HeartPal
Dhanush Vardhan Kalaiselvan

Inspiration
Our concept was sparked by the notorious COVID-19. Not only has COVID-19 directly killed millions of people globally but has indirectly harmed the lives of those who suffer from heart disease. This is because these patients can no longer meet with their doctors at their typical hospital due to the risks it poses and distancing guidelines/other regulations. Currently, physicians and med students can only identify heart disease with a scary rate of 20% accuracy. Additionally, heart disease is the leading cause of death in India, America, Europe, and more. Not only this, but heart arrhythmia garners over 3 million cases a year, and can even occur without many symptoms while requiring immediate medical treatment. As a result, I noticed a need for a mechanism to correctly self-diagnose patients suffering from cardiac issues remotely such as heart arrhythmia, as well as a mobile app for patients to connect with their physicians. HeartPal arose as a result of this.
What it does
HeartPal is a device and mobile app combo. The device is built with a MEMS microphone and connects directly to the headphone jack of the phone. When you launch the app, you are prompted to log in or register as a patient or a doctor. When you log in as a patient, the home screen shows you your recent recordings and their analysis. From the home screen, you can also add doctors and share your recordings with a doctor of your choice. You can also click on your profile to see more details. When you log in as a doctor, you are greeted with the view of your patients. You can view each patient and their recordings. The doctor can even playback the recording to hear exactly how the recording sounded.
How we built it
Device
Our plan at a high level was to connect the stethoscope head to a MEMS microphone, and then connect the MEMS microphone to the phone using an adapter. We followed this electrical diagram:
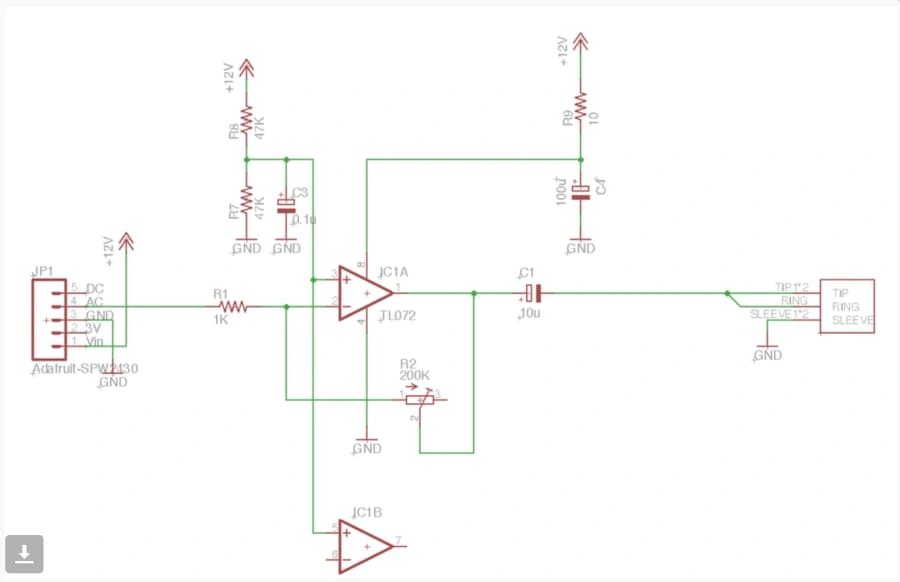
The circuit consists of an amplification mechanism and has a potentiometer to control the gain. This was useful for testing so we could actually hear the heartbeat when we connected our adapter to headphones. After we put it all together on a breadboard, we soldered all the components together on a PCB. Then, we put the circuitry inside of an Altoids box and drilled two holes - one for the pipe to go in, and the other for the headphone wire to come out to plug into the phone. This is what our final product looked like:

App
The app was built with Flutter, a cross platform framework target for mobile development. We used Firebase authentication to log users in, transitioning from our original MongoDB + bcrypt model that we used to securely hash all the users’ passwords. We plan on returning to this system in the future. We used Cloud Firestore primarily for our database. We implemented
StreamBuilder so that data would be updated in real time. We sent the recorded file to our server through an http request that had the file attached through multipart/form-data.Backend
Server Our server was hosted on a digital ocean droplet. We used ssh and scp to communicate with our server.
