Train Test Split berhasil dilakukanSplit
Proses Train Test Split telah dilakukan ke empat variabel berbebeda dengan komposisi 0.9 untuk train dan 0.1 untuk val. Berikut adalah keempatnya:
x_train
x_val
y_train
y_val
Proses Train Test Split berhasil dilakukan.
Modeling
Model yang dibuat terdiri dari dua model dengan algoritma dan pendekatan yang berbeda, yaitu
Content-Based Filtering dan Collaborative Filtering. Content-Based Filtering menggunakan dataset movie_df dan Collaborative Filtering menggunakan dataset review_df. Kedua model atau algoritma tersebut memiliki pendekatan yang berbeda-beda. Berikut ini adalah penjelasan berserta kelebihan dan kekurangan dari keduanya:Content-Based Filtering
Content-Based Filtering adalah metode yang digunakan dalam sistem rekomendasi untuk memberikan saran kepada pengguna berdasarkan item-item yang telah mereka sukai atau pilih sebelumnya. Metode ini berfokus pada karakteristik atau konten dari item yang ingin direkomendasikan.
Kelebihan Content-Based Filtering:
Personalisasi: Dapat memberikan rekomendasi yang sangat personal karena didasarkan pada preferensi sebelumnya dari pengguna itu sendiri.
Transparansi: Mudah untuk menjelaskan mengapa suatu item direkomendasikan, karena rekomendasi didasarkan pada fitur-fitur item yang telah disukai pengguna.
Kekurangan Content-Based Filtering:
Keterbatasan Diversifikasi: Cenderung merekomendasikan item yang mirip dengan yang sudah diketahui pengguna, sehingga kurang memberikan kejutan atau item baru yang berbeda.
Ketergantungan pada Konten: Memerlukan data yang cukup tentang konten item untuk bekerja dengan baik, dan kualitas rekomendasi sangat bergantung pada kualitas deskripsi item tersebut.
Pendekatan ini menggunakan atribut-atribut atau fitur-fitur item untuk menentukan kesamaan antara item yang ada. Dalam konteks proyek ini, content-based filtering akan memberikan rekomendasi film berdasarkan
genre dari film yang ada dari dataset movie_df. Model akan memberikan rekomendasi film-film yang memiliki genre yang sama berdasarkan genre dari judul film yang digunakan sebagai input.Collaborative Filtering
Collaborative Filtering adalah teknik yang digunakan dalam sistem rekomendasi untuk memberikan saran kepada pengguna berdasarkan preferensi atau perilaku pengguna lain yang memiliki kesamaan. Teknik ini mengumpulkan dan menganalisis sejumlah besar informasi tentang perilaku pengguna, aktivitas, atau preferensi dan memprediksi apa yang pengguna akan suka berdasarkan kesamaan dengan pengguna lain.
Kelebihan Collaborative Filtering:
Diversifikasi Rekomendasi: Dapat memberikan rekomendasi yang beragam karena didasarkan pada preferensi dari banyak pengguna.
Tidak Bergantung pada Konten: Tidak memerlukan pengetahuan tentang konten item, sehingga dapat bekerja dengan item yang memiliki sedikit atau tanpa data konten sama sekali.
Kekurangan Collaborative Filtering:
Masalah Cold Start: Sulit untuk memberikan rekomendasi kepada pengguna baru atau untuk item baru yang belum memiliki data interaksi.
Scalability: Dapat menjadi tantangan ketika jumlah pengguna dan item sangat besar karena membutuhkan komputasi yang intensif.
Collaborative Filtering bekerja dengan baik ketika ada cukup data dari pengguna, tetapi bisa menjadi kurang efektif jika data tersebut jarang atau tidak lengkap. Oleh karena itu, sering kali digunakan dalam kombinasi dengan teknik lain untuk meningkatkan kinerja sistem rekomendasi.
