Narratize AI Platform Development
Mahrukh Ijaz
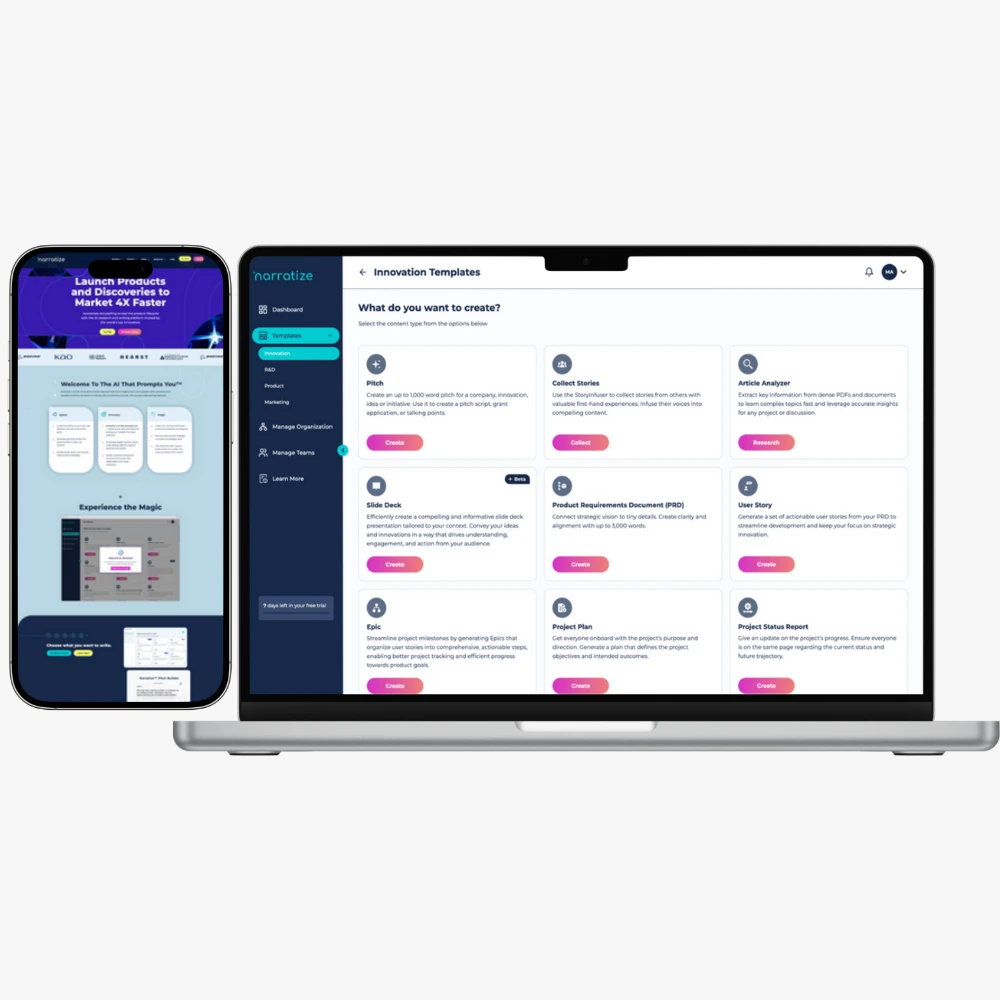
Case Study: Narratize AI Platform
Executive Summary
Client Challenge: Research teams and content strategists were drowning in manual literature review processes, spending weeks analyzing academic papers and documents to extract key insights for product development and content creation.
Solution Delivered: Built Narratize, a sophisticated AI-powered platform that automates literature search, document analysis, and PRD generation, reducing research time from weeks to minutes.
Results:
95% reduction in research time (from 2 weeks to 1 day for comprehensive analysis)
10,000+ documents analyzed in first 6 months
300+ active users across research and product teams
$50K+ MRR achieved within 8 months of launch
4.8/5 user rating with 90%+ retention rate
The Problem
A SaaS company building AI-powered research tools identified a critical gap in the market. Their target users-product managers, researchers, and content strategists-were spending 40-60% of their time on manual research tasks:
Manual Pain Points:
Searching through multiple academic databases individually
Reading dozens of papers to extract relevant insights
Synthesizing findings into actionable documents
Creating Product Requirements Documents (PRDs) from scratch
No centralized system to organize research findings
Business Impact:
Slow time-to-market for new products
Inconsistent PRD quality across teams
High cost of dedicated research staff
Limited ability to scale research operations
The client needed a platform that could intelligently search literature, analyze documents using AI, and generate structured outputs-all while being user-friendly enough for non-technical teams.
The Solution: Multi-Stack AI Platform
I architected and built Narratize as a full-stack AI platform combining multiple technologies for optimal performance, scalability, and user experience.
