Hitting the right level of abstractions when building an Intern…
AHJ George

Great software connects with its users on a meaningful level. Building an effective Internal Developer Platform (IDP) that engineers adopt willingly is no easy task, however: It's extremely tough to hit the mark when it comes to abstraction.
How can your IDP provide an optimal level of abstraction? How can you design abstraction layers that appeal to your engineering teams by supporting their delivery workflows? I'll take you through some of the challenges, helpful design goals, and methodologies you should know.
Tackling the abstraction problem with smart design goals
What makes a platform abstraction effective? Well, let's start with a healthy dose of realism: IDPs are complex systems, and there's no use pretending otherwise.

Luckily, such complexity also works in our favor by offering a potential roadmap: According to Gall's Law, complex systems that work always evolve from simple systems that worked. So platform architects should start simple and improve over time.
Looking at other realities of the problem can also help us flesh out this strategy. For instance, organizations that invest in IDPs usually do so to fulfill a need. At a certain size – as a rule of thumb, say more than 50 engineers – thinking about platform engineering is a natural response to the challenges of delivering software that has to satisfy numerous users, organizational goals, and compliance targets.
It helps to apply a similar conceptual image to platform architectures: Your IDP's microservice composition should reflect the hierarchical need structure of your organization. In other words, you prioritize the operational must-haves and go from there.
Always start with the fundamentals you can't live without – like hosting and storage. Then, you build upward in what I like to refer to as a microservice hierarchy of needs.
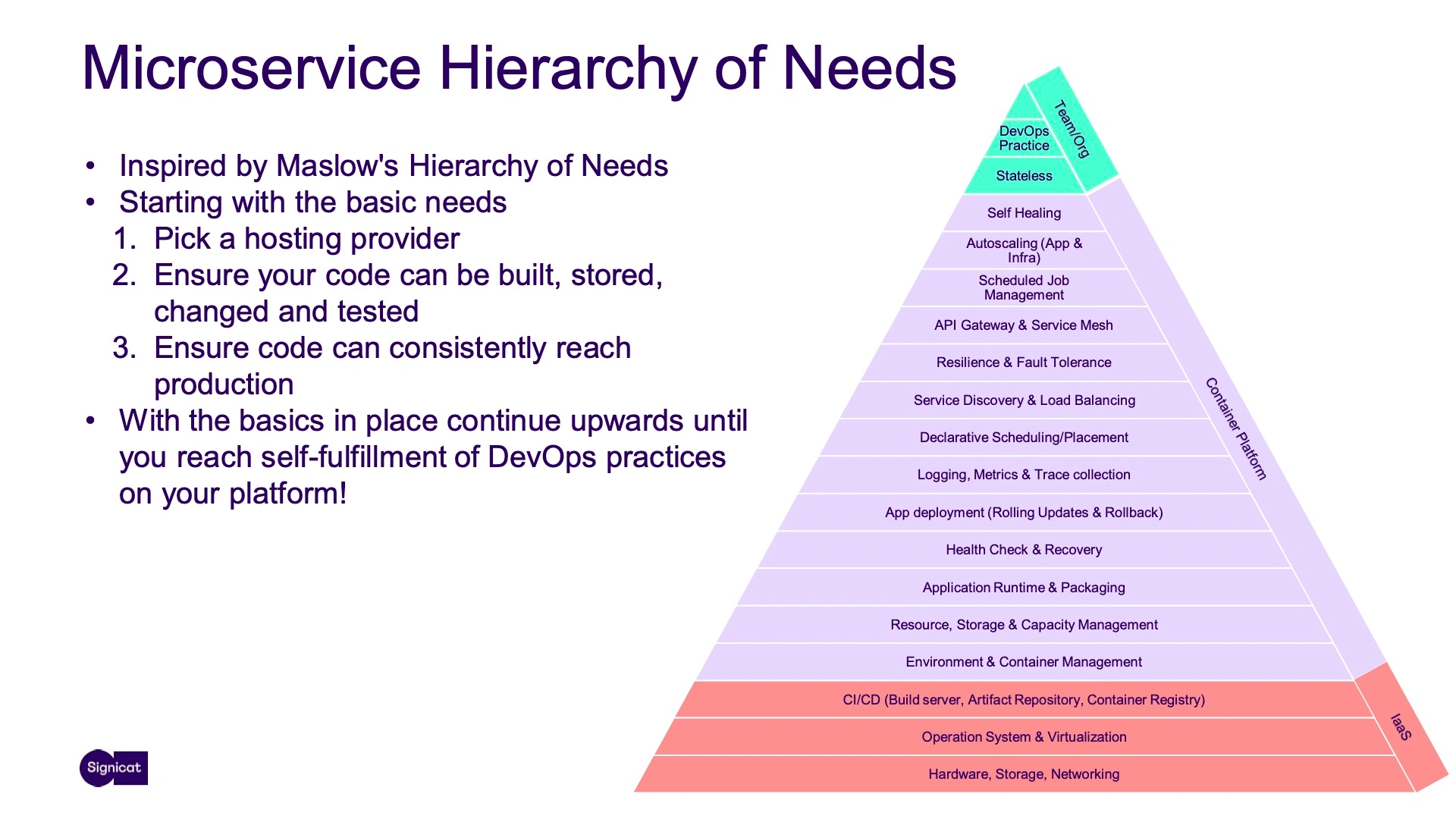
A real-world example
The microservices hierarchy of needs has a clear goal: Building a platform that facilitates the self-fulfillment of DevOps practices. Sometimes this journey involves a lot of trial and error, and what happened at Signicat couldn't have been a better example.
Once upon a time, Signicat started with a single tech stack. It had its pros and cons, but it got the job done. Then the first acquisition came and an entirely new stack along with it.
Then the second acquisition came, bringing two new tech stacks. And there was more to come. Let’s consolidate! Containers! Microservices! Well, as it turns out, standardization on containers and microservices alone are not enough. Far from it.