AI Algorithm
We spent a decent amount of time reviewing research papers on this topic before developing the machine learning model. We read papers on biology, Hidden State Semi-Markov models based on Bayesian Inference and Logistic Regression, and Mel-frequency Cepstral Coefficients among other things. After researching a variety of techniques we combined the best of each and attempted to produce a hybrid model. The plan was to first train a heartbeat segmentation model on a segmentation dataset that would allow us to segment a given audio recording of a heartbeat into its S1 and S2 stages (the ‘lub’ and ‘dub’ sounds). Then we would use that segmentation model to split the classification dataset that contained recordings of varying length from 5 to 120 seconds into even recordings containing exactly 5 heart cycles (5 ‘lub dubs’) (see below). It has been shown to greatly increase the accuracy of a model trained on 5 heart cycle data over one trained on data with a fixed second delay.
Number of Heartbeat Cycles vs Accuracy
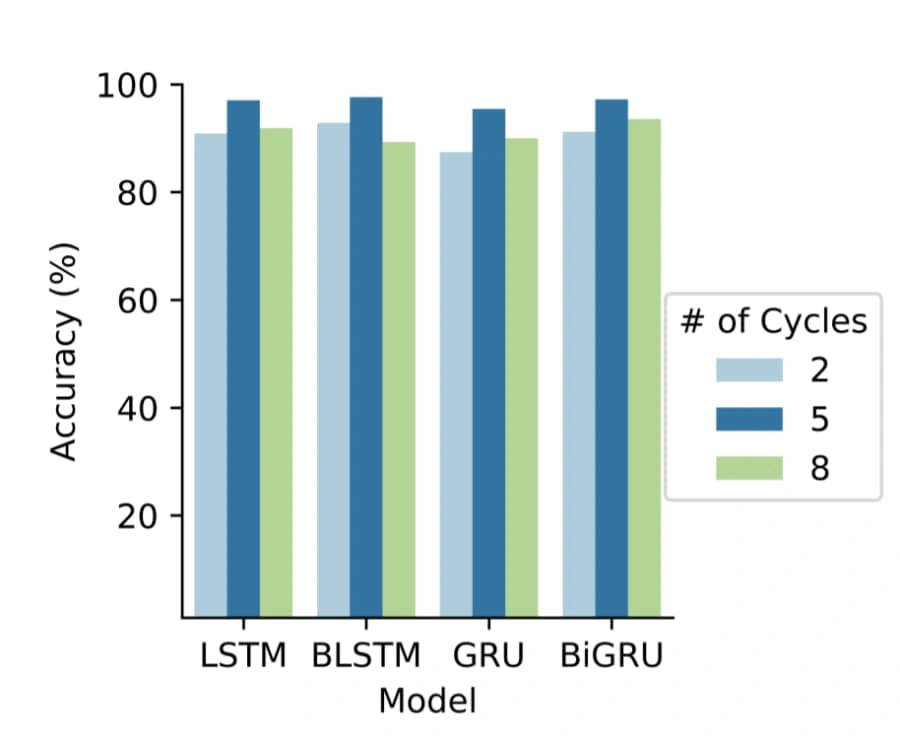
Number of Heartbeat Cycles vs Accuracy
Heartbeat segmentation:
One paper found a HSMM using Homomorphic, Hilbert, Wavelet, and Power spectral density envelopes was the most accurate for this segmentation task, but we unfortunately weren’t able to find any Python Libraries that implement HSMMs for our task and didn’t have time to write it from scratch. So we decided to use deep learning instead, and looked for a dataset. However, we failed to find a heartbeat segmentation dataset that fit our needs. The best dataset we could find was far too small at only 390 training examples, and our segmentation model achieved less than the baseline accuracy despite attempting the problem as both a classification and regression problem.