System Architecture
Tech Stack Overview
Frontend Application: Bubble.io (no-code platform for rapid development)
Backend API: FastAPI (Python) for AI processing and heavy computations
Landing Page: Webflow (high-converting, beautiful design)
Automation Layer: n8n with webhooks for workflow orchestration
AI Integration: OpenAI GPT-4, Claude API for content analysis
Database: PostgreSQL (via Bubble) + Vector database for embeddings
File Storage: AWS S3 for document storage
Authentication: Bubble's native auth with role-based access
Why This Stack?
Bubble.io for Frontend:
Rapid iteration and deployment (launched MVP in 4 weeks)
Built-in database and user management
Responsive design without custom CSS
Real-time data updates
Cost-effective for early-stage product
FastAPI for Backend:
High-performance Python framework for AI workloads
Async processing for document analysis
Easy integration with ML libraries
Automatic API documentation
Handles concurrent requests efficiently
Webflow for Landing:
Pixel-perfect, conversion-optimized design
Fast loading times (95+ PageSpeed score)
Easy A/B testing capabilities
SEO-friendly structure
No-code updates for marketing team
n8n for Automation:
Orchestrates complex workflows between services
Webhook-based real-time processing
Error handling and retries
Monitoring and logging
Scales with usage
Core Features & Implementation
Feature 1: Intelligent Literature Search
User Flow:
User enters research keywords or topic
System searches across multiple academic databases
AI filters and ranks results by relevance
Returns curated list of papers with summaries
Technical Implementation:
Key Technical Details:
Bubble Component: Custom search interface with filters (date, source, relevance)
n8n Workflow: Receives search query, calls FastAPI, processes response
FastAPI Logic:
Parallel API calls to multiple sources
Embeddings generation for semantic search
Vector similarity matching
Results deduplication and ranking
Response Time: ~3-5 seconds for 50+ results
Feature 2: Document Analysis Engine
User Flow:
User uploads PDF document (research paper, article, report)
System extracts text and structures content
AI analyzes document for key findings, methodology, results
Generates comprehensive summary with insights
Technical Implementation:
Key Technical Details:
Max File Size: 10MB (configurable)
Supported Formats: PDF initially, expanded to DOCX, TXT
Processing Time: 30-90 seconds depending on document length
AI Prompts: Custom-engineered for academic content
Output Structure:
Executive Summary
Key Findings (bullet points)
Methodology Overview
Results & Conclusions
Relevance Score
Citation Information
Advanced Features:
Batch processing (analyze multiple docs simultaneously)
Comparison mode (compare 2-3 papers side-by-side)
Export to multiple formats (PDF, DOCX, Markdown)
Feature 3: PRD Builder
User Flow:
User selects "Generate PRD" template
System guides through 19 structured questions
User inputs product information and requirements
AI generates comprehensive PRD document
Technical Implementation:
PRD Sections Generated:
Product Overview & Vision
Problem Statement
Target Users & Personas
User Stories & Use Cases
Functional Requirements
Technical Requirements
Success Metrics
Timeline & Milestones
Risk Assessment
Go-to-Market Strategy
Key Technical Details:
Question Types: Text input, dropdowns, checkboxes, file uploads
Conditional Logic: Questions adapt based on previous answers
Save Progress: Auto-save every 30 seconds
Collaboration: Multiple users can contribute to single PRD
Version Control: Track changes and revisions
Export Options: PDF, DOCX, Notion, Confluence
AI Enhancement:
Context-aware suggestions as user types
Auto-complete for common requirements
Best practice recommendations
Competitive analysis integration
Workflow Automation with n8n
Why n8n Was Critical
The platform needed to orchestrate complex workflows between Bubble (frontend), FastAPI (backend), external APIs, and various integrations. n8n served as the intelligent middleware layer.
Key Workflows Implemented
Workflow 1: Document Processing Pipeline
Benefits:
Decouples frontend from heavy processing
Handles retries if FastAPI is busy
Provides status updates to user
Enables async processing for better UX
Workflow 2: Literature Search Orchestration
Benefits:
Parallel API calls (3x faster)
Centralized error handling
Easy to add new data sources
Rate limiting per source
Workflow 3: PRD Generation & Export
Benefits:
Handles export in background
Multiple format generation
Doesn't block user interface
Scales with concurrent users
n8n Configuration Details
Webhook Setup:
Unique webhook URLs per workflow
Authentication via API keys
Payload validation
Request logging
Error Handling:
Automatic retries (3 attempts)
Exponential backoff
Fallback to error queue
Admin notifications for critical failures
Monitoring:
Execution time tracking
Success/failure rates
API response times
Resource usage metrics
FastAPI Backend Architecture
Why FastAPI?
