MCTS-UCB Transformer Ensemble
waqar ahmed
MCTS-UCB Transformer Ensemble
Project Overview
This project is related to the development of a chess engine by harnessing the capabilities of machine learning. The cornerstone of this approach lies in three key components:
Encoder-Only Transformer:
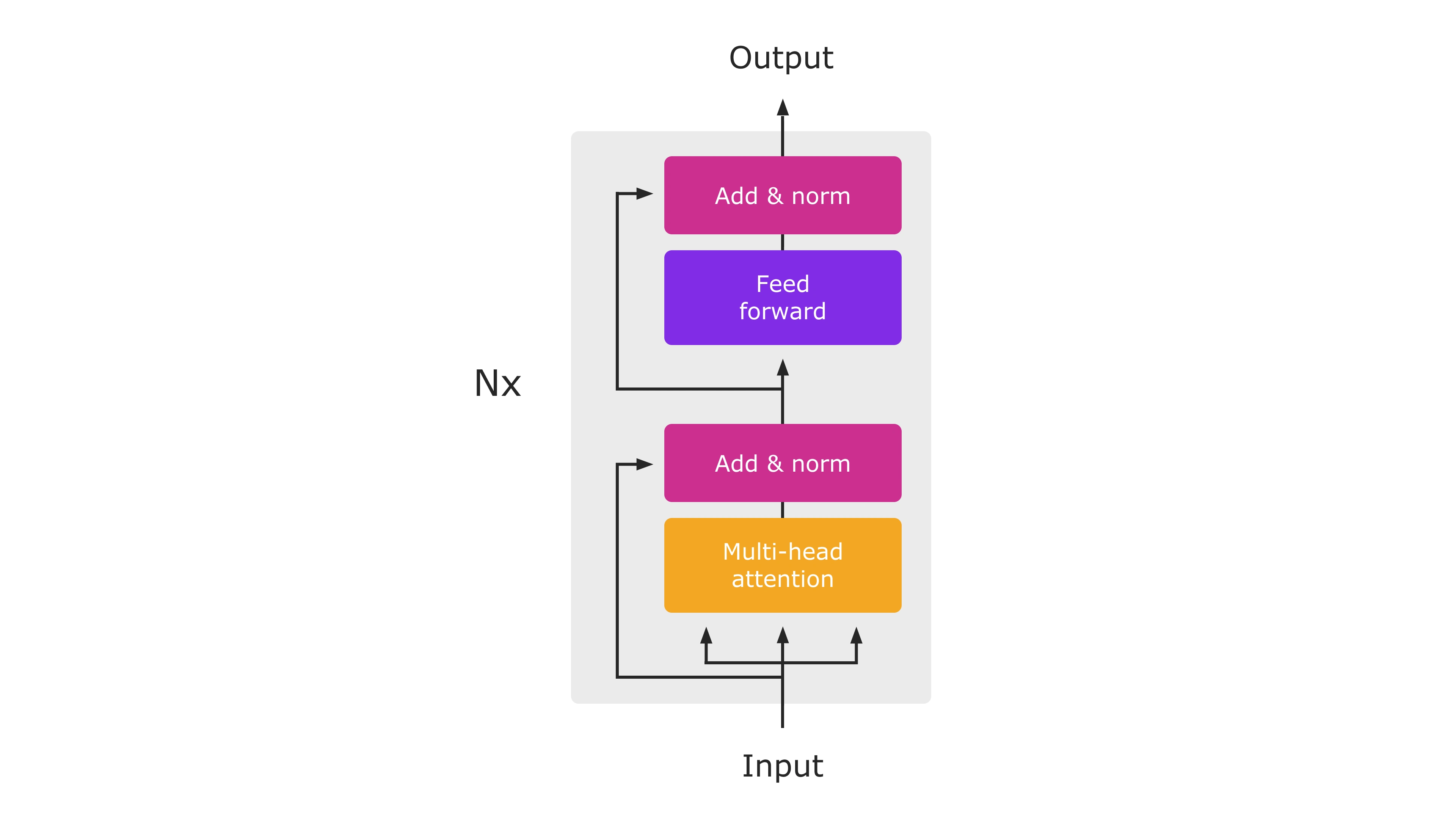
This tailored transformer architecture excels at processing chess board representations in FEN (Forsyth-Edwards Notation) format. It leverages the capabilities of sequential modeling and attention mechanisms to predict game outcomes (white win, black win, or draw) along with their corresponding probabilities. Encoder-Only Transformer Model:
The encoder-only transformer employed in this project operates by processing the input FEN notation through multiple self-attention layers. These layers progressively capture contextual relationships within the FEN representation, allowing the model to build a comprehensive understanding of the chessboard state:
1- Input Embedding: The FEN notation is first converted into a numerical representation using embedding techniques. This step transforms the symbolic chessboard description into a format suitable for the transformer's processing.
