Tensorlake
Likitha Shashikumar
Challenge
When we joined Tensorlake, the product was initially built for engineers — an API-first platform intended to be deployed directly into user infrastructure. While this approach offered speed and flexibility, it became clear that we needed more robust user-facing tools to support scale, usability, and broader adoption.
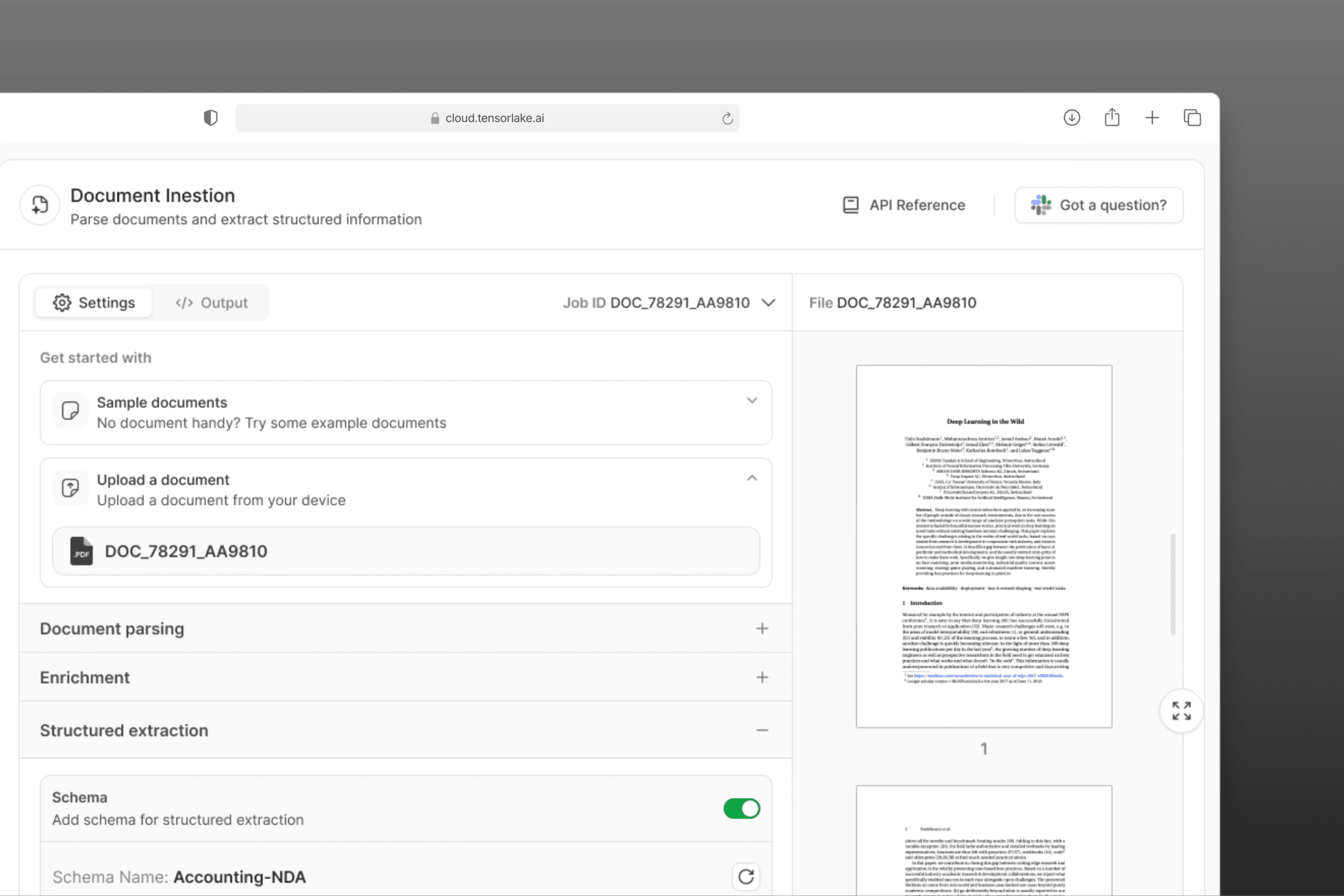
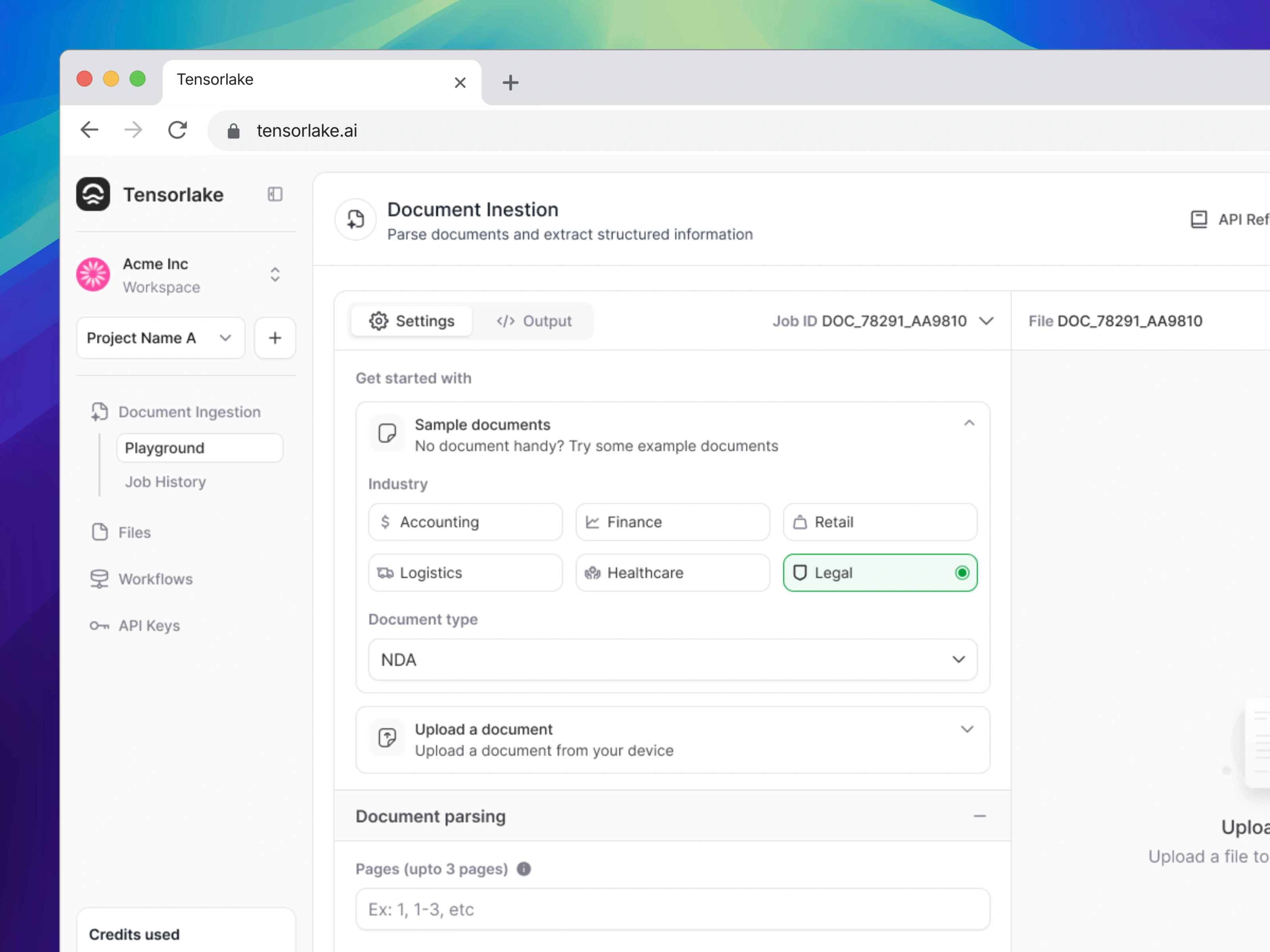
Document Settings
We began by designing and building the Document Ingestion UI, evolving it from a basic upload interface into a powerful, flexible tool that supported:
Custom schema input for structured data extraction
Support for advanced features like signature detection
A schema builder UI so users could create extraction schemas visually instead of pasting raw code
Collection creation, allowing users to reuse configurations across large document sets
Serverless Workflows
What did we work on?