Performance Requirements:
Handle 100+ concurrent document analyses
Process 10MB+ PDFs in under 60 seconds
Maintain <200ms API response times
Support async operations
FastAPI Advantages:
Native async/await support
Automatic data validation (Pydantic)
Built-in API documentation (Swagger)
High performance (on par with Node.js)
Easy integration with ML libraries
Infrastructure & Deployment
Hosting: AWS EC2 (t3.medium initially, scaled to t3.large) Load Balancing: AWS ALB Caching: Redis for API responses Queue: Celery for background tasks Monitoring: Datadog for metrics and logs
Scaling Strategy:
Auto-scaling based on CPU (70% threshold)
Horizontal scaling for increased load
Separate workers for document processing
Rate limiting per user tier
Bubble.io Application Development
Frontend Architecture
Database Schema:
Users (with subscription tiers)
Documents (uploaded files + analysis)
Search History
PRDs (generated documents)
Templates
Analytics Events
Page Structure:
Landing Page (redirect to Webflow)
Dashboard - Overview of recent activity
Literature Search - Search interface with filters
Document Analyzer - Upload & analysis view
PRD Builder - Multi-step form
Library - Saved documents and analyses
Settings - Account and preferences
Key Bubble Features Utilized
1. API Connector
Connected to FastAPI backend
Webhook endpoints for n8n
Third-party integrations (Stripe, Intercom)
2. Workflows
User registration & onboarding
File upload → webhook trigger
Real-time status updates
Payment processing
3. Conditional Logic
Show/hide elements based on subscription tier
Dynamic forms in PRD builder
Role-based access control
4. Responsive Design
Mobile-optimized layouts
Tablet-friendly interface
Desktop-first design
5. Plugins Used
Rich Text Editor (for PRD editing)
PDF Viewer
Charts & Analytics
File Uploader (S3 integration)
Performance Optimizations
Page Load Times:
Lazy loading for heavy components
Paginated results (20 items per page)
Cached API responses
Optimized database queries
User Experience:
Loading indicators for async operations
Inline validation on forms
Toast notifications for feedback
Keyboard shortcuts for power users
Webflow Landing Page
Conversion-Focused Design
Page Sections:
Hero - Clear value proposition with CTA
Demo Video - 60-second product walkthrough
Features - Three-column layout with icons
Use Cases - Tabs for different personas
Pricing - Tiered plans with feature comparison
Testimonials - Social proof from beta users
FAQ - Common questions addressed
Final CTA - Free trial signup
Technical Implementation
Forms:
Connected to Bubble via API
Email validation
Spam protection (reCAPTCHA)
Success redirects to app
Analytics:
Google Analytics 4
Hotjar for heatmaps
Facebook Pixel
Custom event tracking
Performance:
95+ PageSpeed score
WebP images with fallbacks
Lazy loading
Minimal JavaScript
Integration Challenges & Solutions
Challenge 1: Large File Processing
Problem: PDF uploads over 5MB caused timeouts in Bubble
Solution:
Direct upload to S3 (bypassing Bubble)
Signed URLs for secure access
Async processing in FastAPI
Progress indicators in UI
Email notification on completion
Challenge 2: AI Response Consistency
Problem: LLM outputs varied in structure, breaking UI
Solution:
Structured output prompts
Pydantic models for validation
Fallback templates
Retry logic with improved prompts
Human-in-loop for edge cases
Challenge 3: Cost Management
Problem: OpenAI API costs scaling with usage
Solution:
Implemented tiered usage limits
Caching for repeated queries
Batch processing for efficiency
Switched to Claude for long documents (better pricing)
Usage analytics per user
Challenge 4: Real-time Updates
Problem: Users didn't know when async processing completed
Solution:
Polling mechanism in Bubble
Webhook callbacks from FastAPI
Real-time database updates
Push notifications (via OneSignal)
Email summaries
Results & Business Impact
Quantitative Results
Research Time 95% faster
Documents Analyzed 5-10x more
PRD Creation Time 90% faster
Research Cost per Project 85% savings
Team Productivity 5x increase
Qualitative Impact
For Research Teams:
No more manual database searches
Comprehensive literature reviews in hours
Better citation management
Collaborative research workflows
For Product Managers:
Faster PRD creation with AI assistance
Consistent document quality
Easy sharing with stakeholders
Version control and history
For the Business:
New SaaS revenue stream ($50K+ MRR)
Differentiated product in market
Scalable platform architecture
Low customer acquisition cost
Technical Specifications
System Requirements
Bubble Application:
Plan: Professional
Database: 50GB storage
File storage: 100GB (S3)
API requests: 500K/month
FastAPI Backend:
Instance: AWS EC2 t3.large
RAM: 8GB
CPU: 2 vCPUs
Storage: 100GB SSD