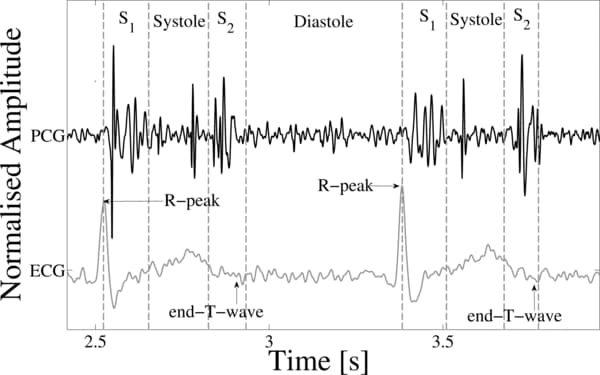
So we pivoted and followed the following new outline: firstly, we would train a large deep learning model on a large heartbeat classification dataset of segmented ECG recordings and then would use transfer learning to train a classifier on the smaller dataset that most closely fit our need. Let’s look at the datasets first. The larger dataset was actually not a single dataset, but rather a collection of a few we combined together after processing them to be compatible. They included ECG recordings from the MIT-BIH Arrhythmia and PTB Diagnostic ECG datasets. The recordings were from a variety of ages, health levels, races, and genders taken by a multitude of different doctors from different practices in different locations around the world, minimizing bias in the data. Having a variety of data is important to make sure certain patients aren’t treated unfairly due to socialtial, medical, or other biases. The smaller dataset we used was from the 2016 CinC/PhysioNet Challenge dataset which had PCG recordings. We needed PCG recordings because our physical device was most similar to a PCG as it used analog sound signals rather than electrical impulses. However, transfer learning was compatible between ECGs and PCGs because their underlying wave structure is quite similar (see below).