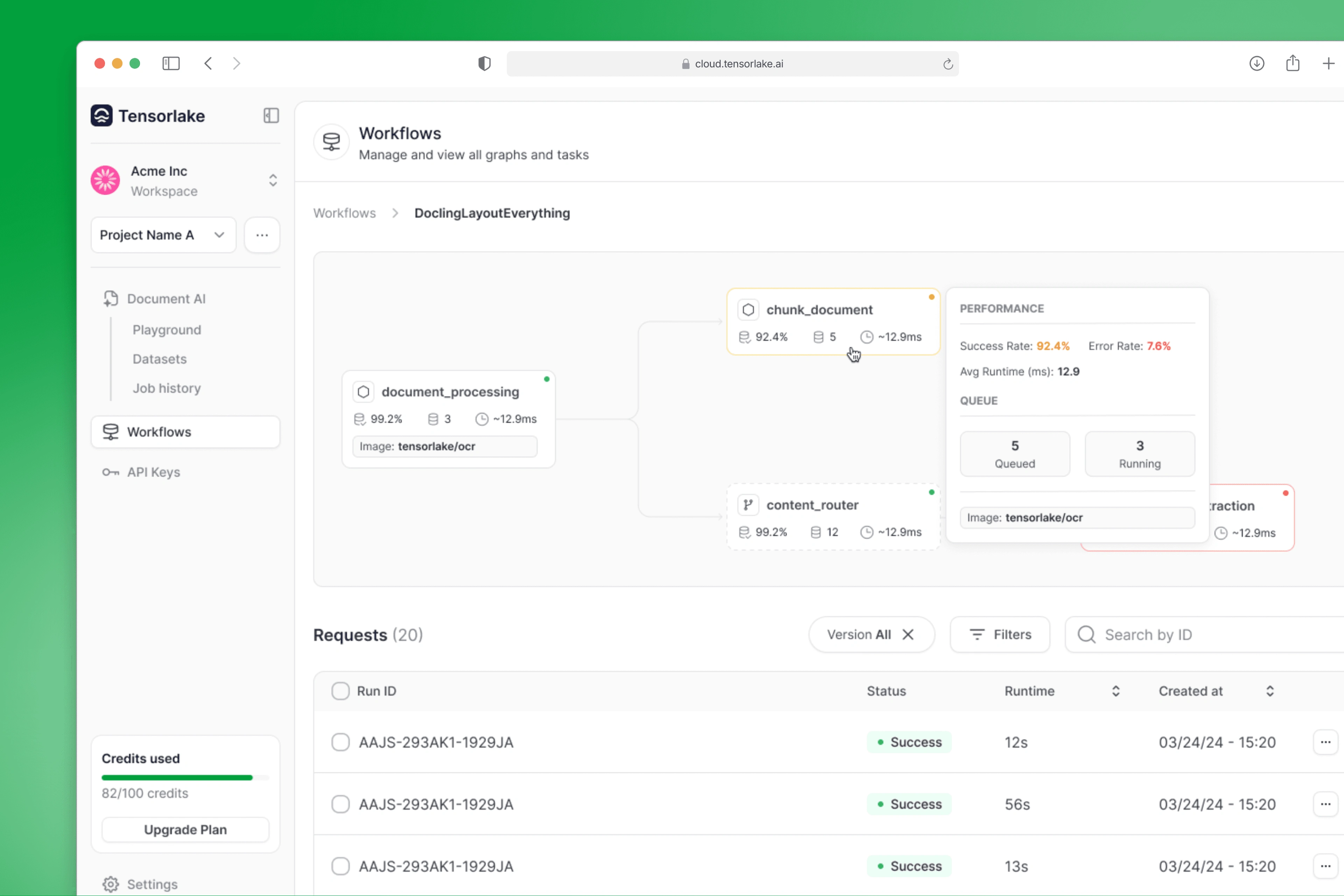
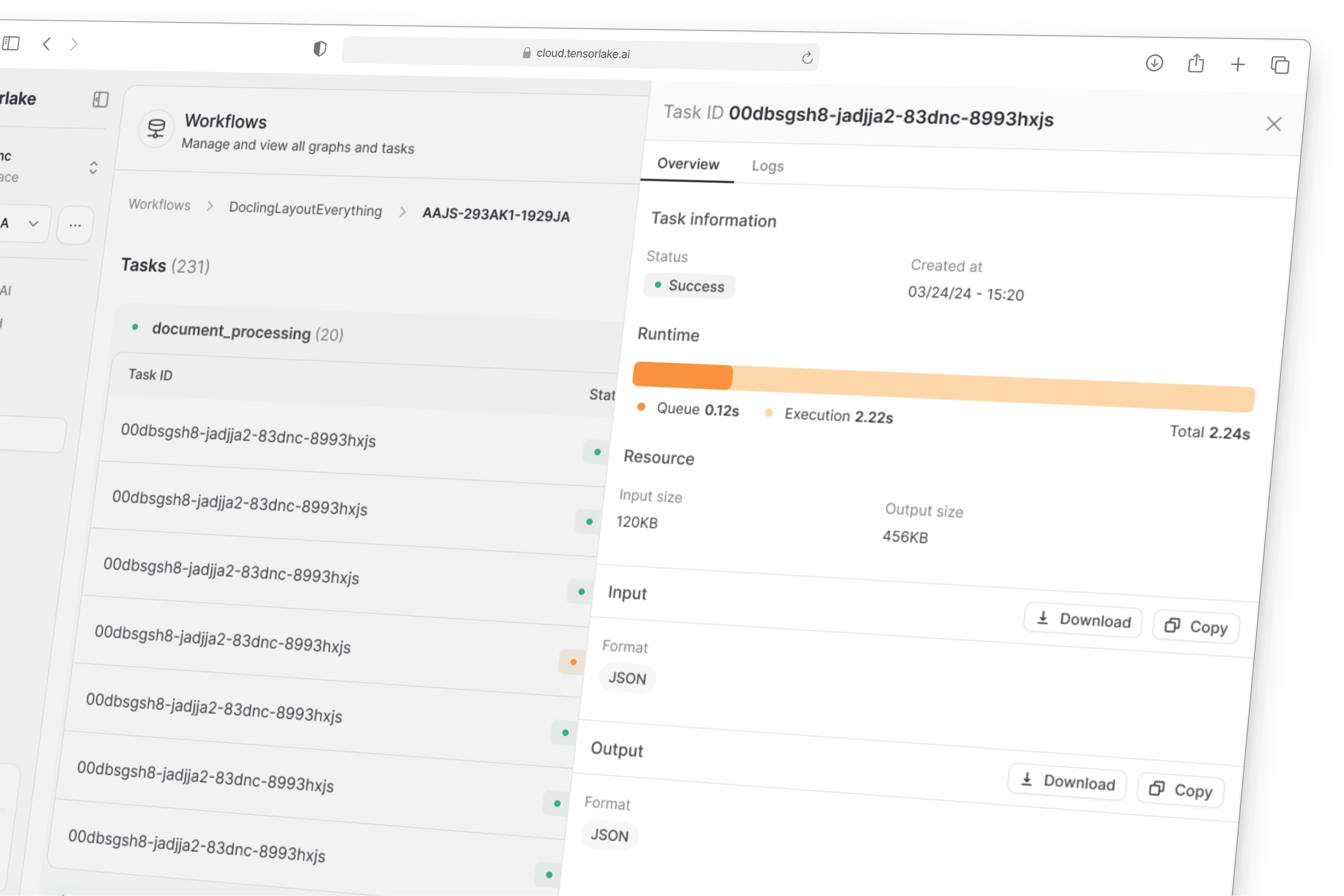
Following that, we focused on the Workflows interface — the frontend layer for managing serverless data workflows. This view made it easy to visualize:
The sequence of functions and tasks in a pipeline
The output of each task
Task status and errors during execution
Workflows Overview
We shipped these features through continuous iteration, grounded in real user feedback and tight cross-functional collaboration.
