RAG-Based Enterprise Support Chatbot Development
Devansh Sahni
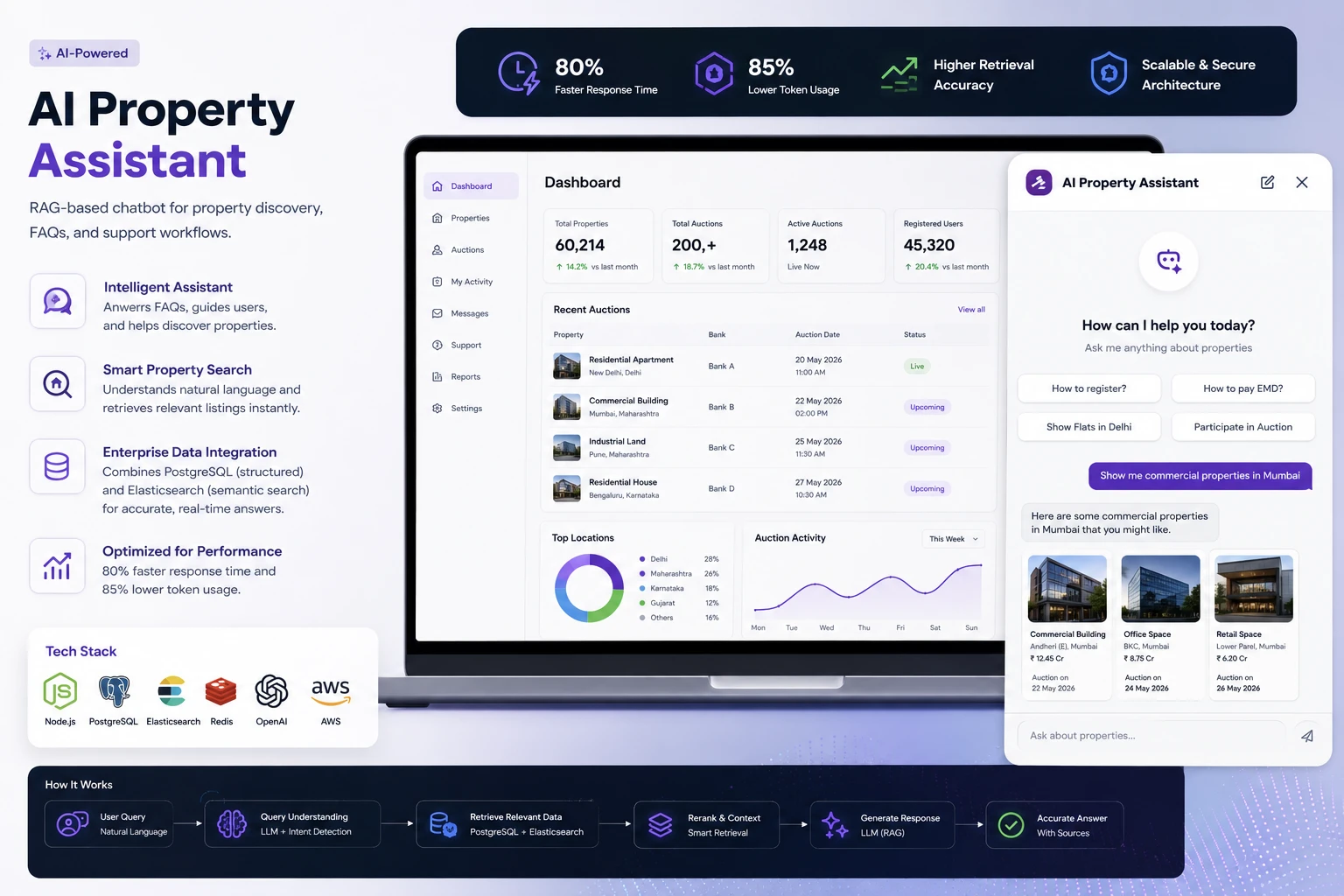
RAG-Based Enterprise Support Chatbot
Overview
Designed and built an AI-powered assistant for a platform to improve user support, discovery, and operational efficiency.
The chatbot combined Retrieval-Augmented Generation (RAG), PostgreSQL, and Elasticsearch to handle:
FAQs
Search workflows
Grievance redressal
User support interactions
Context-aware listing retrieval
The system was optimized for fast response times, scalable retrieval, and efficient token usage for production deployment.
Problem
Users interacting with large-scale property and auction platforms often struggle with:
Discovering relevant listings quickly
Understanding auction participation workflows
Accessing accurate support information
Navigating complex enterprise processes
Traditional support systems created operational overhead and delayed user resolution times.