What did we do? We followed the plan by aiming for the simple basics: Narrowing down from five hosting providers to a preferred one and agreeing on common tooling, like code hosting, CI/CD, and the container platform. Finally, we agreed on a shared organizational definition of a minimum viable platform that people would actually use. Problem solved?
...Or not. Realistically, this kind of thinking turned out to be a fairy tale. For instance, when choosing a hosting provider, we quickly realized that standardizing basic functionality had a huge impact in multiple domains.

For high impact decisions, consensus-powered change management proved extremely useful. Though time-consuming, bringing stakeholders in on the process provided valuable anchoring within the organization and lowered the barriers to entering execution mode as quickly as possible after finalizing each decision. From there, it was a lot easier to roll out the change organically since the stakeholders and early adopters could educate newcomers on why the transition was worthwhile, instead of forcing our central leadership team to keep rehashing the same old arguments.
With the hosting provider problem in particular, we identified a few helpful strategies, including:
Building requirements around verifiably objective criteria (we used RFC-style language) to fight confirmation bias,
Evaluating non-technology criteria, such as cost, support, compliance, and ecosystem integrations,
Appealing to a wider audience of people within the organization by keeping the process as transparent as possible,
Documenting the full journey to the decision, including detours like trade-offs, disagreements, arguments, and counterarguments, and
Explicitly anchoring with the team leaders after making decisions, setting the tone for accelerated execution.
Leveraging these methodologies got the ball rolling far enough for us to implement Kubernetes clusters at our hosting provider, set up code and artifact hosting, and create working CI/CD pipelines. From here on however, the landscape started to get complicated as we added value-added services to really make our container platform production-worthy, like security hardening, log aggregation, alerting, monitoring, and responsibility-oriented boundaries between different teams.
Key design principles
For the Signicat Platform, we wanted something that would help fuel our hypergrowth business. Workflows needed to be consolidated across multiple technology stacks, and services had to adhere to strict security and compliance requirements.