To prepare the data for the deep learning model, we did a number of preprocessing steps. We began by denoising the data through a bandpass filter, normalizing it, and downsampling it. Then, to limit the number of superfluous features and to speed up training, we represented each audio file as a collection of 13 Mel-frequency cepstral coefficients. However, this ended up not producing as high validation accuracy as just further downsampling the audio, so in the end we used the processed samples of the 125Hz recordings instead of the MFCCs. Each data sample was already segmented, so we merely padded them with zeros to be of constant length.
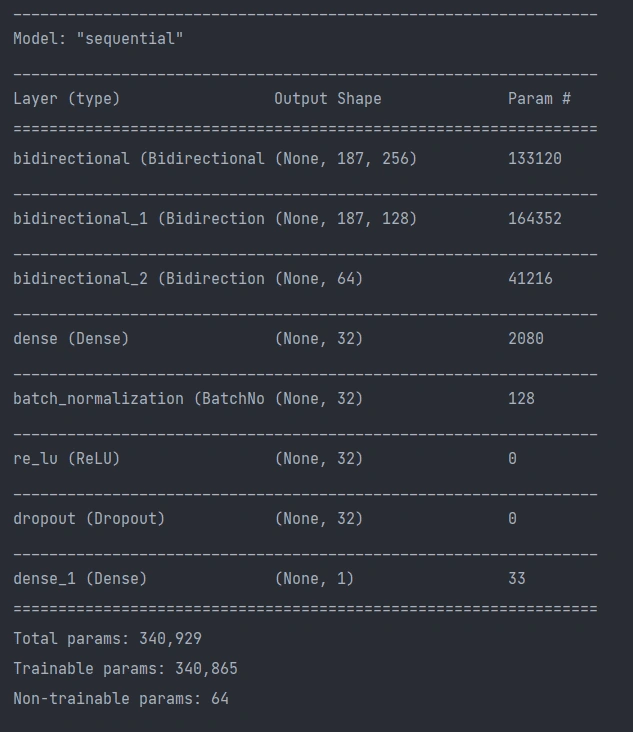
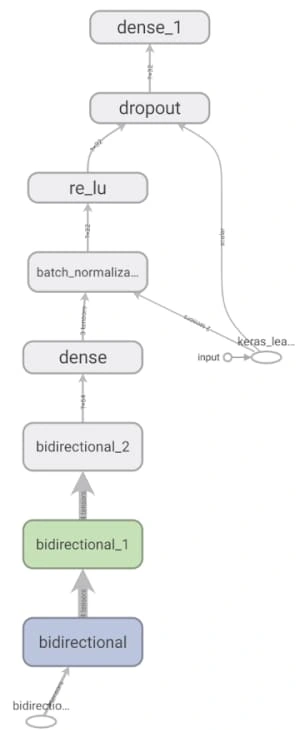
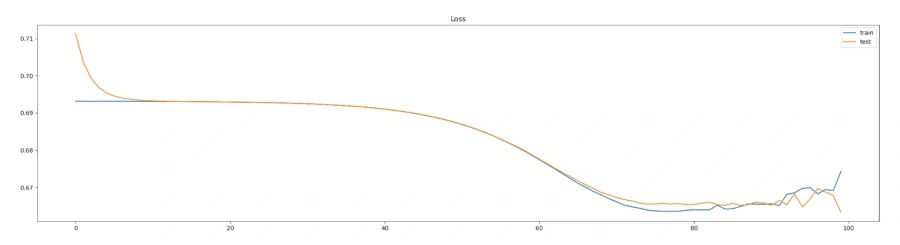
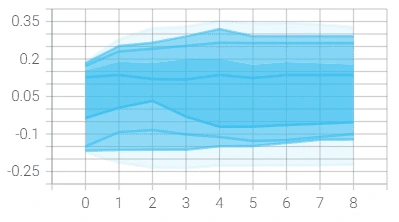
The model architecture was as seen above: 3 bidirectional LSTM layers followed by a dense layer with batch normalization and dropout. The final output layer was a single neuron for the binary classification task that is “normal” vs “abnormal” heartbeat. The model was initially overfitting before we added batch normalization, as seen in the following graph, so we added batch normalization and the before+after of the variance of the data clearly testifies to its effectiveness, if the increase in validation accuracy wasn't enough.
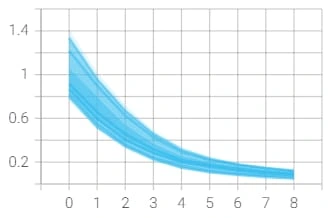
However, we reached a point where the model was plateauing during training which we solved by using a novel stochastic optimization of Adam optimizer along with a custom learning rate scheduler and early stopping. Below are the graphs of before and after these additions with the before in orange/blue and after in green/pink.
