V.I.C.T.O.R. Triage Agent
Janelle tamayo
V.I.C.T.O.R.
Catching the heart attacks emergency departments routinely miss.
TL;DR
Heart attacks that don’t look like heart attacks get missed in ER triage, especially in women and underserved patients. I researched 60,000 records to prove the bias, then designed and built a voice-first kiosk that catches the verbal and biomarker patterns clinicians miss under load. Live demo, open-weight model on Hugging Face, real FHIR data into Epic.
Voice-first triage agent for the cardiovascular cases emergency departments routinely miss.

Walkthrough
As a former nurse, I watched heart attacks that didn't look like heart attacks get triaged as low-priority and almost sent home.
The atypical presentations were the most dangerous. A patient would come in with abdominal pain or jaw pain, get triaged as low-priority, and turn out to be in the middle of a heart attack. The pattern was worst in women and underserved patients whose symptoms didn't match the textbook chest-pain script.
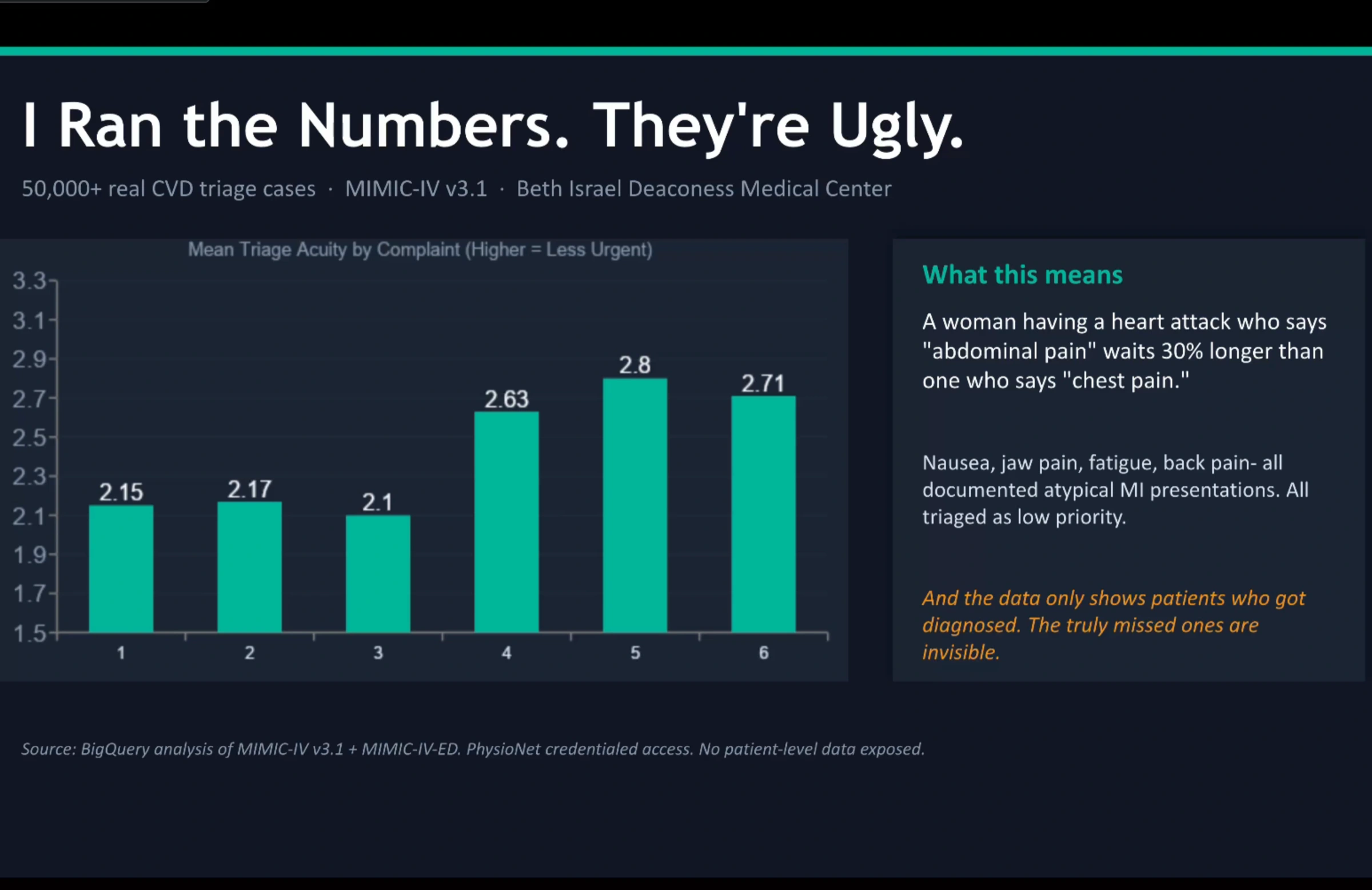
The bias I needed to prove showed up in 60,000 MIMIC-IV records.