We came up with three core characteristics to guide our decision making, when in doubt about options:
Ease of use for service owners even at the expense of platform owners,
A preference for industry-standard solutions and sticking to the dominant player even if it meant overlooking a "better" option, and
Features that delivered security and compliance by default, avoiding complexity wherever possible to deliver on the ease of use promise.
Security and ease of use
One of the biggest goals of this platform was secure and effective self-service. We wanted to ensure service owners could develop and launch new products without needing to ask anyone on the platform team for permission. This also meant that we must ensure one team's actions could never ruin another group's deployments.

We used our API gateway (Istio) as the responsibility boundary between platform and service owners. Here platform owners operate and secure the gateway, while service owners may configure it to serve their needs. To enable this in a secure way, we created Open Policy Agent (OPA) policies for Gatekeeper to add isolation and ensure teams couldn't overwrite each other's work.
Defining responsibilities
We wanted to make life as easy as possible for service owners, so it made sense to minimize potential confusion by clearly defining who was responsible for what. We created a platform responsibility matrix that served as an overarching design guideline.
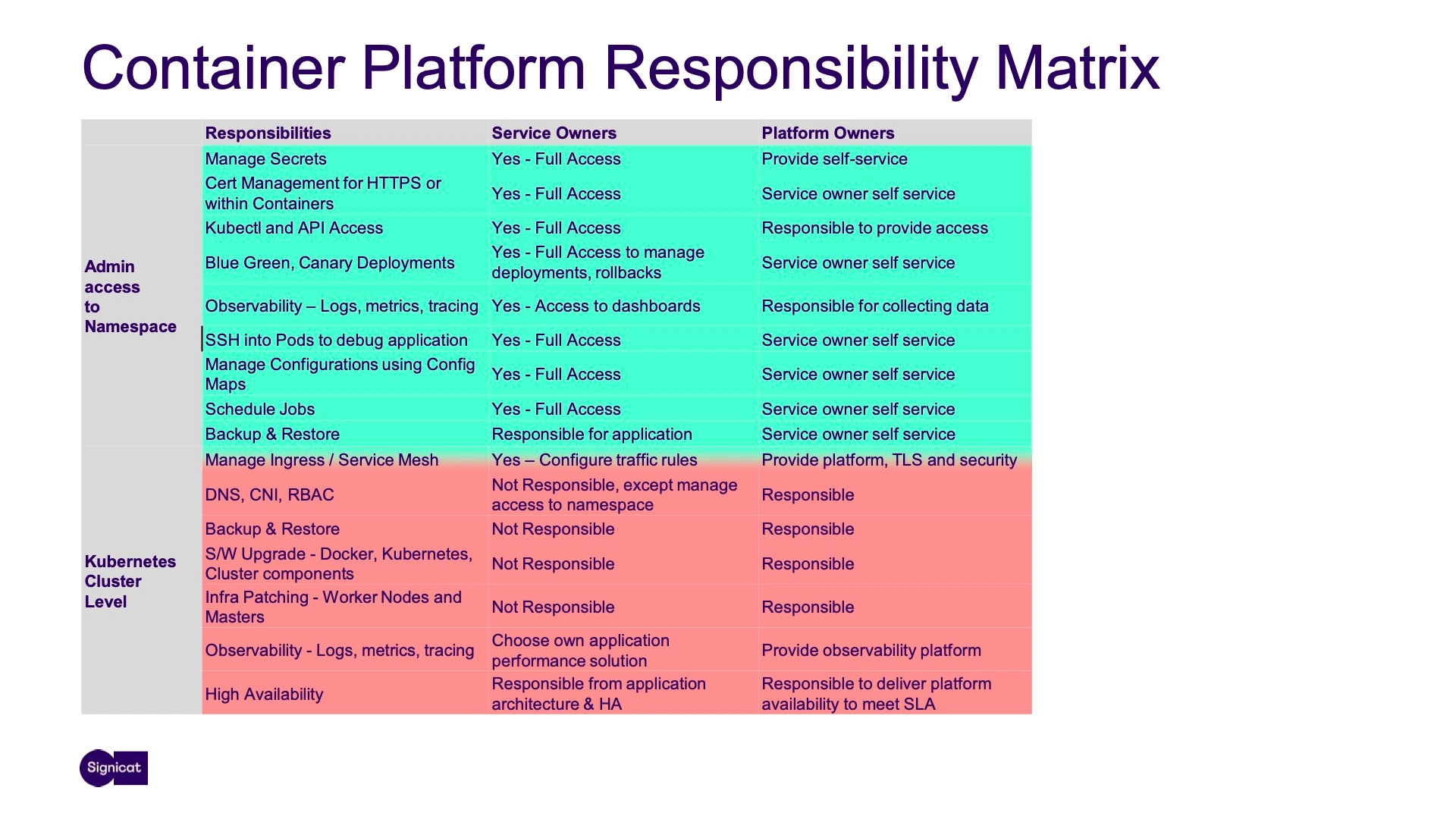
For any given responsibility, we could easily cross-reference our matrix to know what level of access service owners needed and what platform owners were obligated to handle. This helped us take operational considerations in stride by designing platform tooling that promoted self-sufficient workflows – like having service owners be responsible for backing up and restoring their own data.