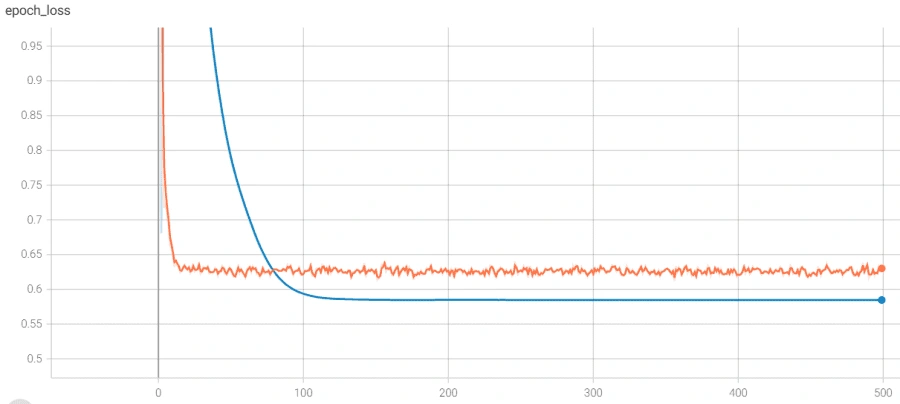
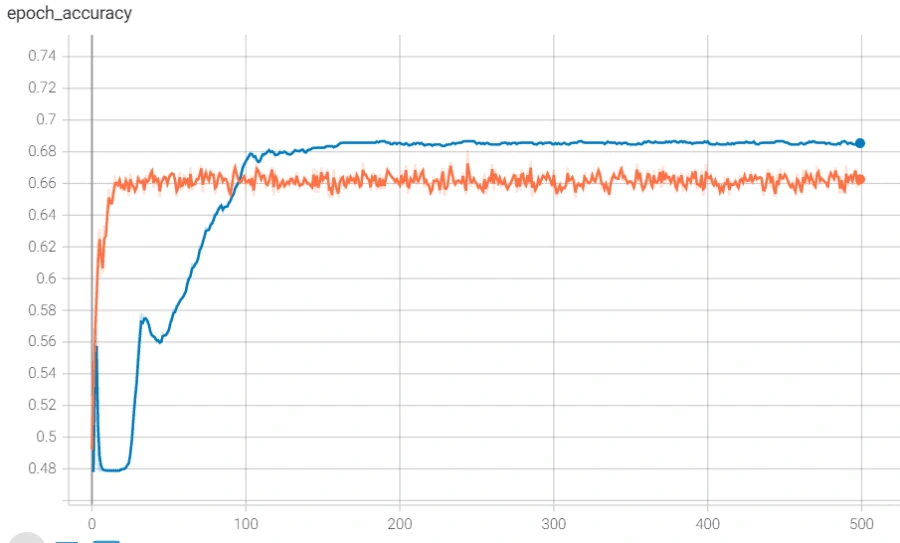
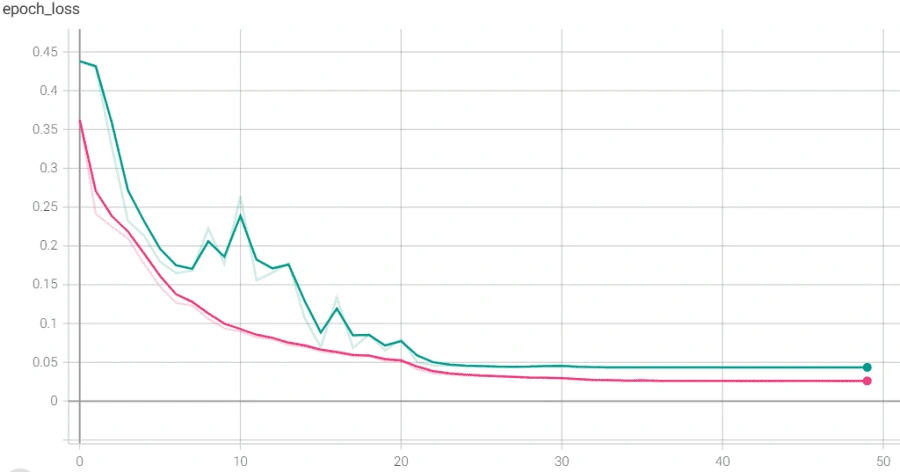
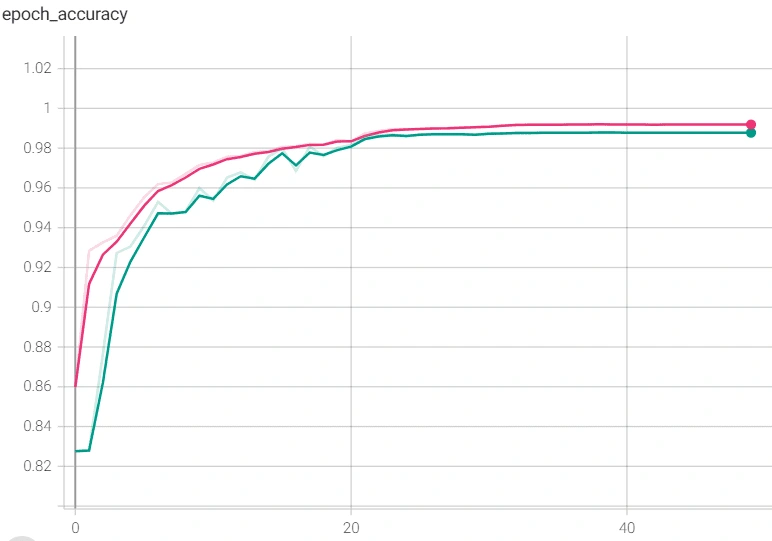
Finally, we used this model’s main layers and used it on the smaller, PCG dataset through transfer learning. We were able to achieve much higher accuracy than we could have without transfer learning, though we did run into some issues. It was also plateauing, but we solved that by adjusting the number of trainable layers in the pretrained based model. The below graph shows the plateau and the higher accuracy achieved after adjusting the layers.