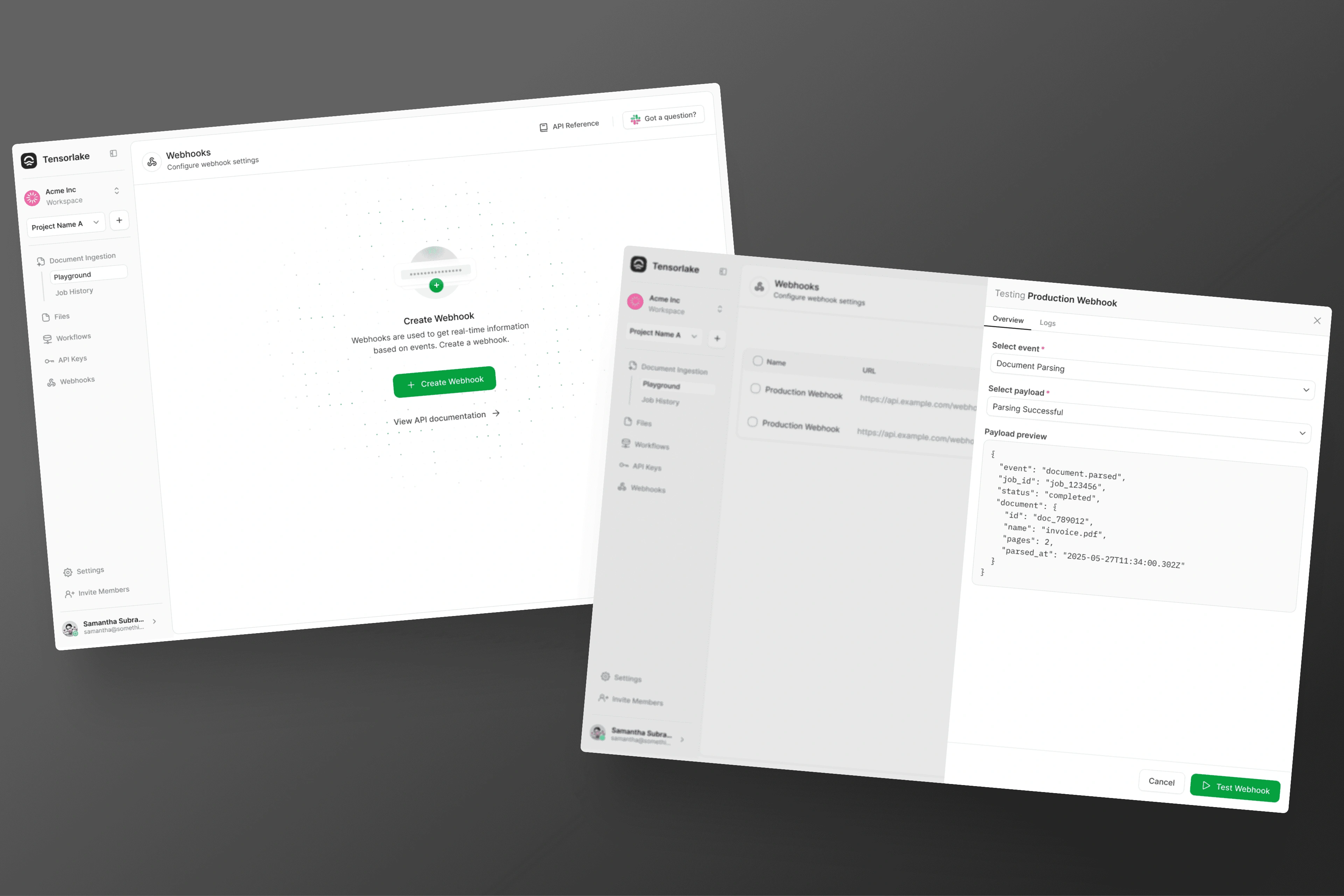
Webhooks
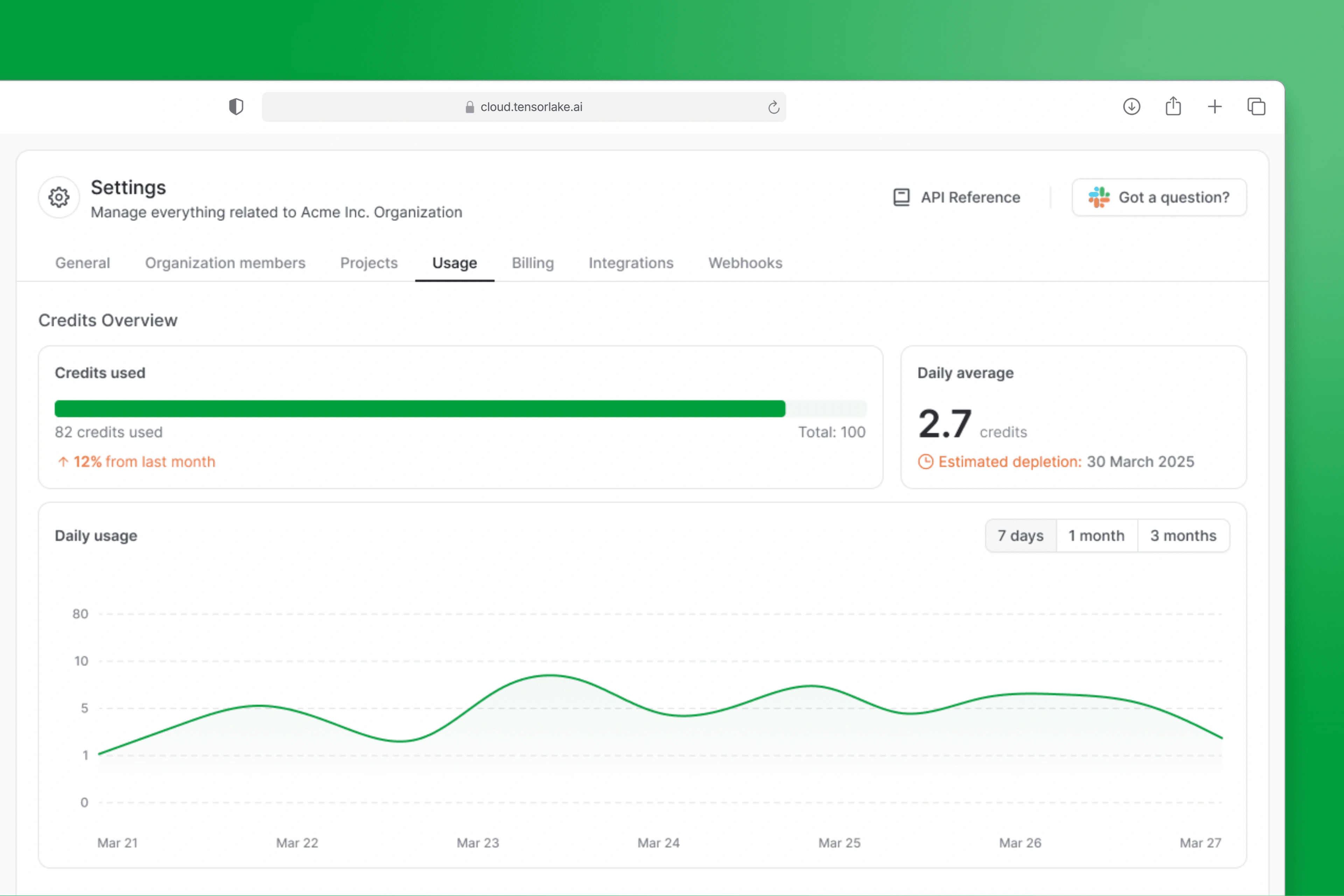
Business Impact
These product improvements significantly enhanced how customers interacted with Tensorlake and led directly to meaningful business outcomes:
Helped close $$$$+ in enterprise deals
Supported acquisition of 5–7 new high-value customers
Contributed to Tensorlake’s strong competitive positioning in the fast-growing unstructured data infra space
Usage Screen
Like this project
Posted Sep 14, 2025
Designed the 0-1 version of the serverless workflows and document ingestion platform that aided in the bootstrapped to $8m seed funding journey.
Likes
1
Views
5
Timeline
Oct 9, 2024 - May 1, 2025