Pendekatan ini menggunakan atribut-atribut atau fitur-fitur yang ada pada dataset
review_df untuk memberikan rekomendasi kepada seorang user. Sistem Rekomendasi yang dibuat memberikan rekomendasi berdasarkan skor review yang diberikan dari sebuah film dan genre yang dilakukan oleh seorang user. Lebih tepatnya, 5 film dengan skow review tertinggi dan setiap film tersebut memiliki genrenya masing-masing. Kemudian, model akan memberikan 10 rekomendasi film untuk user tersebut berdasarkan riwayat review user tersebut.Berikut ini adalah proses Modelling and Result dari kedua algoritma tersebut:
Modelling and Result Content-Based Filtering
Modelling
Inisiasi
TfidVectorizerOutput-nya:
Output diatas adalah array yang berisi nilai-nilai yang ada pada kolom
genrefit_tranform dan pengecekan ukuranOutputnya:
Berdasarkan output diatas, dapat dilihat bahwa ukuran matriksnya sebesar 9708 x 18
to_dense()Outputnya:
Berdasarkan output diatas, proses operasi menggunakan
todense() sudah berhasil dilakukanPembuatan dataframe dari matrix tf-idf
Dataframe berhasil dibuat dengan data dari matriks yang sudah dibuat sebelumnya
cosine_similarity()Outputnya:
Berdasarkan output diatas, proses perhitungan
cosine_similarity telah berhasil dilakukan.Pembuatan dataframe dari
cosine_simOutputnya:
Berdasarkan output diatas, proses pembuatan dataframe berhasil dilakukan dan dataframe memiliki ukuran 9708 x 9708.
Similarity matrix pada data
Pembuatan function
movie_recommendations()Function utama yang digunakan untuk pembuatan model Content Based telah berhasil dibuat
Result
Untuk contoh atau simulasi penggunaan model, kita gunakan
Train to Busan (2016) yang ber-genre ActionOutputnya:
movieId title genre 9364 Train to Busan (2016) Action
Kemudian, memanggil
movie_recommendations untuk mendapatkan Top-N RecommendationsOutputnya;
title genre 0 Django Unchained (2012) Action 1 Collision Course (1989) Action 2 Family, The (2013) Action 3 Highlander: Endgame (Highlander IV) (2000) Action 4 Saint, The (1997) Action
Berikut ini adalah hasil dari
Top-N Recommendation menggunakan Content-Based Filtering. Proses penggunaan model berhasil dilakukan dan model dapat memberikan hasil rekomendasi berdasarkan input yang diberikan.Pada contoh diatas, model berhasil memberikan rekomendasi film yang juga ber-genre
Action berdasarkan input yang diberikan, yaitu Train to Busan (2016) yang juga bergenre ActionModel telah dapat berfungsi dengan baik.
Modelling and Result Collaborative Filtering
Modelling
Pembuatan
class RecommenderNetclass RecommenderNet yang digunakan untuk pembuatan model Collaborative Filtering telah berhasil dibuat.Inisiasi Model
Inisiasi model terlah berhasil dilakukan
Early Stopper
Inisiasi Callback Early Stopper yang akan memantau proses training model. Model akan berhenti jika
val_root_mean_squared_error tidak mengalami penurunan lagi selama 5 epochs. Setelah berhenti, model pada epoch tertentu yang memiliki performa terbaik akan dipertahankanTraining
Berikut ini hasil proses training yang sudah selesai pada epochs ke-15 yang memiliki :
loss : 0.5912root_mean_squared_error : 0.1817val_loss : 0.6025val_root_mean_squared_error : 0.1948Result
Berikut ini adalah output-nya:
Hasil diatas adalah hasil dari
Top-N Recommendation menggunakan Collaborative Filterting. Proses penggunaan model berhasil dilakukan dan model dapat memberikan hasil rekomendasi berdasarkan review dari user tertentu dan memberikan rekomendasi film lainnya yang cocok untuk user tersebut.Pada contoh diatas, model berhasil memberikan rekomendasi film untuk user nomor
567 yang pernah memberikan skor review tinggi ke film dan genre:Eraserhead (1977) : DramaCome and See (Idi i smotri) (1985) : DramaJetée, La (1962) : RomanceThere Will Be Blood (2007) : DramaIt's Such a Beautiful Day (2012) : AnimationModel memberikan 10 rekomendasi berupa film dengan genre:
Shawshank Redemption, The (1994) : CrimeRear Window (1954) : MysteryNorth by Northwest (1959) : ActionCasablanca (1942) : DramaSunset Blvd. (a.k.a. Sunset Boulevard) (1950) : DramaCitizen Kane (1941) : DramaRebecca (1940) : DramaNotorious (1946) : FilmNoirTo Catch a Thief (1955) : CrimeLawrence of Arabia (1962) : AdventureModel telah dapat berfungsi dengan cukup baik.