I pulled over 60,000 cardiovascular records from MIMIC-IV-ED through BigQuery and Jupyter to check whether the floor instinct held up. The strongest signal: abdominal pain in women averages ESI 2.80, while chest pain in men averages 2.17. Same eventual diagnosis, different initial acuity.
The patients the ED actually missed aren't in the dataset at all.
MIMIC-IV only includes patients who were eventually diagnosed. The ones discharged and never seen again are nowhere in the data, so the real bias is worse than the number itself. That caveat shapes the prompts, the evals, and how I talk about what VICTOR can and can't do.
AI can't generate that context. It has to come from someone who has stood at the triage desk.
I went patient-facing because voice-first wasn't a feature, it was the architecture.
Most AI triage demos go clinician-facing. I built a kiosk the patient speaks to directly, because the concordance signal depends entirely on the patient using their own voice.
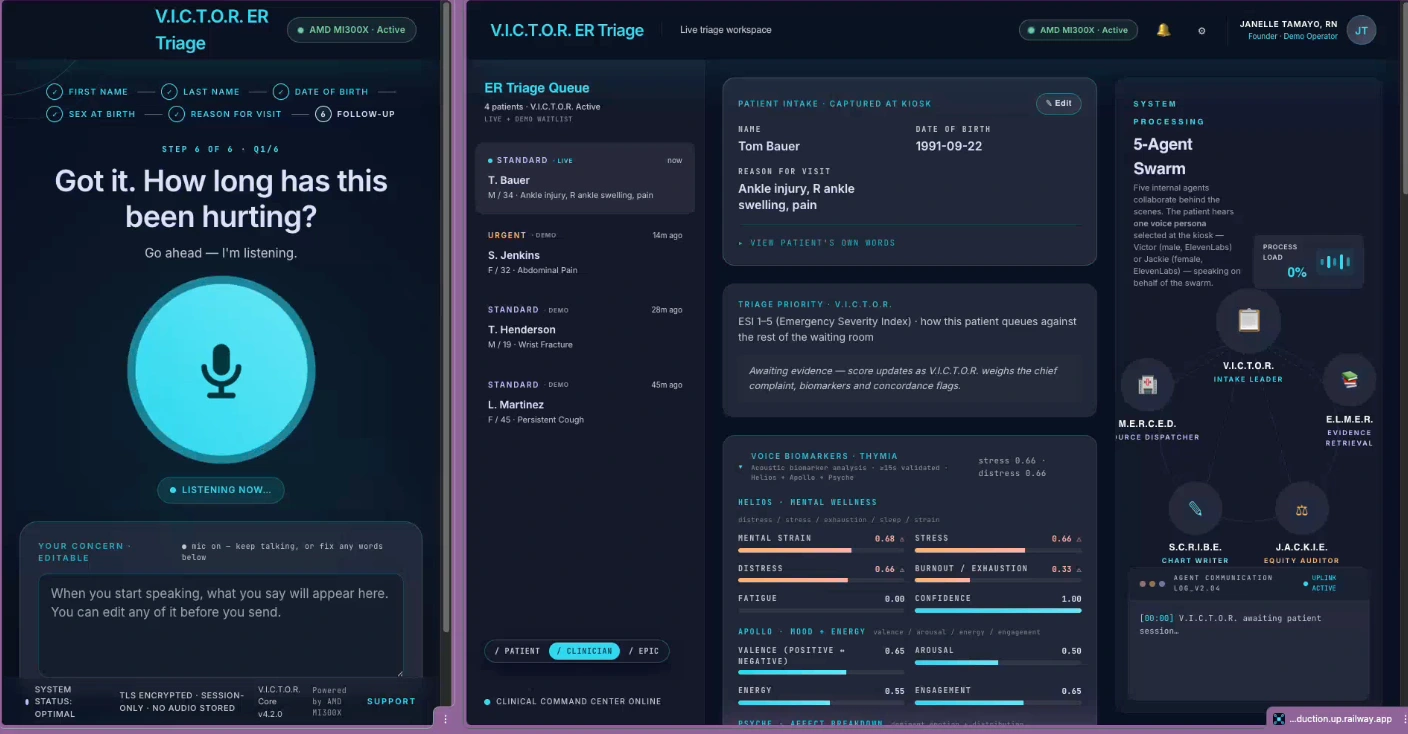
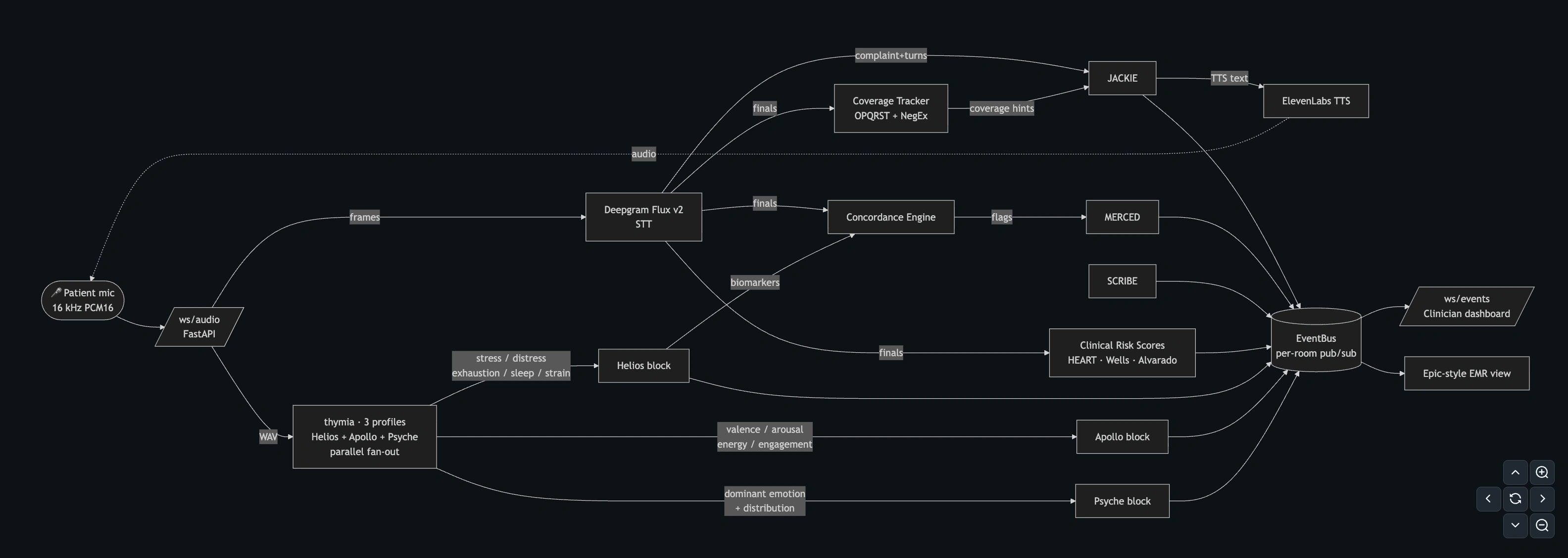
The concordance engine fires only when verbal minimisation and a voice-biomarker breach happen together.
It's a deterministic conjunctive comparator: four tiers of regex patterns gated by a Thymia Helios biomarker threshold that drops from 0.66 to 0.33 when CVD risk factors are disclosed. The flag fires only when verbal minimisation and a biomarker breach occur in the same window, so neither direct chest pain alone nor calm-voiced minimisation triggers it on its own.
