Employee Performance Analytics Using Python & MySQL
Drashti Patel
Project Overview
I had the valuable opportunity to participate in a live project with HiCounselor, where I collaborated with a team to complete various project modules. This project aimed to leverage a real-world dataset of employee records, allowing me to apply data analytics techniques to solve business problems and uncover valuable insights.
The primary objective of this project was to evaluate the provided dataset thoroughly, extract meaningful information, and address specific business challenges. Throughout the project, I utilized structured query language (SQL) to analyze the real-world database, ensuring I could retrieve the most useful insights from the dataset.
To enhance the project's performance and efficiency, I employed Python for data preprocessing tasks. This involved cleaning, transforming, and optimizing the dataset to improve the quality and reliability of our analysis.
This project provided a comprehensive opportunity for SQL analysis, Python data preprocessing, and extracting insights from real-world databases. It equipped me with practical skills, a strong foundation in data analytics, and a deep understanding of its value for organizations. It showcases my proficiency in delivering actionable insights and making informed decisions through data-driven approaches.
Process of Live Project Execution
Part 1: Data PreProcessing
The first part of the project involved data processing. This involved several steps to ensure data quality and compatibility. Firstly, I imported the dataset's CSV file into a Jupyter Notebook using Python. Then, I utilized Python to remove duplicate rows and eliminate any entries with blank or missing values.
After cleaning the dataset, I proceeded to import the CSV file into phpMyAdmin. This conversion allowed me to transform the data into SQL format, enabling the execution of queries within the Sandbox environment. This process ensured the dataset was ready for further analysis and allowed for seamless integration with the project's analytical workflows.
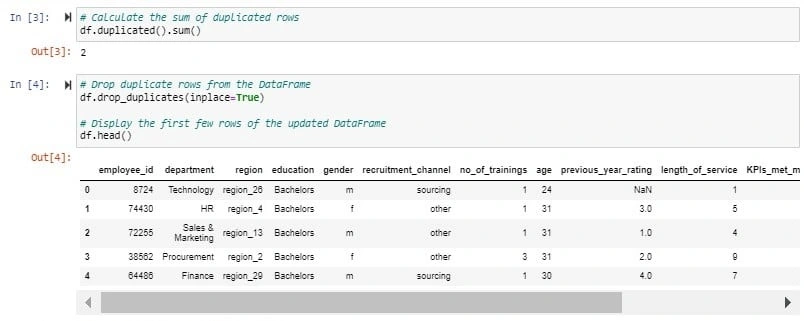
Removing duplicates from the dataset
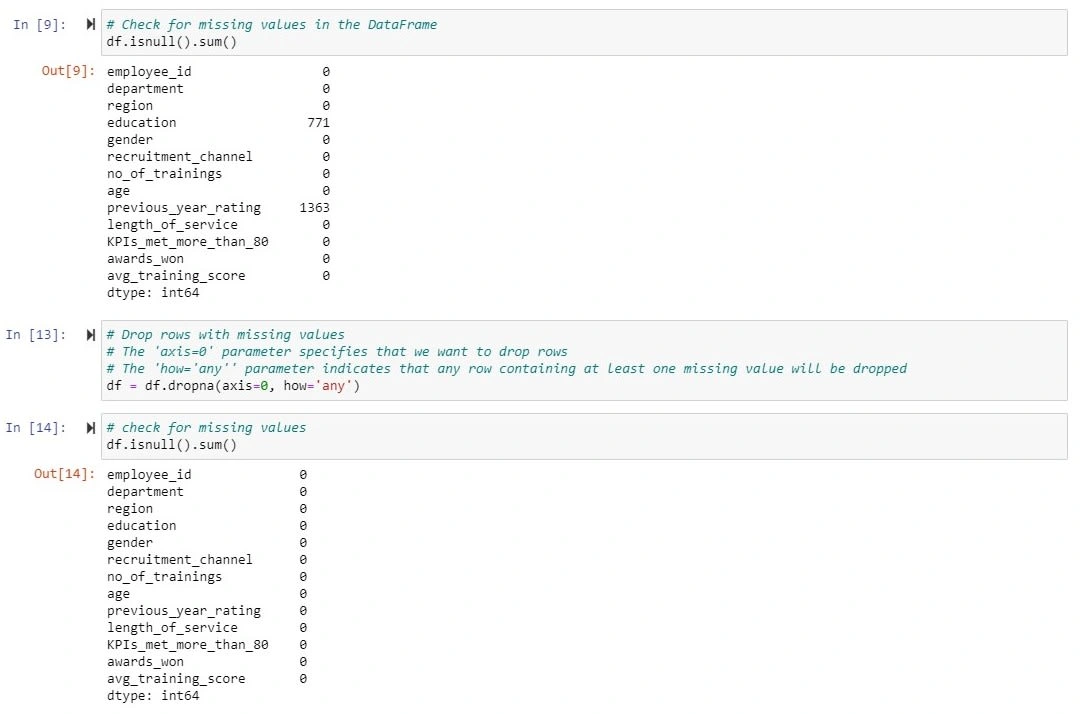
Removing missing values from the dataset
Part 2: Data Analysis
In the data analysis phase of the project, I focused on generating and executing SQL queries on the cleaned dataset. The objective was to address a series of 15 business problems specifically related to the HR dataset. These examples demonstrate my ability to leverage SQL queries to address complex business problems to derive insights and contribute to informed decision-making processes.
1. List the top 3 departments with the highest average training scores.
Output
2. Find the percentage of female employees who have won awards, per department. Also show the number of female employees who won awards and total female employees.
Output
3. List the top 5 recruitment channels with the highest average length of service for employees who have met more than 80% of their KPIs, have a previous_year_rating of 5, and an age between 25 and 45 years, grouped by department and recruitment channel.
Output
Certificate
Like this project
Posted May 12, 2023
Executed SQL queries on HR dataset, solving 15 business problems, to derive valuable insights about employee performance.
Likes
0
Views
251