Evaluation
Untuk mengukur bagaimana performa dari model yang telah dibuat, diperlukannya metriks evaluasi untuk mengevaluasi model sistem rekomendasi film. Berikut adalah rincian metrik yang digunakan untuk tiap pendekatan:
Content-Based Filtering : PrecisionCollaborative Filtering : Root Mean Squared ErrorBerikut ini adalah penjelasan mengenai setiap metrik beserta hasil perhitungan metrik dari model yang telah dibuat :
Content-Based Filtering : PrecisionPrecisionPresisi merupakan ukuran yang menilai efektivitas model klasifikasi dalam mengidentifikasi label positif. Ukuran ini merupakan perbandingan antara jumlah prediksi yang benar-benar positif dengan keseluruhan hasil yang diprediksi sebagai positif, termasuk yang sebenarnya negatif.
Berikut adalah formula dan cara kerja dari
Precision :Formula
$$Precision = TP/(TP+FP)$$
Dalam Konteks sistem rekomendasi menjadi:
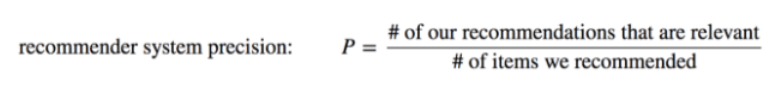
Gambar 2a - Formula Precision
Cara Kerja
Formula tersebut mengukur presisi dalam konteks sistem rekomendasi. Presisi dihitung dengan membagi jumlah rekomendasi yang relevan dengan jumlah total item yang direkomendasikan. Jadi, jika sebuah sistem merekomendasikan 10 film dan hanya 6 yang relevan atau disukai oleh pengguna, maka presisi sistem tersebut adalah 0.6 atau 60%. Ini menunjukkan seberapa akurat sistem dalam memberikan rekomendasi yang sesuai dengan kebutuhan atau selera pengguna.
Penjelasan Hasil
Precision dari model Content-Based LearningFungsi dari
calculate_precision digunakan untuk perhitungan Presisi berdasarkan formula PresisiFunction utama yang digunakan untuk menghitung skor
Precision dari model Content-Based Filtering telah berhasil dibuat.Hasilnya perhitungan untuk setiap genre
Output-nya:
Berdasarkan hasil diatas, model memiliki skor presisi sebesar
1.0 atau 100% untuk semua genre dalam memberikan rekomendasi berdasarkan genre.Model memiliki performa yang sangat baik dalam memberikan rekomendasi secara Content-Based Filtering.
Colaborative Filtering : Root Mean Squared ErrorRoot Mean Squared ErrorRoot Mean Square Error (RMSE) adalah metrik yang sering digunakan dalam machine learning untuk mengukur seberapa baik sebuah model prediktif dapat memperkirakan nilai yang sebenarnya. RMSE merupakan akar kuadrat dari rata-rata perbedaan kuadrat antara nilai yang diprediksi oleh model dan nilai yang sebenarnya (nilai aktual).
Berikut ini adalah formula dan cara kerja dari
Root Mean Squared Error :Formula
$$RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2}$$
Cara Kerja
RMSE menghitung akar kuadrat dari rata-rata perbedaan kuadrat antara nilai yang diprediksi oleh model dan nilai sebenarnya. Proses kerjanya melibatkan beberapa langkah. Pertama, untuk setiap titik data, kita menghitung selisih antara prediksi model dan nilai aktual. Selisih ini kemudian dikuadratkan untuk menghilangkan nilai negatif dan memberikan bobot lebih pada kesalahan yang lebih besar. Setelah itu, kita menghitung rata-rata dari nilai-nilai kuadrat tersebut. Terakhir, kita mengambil akar kuadrat dari rata-rata ini untuk mendapatkan RMSE.