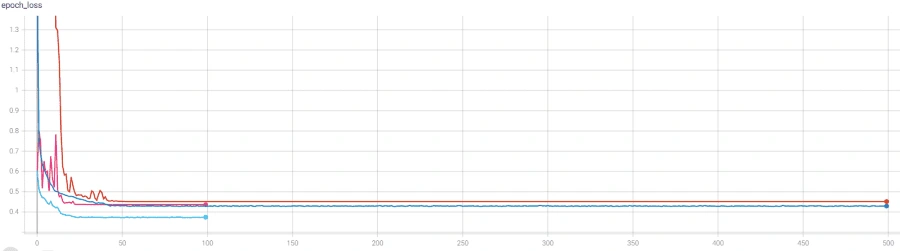
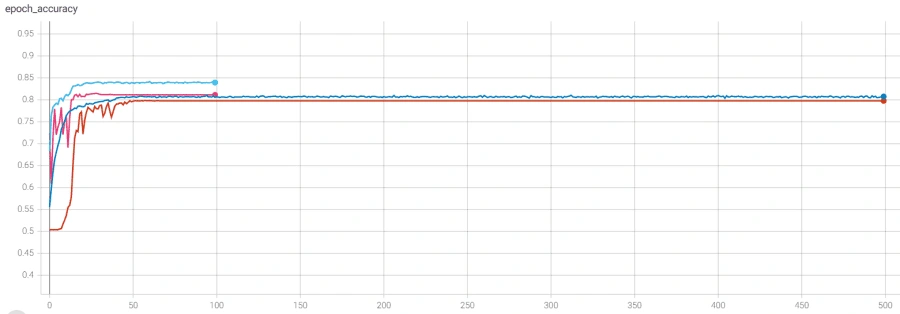
Overall, we had great results, with a test accuracy of 98.81% on novel data, a sensitivity of 0.9505, a specificity of 0.9959, and an AUC of the ROC of 0.9934.
Having a high specificity was very important as a high number means a patient won’t be told they are disease free when they really could be dying. The lower sensitivity was an intentional trade off as an extra trip to the doctor is better than late diagnosis which could lead to death.
Finally, our next steps would be to create a proper segmentation model to further improve our deep learning algorithm. We would also use an ensemble like approach or would use the segmentation model to process the data for the classification model. Using either of these techniques has been shown to be very effective in research papers and in real world tests and should result in improvements.
Challenges we ran into
We ran into many challenges throughout this project, especially on the device side given the limited amount of time we had. The first problem we had was the mic not picking up the stethoscope sound, simply because it was too quiet. This was because the stethoscope piece we ordered was cheap due to this being a prototype. Because of the bad quality, it wasn’t not emitting a very loud sound. This problem will be fixed easily in the future when we invest in a better stethoscope piece. Another problem we had was when we were making our PCB. The circuit stopped working and we couldn’t figure out why. We had to go through each part of the circuit and eliminate what the problem was when we finally found out that our microphone itself had broken. It was quite unfortunate that this happened last minute, but luckily we had recorded our demo before the microphone had broken.