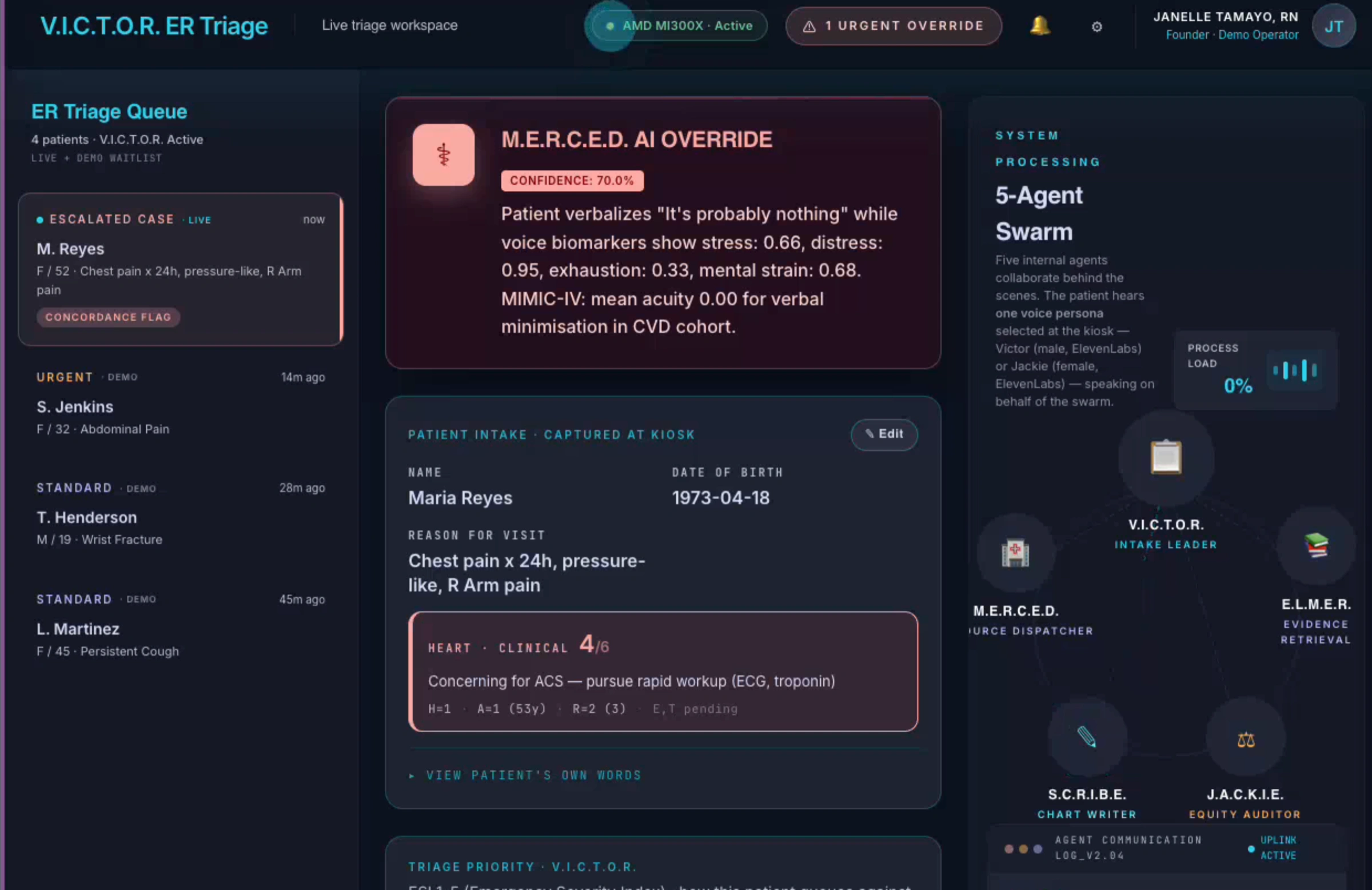
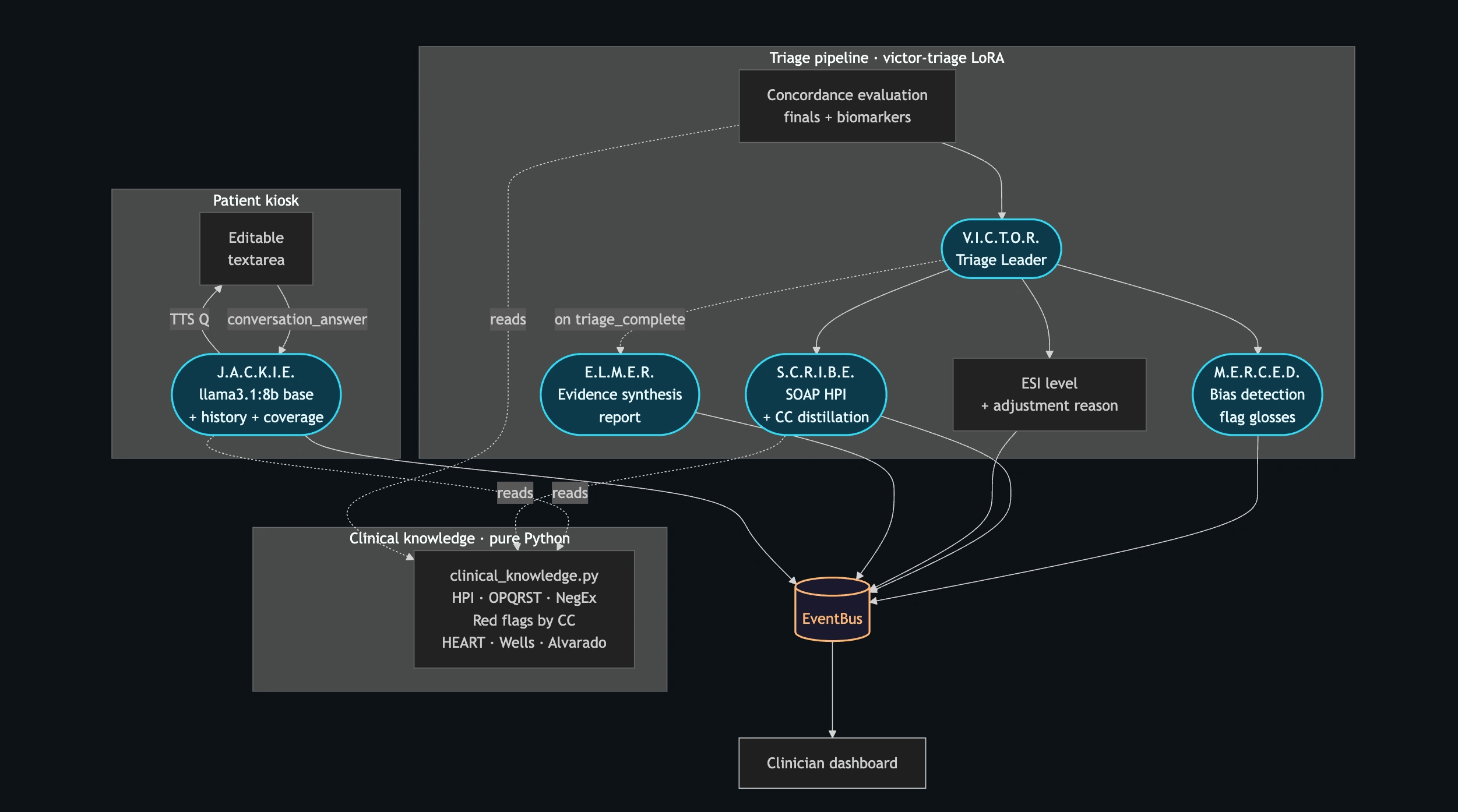
Five agents map to five UI surfaces, so a clinician can audit who did what.
JACKIE runs the patient conversation, SCRIBE writes the SOAP note, MERCED writes the concordance gloss when the engine fires, ELMER produces the evidence report, and VICTOR orchestrates and sets the final ESI. Each agent has its own dedicated panel on the clinician dashboard, so nothing is hidden inside "the LLM."