2 - Self-Attention: The core of the transformer lies in the self-attention mechanism. Within each layer, the model attends to different parts of the input sequence (FEN tokens) to understand how they relate to each other. This enables the model to capture long-range dependencies and interactions between various elements on the chessboard.
3 - Positional Encoding: Since the order of tokens in the FEN notation is significant, positional encoding is often incorporated to inject positional information into the model. This ensures that the model can differentiate between pieces based on their location on the board, even if they are represented by the same token.
4- Feed Forward Network: Following the self-attention layer, a feed forward network is typically employed to introduce non-linearity and enhance the model's capacity to learn complex relationships within the chessboard state.
5- Encoder Stack: The self-attention, positional encoding, and feed forward network steps are typically stacked multiple times, allowing the model to progressively refine its understanding of the board through hierarchical learning.
Monte Carlo Tree Search (MCTS):
This potent search algorithm strategically navigates the game tree, guided by the predictions from the transformer model. It prioritizes exploring promising moves with the ultimate goal of identifying the most advantageous sequence of actions.
MCTS: Balancing Exploration and Exploitation
MCTS employs the following core functions to achieve optimal exploration and exploitation during the search process:
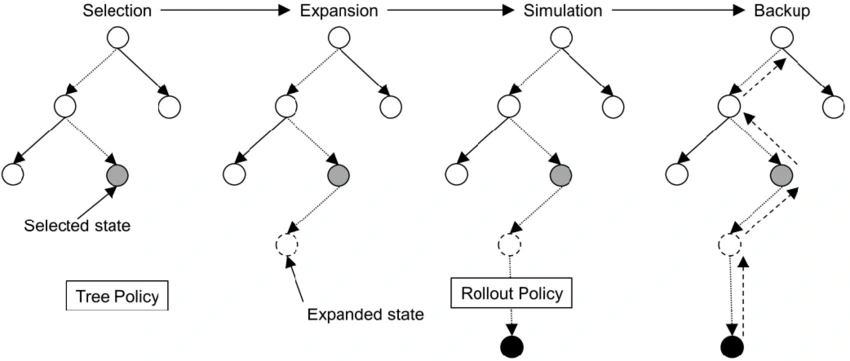
Selection:
This function meticulously selects the most promising node in the tree based on a combination of the transformer's predicted outcome and the Upper Confidence Bound 1 (UCB1) value. The selection process balances exploiting currently well-performing moves with exploring potentially better options.
Expansion:
New child nodes are strategically created for the chosen node, expanding the search space and allowing for further exploration.
Simulation:
A rapid rollout or playout simulates the game from the expanded node until a terminal state (win, loss, or draw) is reached. This simulation provides valuable feedback for evaluating the node's potential.
Backpropagation:
The evaluation results (win/loss/draw) from the simulation are propagated back up the tree, updating the win rates and UCB1 values of the traversed nodes. This feedback loop guides future search decisions.
Upper Confidence Bound 1 (UCB1):
This strategy strikes a balance between exploiting currently well-performing moves and exploring potentially better, yet less explored, options. UCB1 incorporates both the average reward (predicted outcome from the transformer) and a bonus term that encourages exploration of less frequently visited nodes
Get Started
To run the project and experience this innovative chess engine, simply follow the instructions below:
1- Ensure you have Docker installed.
2- Clone the repository.
3- Build the Docker image: docker build -t mcts-ucb-chess .
4- Run the container: docker run -it mcts-ucb-chess
Data-driven limitations:
"The dataset's limited size constrained the model's test set accuracy. Expanding the dataset with more chess FEN data While a complete chess game's FEN conversion yields abundant data, its usefulness is limited for outcome prediction, especially in early game stages due to the vast potential move combinations. The engine's performance would benefit from a dataset concentrated on endgame and near-endgame positions, where the outcome is more closely correlated to the board state."
Like this project
Posted Feb 7, 2025
Encoder-only transformer with UCB1 and Monte Carlo to play chess - IM07813/MCTS-UCB-Transformer-Ensemble
Likes
0
Views
5