Accomplishments that we're proud of
We are very proud of our deep learning model. We were able to achieve an outstanding 99% test accuracy while making sure we don’t overfit our model. We are also very proud of how production-ready our app looks, and the smooth UI and animations it flaunts. We are especially proud of how quickly we were able to make an entirely new device from scratch. We had to plan and order all the parts ahead of time, and design the circuit. It’s unfortunate that our microphone had to break, but that’s part of a hackathon.
What we learned
Akash I learned a lot about AI and how it worked specifically. It was super cool to me to learn what each line does while training the model. I learned about RNN layers and what they do, such as Dense, Activation layers, and so on.
Austin I got to work with analog devices before which is something I hadn’t touched much before. When making the PCB, I got some practice with soldering and learned the importance of being precise when I solder. I also was able to learn some of the concepts of Flutter from Akash.
Dhanush I worked on the front-end . I developed the app and connected the back-end to the app. I also designed the UI for the project using Firebase and implemented the authentication. Akash and Ani taught me about SSH and connecting to our server.
Ani I learned a lot about how audio processing works and the techniques you can use to make effective deep learning models using it. I also finally learned more about the rumored Fourier Transform and Markov model. Before this hackathon, I hadn't done anything with audio, so it was fascinating to discover how many characteristics you can extract from a basic WAV file and how powerful recurrent neural networks can be on temporal data like audio.
What's next for HeartPal
Our ultimate goal for HeartPal is to bring it into the real world and save lives. We want to improve our algorithm by using transfer learning on even larger datasets compiled together. We also want to switch our database to MongoDB and switch our hosting to AWS. Another thing we want to do is 3D print a case for our device and make it look sleeker. With these changes, we feel we are ready to try launching HeartPal in the market.
Works Cited
S. Mangione and L. Z. Nieman, “Cardiac auscultatory skills of internal medicine and family practice trainees: a comparison of diagnostic proficiency,” Jama, vol. 278, no. 9, pp. 717–722, 1997.
M. Lam, T. Lee, P. Boey, W. Ng, H. Hey, K. Ho, and P. Cheong, “Factors influencing cardiac auscultation proficiency in physician trainees,” Singapore medical journal, vol. 46, no. 1, p. 11, 2005.
S. L. Strunic, F. Rios-Gutierrez, R. Alba-Flores, G. Nordehn, and ´ S. Bums, “Detection and classification of cardiac murmurs using segmentation techniques and artificial neural networks,” in Computational Intelligence and Data Mining, 2007. CIDM 2007. IEEE Symposium on. IEEE, 2007, pp. 397–404.
K. Ejaz, G. Nordehn, R. Alba-Flores, F. Rios-Gutierrez, S. Burns, and N. Andrisevic, “A heart murmur detection system using spectrograms and artificial neural networks.” in Circuits, Signals, and Systems, 2004, pp. 374–379.
Goldberger, A., Amaral, L., Glass, L., Hausdorff, J., Ivanov, P. C., Mark, R., ... & Stanley, H. E. (2000). PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation [Online]. 101 (23), pp. E215–e220.
Goldberger, A., Amaral, L., Glass, L., Hausdorff, J., Ivanov, P. C., Mark, R., ... & Stanley, H. E. (2000). PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation [Online]. 101 (23), pp. E215–e220
Goldberger, A., Amaral, L., Glass, L., Hausdorff, J., Ivanov, P. C., Mark, R., ... & Stanley, H. E. (2000). PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation [Online]. 101 (23), pp. e215–e220
Loading this content connects you to devpost.com.
devpost.com privacy informationLike this project
Posted Dec 29, 2023
HeartPal - A digital stethoscope fully built from scratch connected to a mobile app that records your heartbeat and sends it to our backend, where ...
Likes
0
Views
0