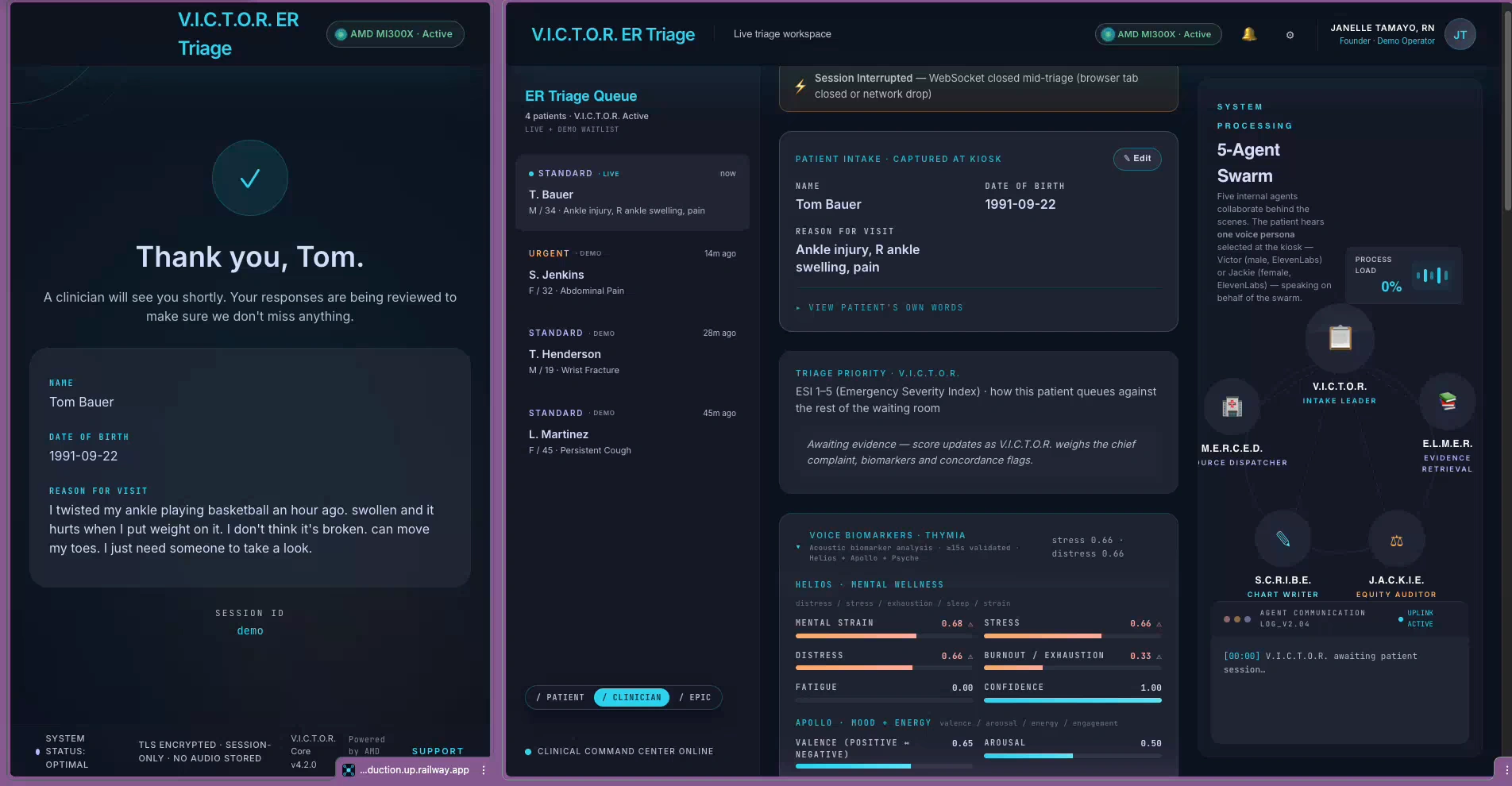
On iteration one, the model asked the patient "Could this be cardiac?" out loud.
JACKIE's system prompt said "ALWAYS ask yourself silently: could this be cardiac?" I meant it as internal reasoning. The LoRA put the question to the patient instead. The pattern dictionary went through about twenty similar adjustments before the engine stopped misfiring.