Penjelasan Hasil
Root Mean Squared Error dari model Collaborative LearningPlot History
Root Mean Squared Error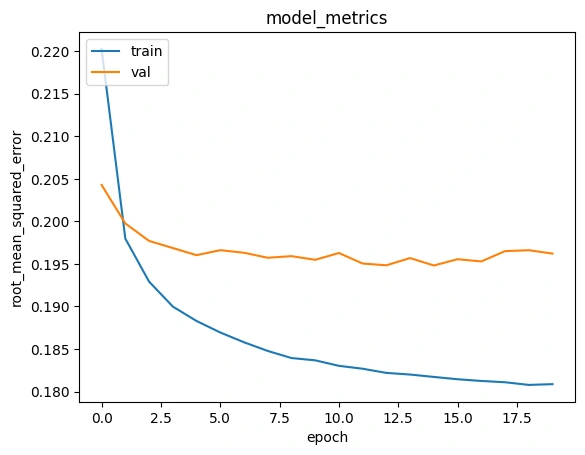
Gambar 2b - History Plot
Berdasarkan plot tersebut, proses training model berhenti pada epoch ke 15 (epochs 1 dimulai dari nomor 0 pada plot) karena
callbacks yang berisi early stopper. early stopper menghentikan proses training karena model tidak menunjukkan penurunan yang lebih keci dari val_root_mean_squared_error pada epochs ke-15 selama 5 epochs berturut-turut.Kemudian, model pada epochs ke 15 yang dipertahankan karena pada epochs tersebut model memiliki performa yang terbaik. Berikut adalah hasil dari metriks pada epocs tersebut:
loss : 0.5912root_mean_squared_error : 0.1817val_loss : 0.6025val_root_mean_squared_error : 0.1948Model dapat memberikan rekomendasi secara Collaborative Filtering dengan cukup baik.
Referensi
[1] Q. Yang, J. Huo, H. Li, Y. Xi, and Y. Liu, “Can social interaction-oriented content trigger viewers’ purchasing and gift-giving behaviors? Evidence from live-streaming commerce,” Internet Research, Mar. 2023, doi: https://doi.org/10.1108/intr-11-2021-0861.
[2] Şeyma BOZKURT UZAN and Kutluk ATALAY, “DEVELOPING NEW SUGGESTIONS FOR THE CONTENTS OF A DIGITAL PLATFORM USING RECOMMENDATION SYSTEMS ALGORITHMS,” Social science development journal, vol. 8, no. 38, pp. 187–202, Jul. 2023, doi: https://doi.org/10.31567/ssd.931.
[3] Karlijn Dinnissen and C. Bauer, “Amplifying Artists’ Voices: Item Provider Perspectives on Influence and Fairness of Music Streaming Platforms,” Jun. 2023, doi: https://doi.org/10.1145/3565472.3592960.
[4] P. Khambatta, S. Mariadassou, J. Morris, and S. C. Wheeler, “Tailoring recommendation algorithms to ideal preferences makes users better off,” Scientific Reports, vol. 13, p. 9325, Jun. 2023, doi: https://doi.org/10.1038/s41598-023-34192-x.
[5] “Movie Recommendation Systems Using Content-Based Filtering,” International Research Journal of Modernization in Engineering Technology and Science, Jun. 2023, doi: https://doi.org/10.56726/irjmets42626.
[6] S. Katkam, A. Atikam, P. Mahesh, M. Chatre, S. S. Kumar, and S. G. R, “Content-based Movie Recommendation System and Sentimental analysis using ML,” IEEE Xplore, May 01, 2023. https://ieeexplore.ieee.org/document/10142424
Like this project
Posted Jul 14, 2025
Developed a recommendation system for streaming platforms using content-based and collaborative filtering.
Likes
0
Views
2