Pillars of Observability
Building an observability stack doesn't always come easy, and this was no exception. Although it took a few iterations to get this right, we were once again able to succeed by sticking to well-defined designed goals.
In addition to upholding our key principles defined above, we wanted to standardize the observability stack around common tooling and protocols, such as OpenTelemetry. We also aimed for operational efficiency, favoring minimal maintenance workflows and cost optimization measures that could take on the high volume of data we were generating.
This seemed to work well at first, but as we progressed, we realized that our teams didn't need a drill. They needed a hole in the wall, and merely providing them with tools wasn’t sufficient.
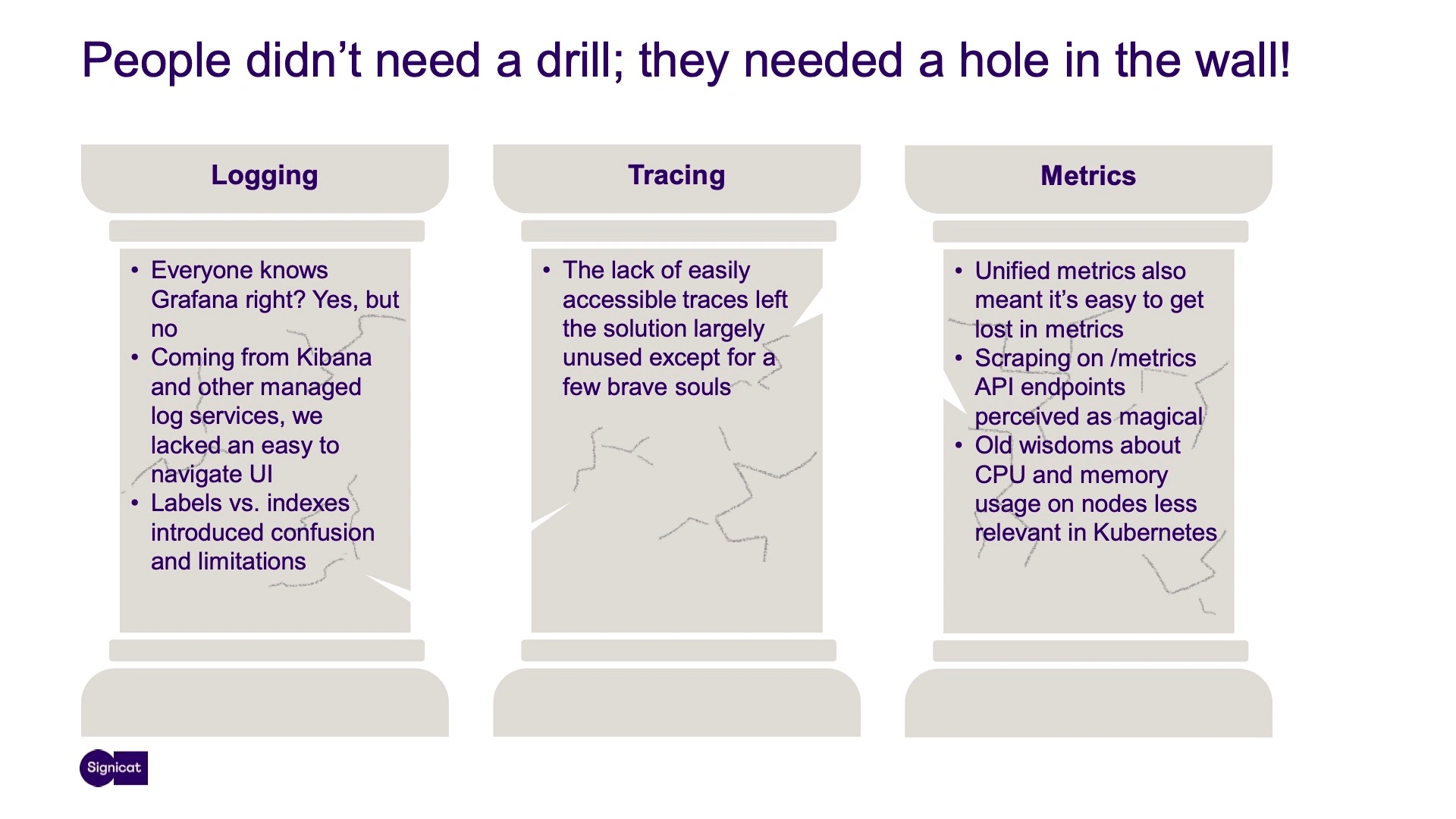
Many of our assumptions proved unfounded, like that everyone knew Grafana well enough to get by. We also mistakenly thought that we could drive adoption successfully without providing easily accessible traces and that our unified approach to metrics was enough to keep users from getting lost in the weeds.
Switching to a batteries-included approach empowered us to fix these deficiencies. We created dashboards for logging, tracing, and metrics with a focus on providing examples, reference implementations, and standardized paths.
Alerting: a study in accommodating user behavior through the transition
We wanted people to use our IDP, and we thought that having an existing alert manager would be a good start. Unfortunately, forcing people to deal with the cognitive overhead of configuring alerts to a different system resulted in it not being used!
Even running workshops and mandating rules didn't help. People weren't fully on board after the training, and setting alerting rules resulted in incorrect usage.