Four bugs that reshaped the engine:
Cardiac prompt leak. The "ask yourself silently" instruction got spoken aloud. Reworded as a private-reasoning directive.
Tier-2 false fires. Hypertension phrases triggered on any "my BP is fine." Added negation guards and a risk-aware biomarker threshold.
Spanish force-swap. Spanish patients hit the English dictionary first. Moved language detection upstream of the conjunctive comparator.
Two-voices Chrome bug. Chrome ran ElevenLabs TTS and the native synthesizer in parallel. Killed the native voice via Web Speech API.
The Tier-4 verbal-minimisation dictionary evolved across iterations. The first version caught "sorry TO come in" but missed "sorry FOR coming in," which actually fits the apologetic-frame pattern better. "Maybe that's nothing" was added after the third eval pass. Spanish phrases came late, which is what triggered the force-swap bug above. The risk-aware threshold itself, the drop from 0.66 to 0.33 when CVD factors are disclosed, emerged from realising a calm patient with diabetes shouldn't carry the same biomarker bar as a panicked one with no history.
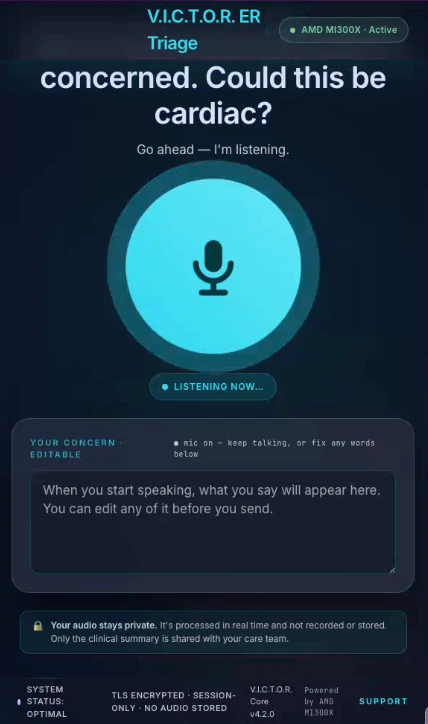
I shipped a turn-cap as a coverage proxy and documented why it was a trade-off.
JACKIE ends the interview at six turns or on an ESI-1 emergency keyword, whichever comes first. The code comment reads "OPQRST coverage typically fits in 6 turns," which is a proxy rather than the real signal. V2 gates on coverage completion directly.
Six turns. A proxy, not the real signal. V2 gates on coverage.
100% sensitivity and specificity on a stratified n=13 eval, including a deliberately adversarial cohort.
The eval set was thirteen cases stratified for atypical presentation and gender bias, plus a "stoic 70-year-old man with classical ACS" cohort the engine correctly does not fire on. The conjunctive design means direct presentations don't trigger the flag, which is the design point. The eval is synthetic and stratified rather than prospective, and that caveat stays visible.
100% sensitivity · 100% specificity · 0.0% FPR · n=13 stratified.
Synthetic stratified eval, no prospective validation.
