Real-Time Music Data Pipeline Using Apache Kafka
Ahmad Kamiludin
Introduction
In this project, we outlined a comprehensive workflow for real-time music data streaming using Apache Kafka, focusing on data from Avenged Sevenfold sourced from Spotify. We covered the setup of the Confluent Platform, creation and management of Kafka topics, and the use of ksqlDB for processing and transforming streaming data with SQL-like queries. We also utilized Kafka Connect to transfer data seamlessly to MongoDB and demonstrated how to visualize this data using Looker Studio connected via CData Connect Cloud. This approach showcases the power and flexibility of modern data streaming technologies, enabling efficient handling and analysis of real-time streaming data for valuable insights and dynamic visualizations in both personal and professional applications.
Architecture
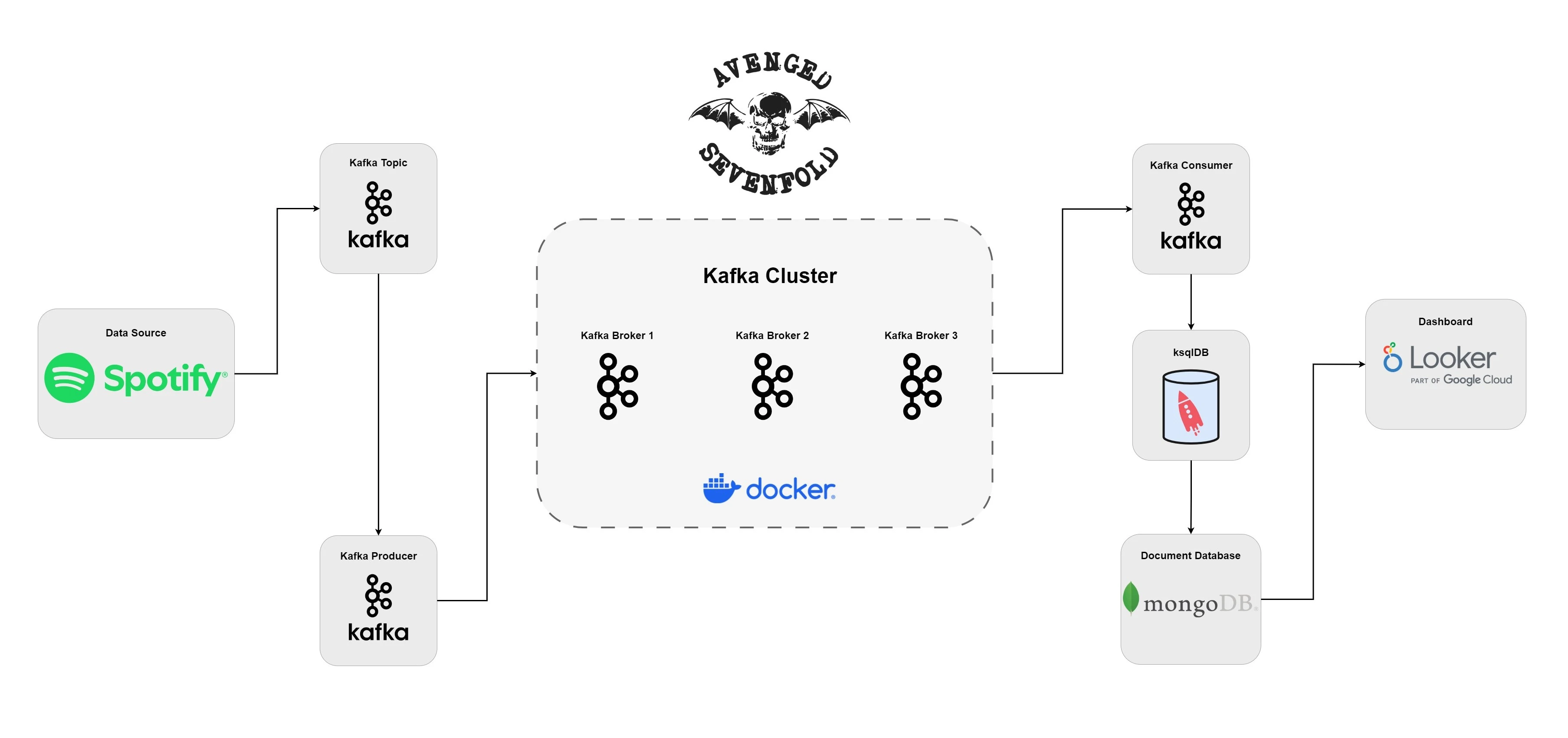
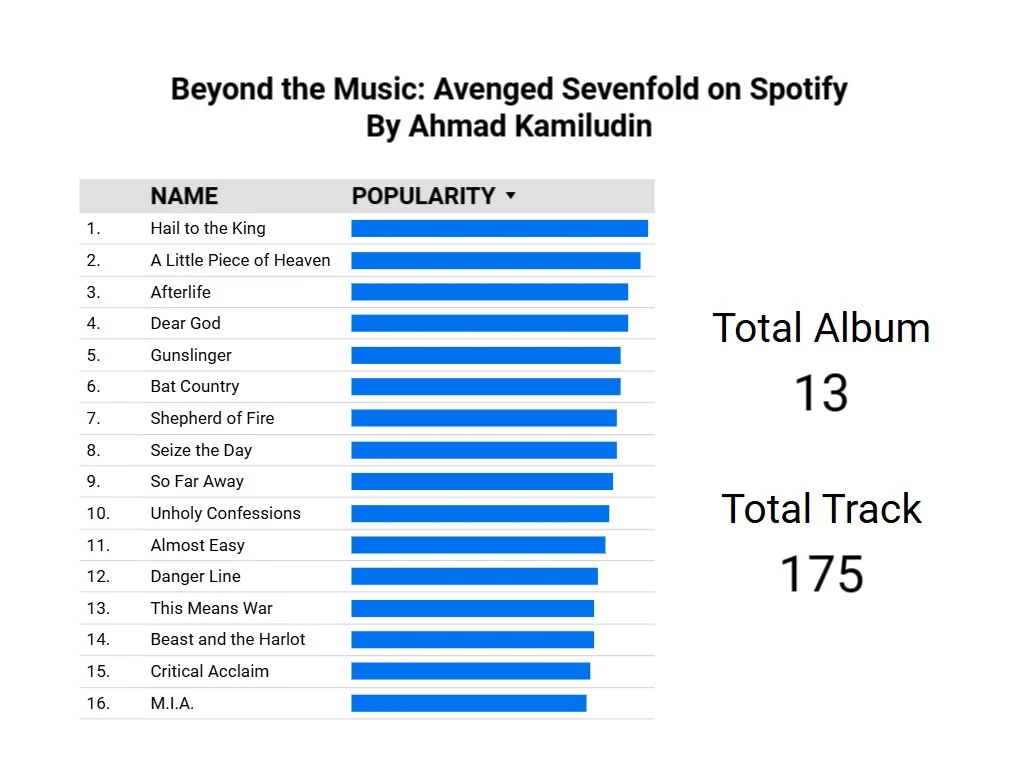
Simple Dashboard
Technology Used
Python
SQL
Apache Kafka
Docker
Looker Studio
Dataset Used
The data used in this project is sourced from the Spotify API and focuses on the band Avenged Sevenfold. The project retrieves comprehensive information about the band, including artist details such as the artist's ID, name, follower count, genres, and popularity. It also collects data on the band's albums, including the album ID, artist ID, name, and release date. Furthermore, the project gathers detailed track information for each album, covering various audio features such as track ID, album ID, name, popularity, danceability, energy, key, loudness, mode, speechiness, acousticness, instrumentalness, liveness, valence, and tempo.
More info about Spotify API: https://developer.spotify.com/
Article About this Project
Like this project
Posted Nov 28, 2024
This article outlines a real-time music data streaming workflow using Apache Kafka with Avenged Sevenfold data from Spotify.
Likes
0
Views
28