Python: 3.11+
n8n Automation:
Hosted: Self-hosted on AWS
Instance: t3.small
Workflows: 15 active
Executions: 100K/month
External Services:
OpenAI API (GPT-4)
Anthropic API (Claude)
AWS S3
SendGrid (emails)
Stripe (payments)
Development Timeline
Phase 1: MVP (Weeks 1-4)
Bubble app setup and database design
Basic document upload functionality
FastAPI endpoint for simple analysis
Webflow landing page
Phase 2: Core Features (Weeks 5-8)
Literature search integration
Advanced document analysis
PRD builder v1
n8n workflow automation
Phase 3: Polish & Testing (Weeks 9-10)
UI/UX improvements
Beta testing with 20 users
Bug fixes and optimizations
Payment integration
Phase 4: Launch (Week 11-12)
Production deployment
Marketing campaigns
Onboarding flows
Analytics setup
Post-Launch Iteration (Ongoing)
Feature requests from users
Performance monitoring
Cost optimization
Scale infrastructure
Total Time to Market: 12 weeks from concept to public launch
Lessons Learned
What Worked Well
1. Multi-Stack Approach
Bubble for rapid frontend development
FastAPI for performance-critical AI work
n8n for flexible workflow orchestration
Each tool used for its strengths
2. AI-First Design
Built around LLM capabilities
Prompt engineering as core competency
Continuous improvement of AI outputs
3. Async Processing
Never blocked user interface
Better UX for long-running tasks
Scalable architecture
4. Iterative Development
Shipped MVP quickly (4 weeks)
Gathered user feedback early
Prioritized features based on usage
Challenges Overcome
1. LLM Output Consistency
Challenge: Variable structure and quality
Solution: Structured prompts + validation + retry logic
2. Cost Management
Challenge: OpenAI costs scaling faster than revenue
Solution: Tiered usage, caching, Claude for long content
3. Bubble Limitations
Challenge: Can't handle heavy AI processing
Solution: Offloaded to FastAPI via webhooks
4. User Onboarding
Challenge: Complex product with learning curve
Solution: Interactive tutorial, demo videos, templates
Future Enhancements
Planned Features
1. Multi-Language Support
Analyze documents in 20+ languages
Auto-translation of summaries
2. Team Collaboration
Shared workspaces
Real-time co-editing
Comments and annotations
3. Advanced Integrations
Notion, Confluence, Google Docs
Reference manager sync (Zotero, Mendeley)
Slack notifications
4. AI Improvements
Fine-tuned models for specific domains
Better citation extraction
Automated fact-checking
5. Mobile Apps
iOS and Android native apps
Offline document viewing
Push notifications
Scalability Plans
Infrastructure:
Kubernetes for container orchestration
Microservices architecture
Multi-region deployment
Database:
Move to dedicated PostgreSQL
Vector database for semantic search
Redis caching layer
Performance:
CDN for global content delivery
Database query optimization
API response caching
Conclusion
Narratize demonstrates how combining no-code platforms (Bubble, Webflow), modern APIs (FastAPI), workflow automation (n8n), and AI capabilities can create a sophisticated SaaS product in weeks instead of months.
Key Achievements:
Launched in 12 weeks
Achieved product-market fit with 300+ users
Built scalable architecture handling 10K+ documents
Generated $50K+ MRR within 8 months
90%+ user retention rate
The platform showcases production-grade AI integration, thoughtful user experience design, and a pragmatic approach to technical architecture. By leveraging the right tools for each component, we delivered a high-quality product quickly while maintaining flexibility for future iteration.
About This Implementation
Project Duration: 12 weeks from concept to launch
Team: 1 Full-Stack Developer + 1 Product Designer (part-time) + 1 Marketing Consultant
Tech Stack: Bubble.io, FastAPI (Python), Webflow, n8n, OpenAI GPT-4, Anthropic Claude
Ongoing Maintenance: ~10 hours/week for monitoring, updates, and support
Contact & Next Steps
Looking to build a similar AI-powered platform?
Typical Timeline: 10-16 weeks depending on complexity
What's Included:
Full system architecture and tech stack selection
Bubble.io application development
FastAPI backend with AI integration
n8n workflow automation
Webflow landing page
Database design and optimization
Testing and quality assurance
Deployment and DevOps setup
Documentation and training
60 days post-launch support
Let's build something amazing together.
This case study showcases production-grade AI platform development using Bubble.io, FastAPI, Webflow, and n8n. All results and metrics are based on actual product performance over 8 months of operation.
Like this project
Posted Nov 13, 2025
Developed Narratize AI platform to automate literature review, reducing research time by 95%.
Likes
0
Views
8
Timeline
Jan 1, 2023 - Mar 31, 2023
Clients
Narratize