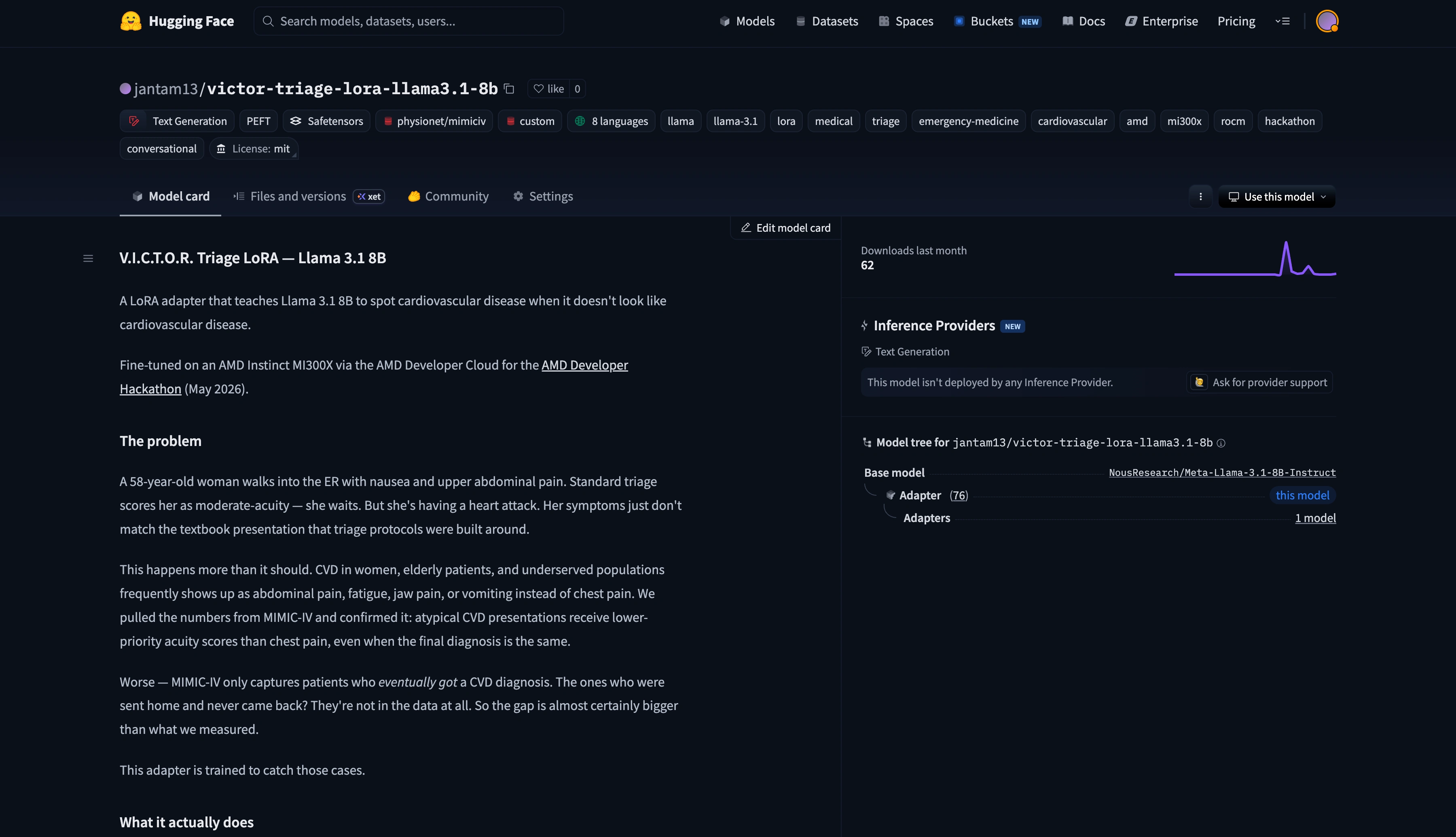
Live demo, open LoRA on Hugging Face, and a real FHIR R4 Bundle into Epic.
VICTOR is deployed on an AMD MI300X GPU behind a Railway frontend. The Llama 3.1 8B LoRA is published openly on Hugging Face. On clinician approval, VICTOR generates a real FHIR R4 Bundle shaped to POST to a live Epic endpoint by swapping one stub function. Every claim above is verifiable from public links.
What I learned, and where VICTOR goes next.
A few honest reflections after the build, and where this project lives after the hackathon.
I should have built the eval harness first. Doing it first would have caught the Tier-4 phrase misses in hours instead of days.
Too much regex was trying to corral a probabilistic model. A smaller deterministic component plus a smaller LLM for prose would have been cleaner.
Commit to multilingual from the start, or commit to English-only. The Spanish force-swap was an afterthought.
The likely next step is clinical research collaboration, not a SaaS startup. The path runs through FDA CDS Software guidance, IRB at a partner ED, and cross-institutional retrospective validation.
The code is MIT-licensed and the LoRA is open on Hugging Face. The README has an open call for clinical advisors.
Roles and Tools
Roles: Researcher, Designer, Developer
Tools: BigQuery, Jupyter, Hugging Face
Like this project
Posted Jun 5, 2026
Voice-first triage kiosk for better identification of heart attacks missed in ER, based on 60,000 medical records.