The solution was to create a better alerting system. By triggering alarms in response to customer pain and creating knowledge-base articles describing different alerts, we were able to promote proper responses. This also made it easier to power continuous improvement cycles and learn from what worked, not to mention get early adopters on board and willing to advocate for the cause.
Reaching the top of the pyramid
With our tooling in place, we were ready to tackle the pinnacle of the microservices hierarchy: That shining promise of self-service DevOps practices. While our earlier iterations through different tooling solutions helped drive this pursuit forward in a major way, we also took a few explicit steps to make adoption as painless as possible, including:
Treating our IDP as a product and leverage product management techniques like early movers as reference customers,
Training teams to handle operations on their own, promoting autonomy in mission-critical areas, such as backups, disaster recovery, deployments, and compliance, and
Advocating for the platform via internal presentations, demos, workshops, and reference implementations.
Wrapping up
When architecting an IDP to deliver optimal abstraction levels, avoid the speed/cost/quality trade-off fallacy. Speed, cost efficiency, and quality aren't either-or factors: They build on one another.
Your platform abstractions should aim for the trifecta of obviousness, consistency, and predictability. You want to stick to the principle of least astonishment: All components should behave in expected ways – no surprises that force users to think harder than they should about what comes next.
When in doubt, go with the dominant design, and only use abstractions that provide value by eliminating cognitive overhead. Above all else, remember that customer validation isn't optional: It's the only way to build a platform that delivers real value!
Like this project
Posted Jul 29, 2023
For this piece, I broke down a complex topic based on a webinar, rephrasing the ideas to be more accessible without losing their technical impact.
Likes
0
Views
14
Clients
Humanitec