The goal was to build an intelligent assistant capable of:
Retrieving accurate property and FAQ data
Supporting conversational search workflows
Scaling efficiently for production traffic
Minimizing latency and AI infrastructure costs
My Role
AI / Backend Engineer
I designed and built:
RAG architecture and retrieval pipelines
Context-aware search workflows
Elasticsearch + PostgreSQL integrations
AI orchestration logic
Prompt optimization pipelines
Performance and token optimization systems
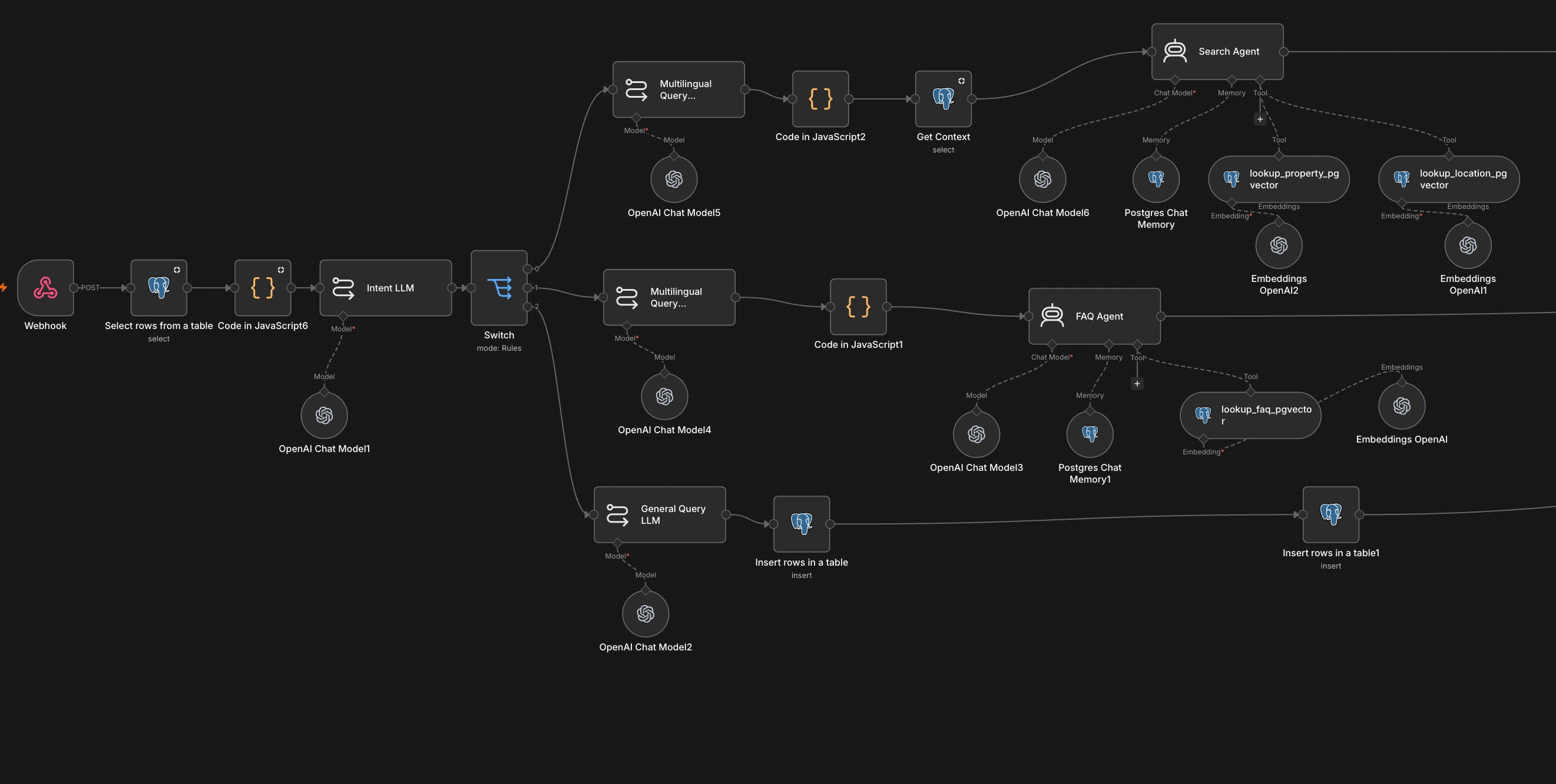
N8N chatbot Langchain Flow
What I Built
RAG-Based Retrieval Architecture
Designed a Retrieval-Augmented Generation (RAG) system integrating:
PostgreSQL for structured data
Elasticsearch for semantic and listing retrieval
LLM orchestration workflows
Context-aware response generation
The assistant dynamically routed queries between:
FAQ retrieval
Property search workflows
Auction support flows
General conversational assistance
Intelligent Property Discovery
Built conversational listing retrieval workflows enabling users to:
Search properties naturally
Discover listings contextually
Retrieve auction information conversationally
Navigate support workflows efficiently
AI Workflow Optimization
Implemented optimization pipelines that:
Reduced response time by 80%
Reduced token usage by 85%
Improved retrieval precision
Minimized unnecessary LLM calls
This significantly improved production efficiency and reduced operational AI costs.
Scalable AI Infrastructure
Built scalable orchestration workflows handling:
Query routing
Context retrieval
Search agent execution
FAQ handling
Multi-step conversational flows
The system architecture was designed for extensibility and enterprise-scale deployment.
Tech Stack
Node.js
N8N
PostgreSQL
Elasticsearch
OpenAI APIs
AWS
RAG Architecture
LLM Orchestration Workflows
Challenges
Reducing Hallucinations
The assistant needed reliable retrieval pipelines to ensure responses remained grounded in enterprise data and property listings.
Balancing Speed & Accuracy
The system had to remain conversationally fast while still retrieving relevant listing and FAQ data accurately.
Optimizing AI Costs
Production-scale AI systems can become expensive quickly. The architecture required aggressive token optimization and intelligent retrieval routing.
Multi-Source Retrieval
Combining structured database retrieval with semantic search workflows required careful orchestration and ranking logic.
Outcome
Built a production-ready AI assistant
Reduced support response time by 80%
Reduced token consumption by 85%
Improved property discovery workflows
Enabled scalable conversational support for enterprise operations
Like this project
Posted May 17, 2026
Developed an AI support chatbot using RAG, improving response time by 80% and reducing token usage by 85%.