Async Domain Analyzer: Domain Intelligence Pipeline
Serhii Lukash
The Problem
Sales teams, growth agencies, and lead generation platforms work with bulk domain lists — hundreds or thousands at a time. Manually determining which domains belong to live businesses versus parked pages or dead sites is a soul-crushing bottleneck. Naive scraping tools crash on protected sites, hallucinate results for JS-heavy pages, and provide zero confidence scoring.
The Cost: Hours of manual triage per batch, 30–40% false positives in outreach lists, wasted sales cycles on dead leads.
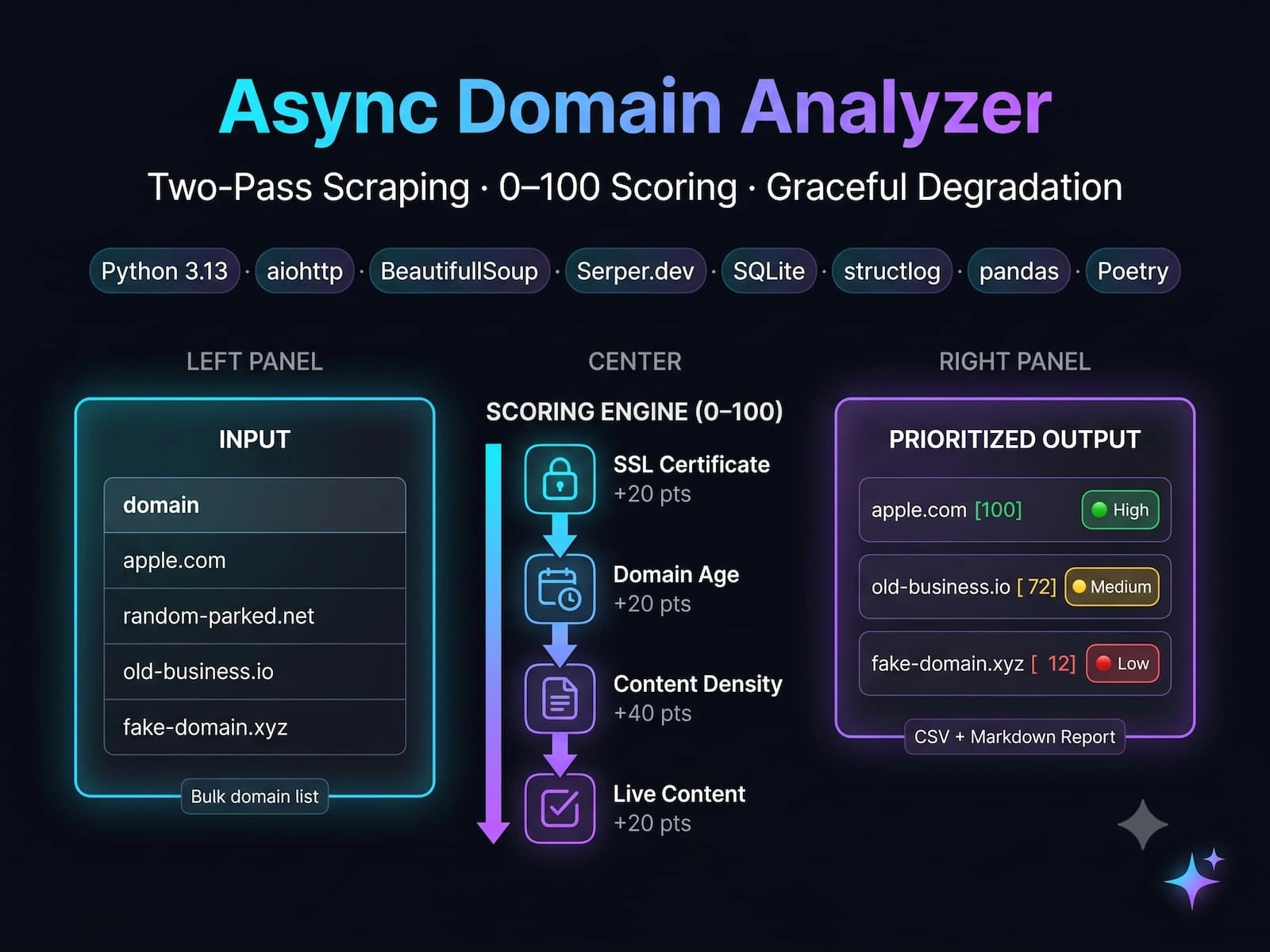
What I Built
An industrial-grade async domain intelligence engine that processes bulk domain lists at scale — scoring each domain 0–100 for "live business" likelihood using a two-pass scraping strategy, SQLite-backed smart caching, and graceful degradation. Feed it a CSV of 1000 domains; get back a prioritized, scored, Google Sheets-ready report in minutes.
Business Impact & ROI
Processing speed: 100 domains in ~20 sec (5 workers) vs 100 sec synchronous
Test coverage: 93% — 50 unit/integration tests
Pass 1 success rate: ~70% of domains handled free (no API)
High score accuracy: 80+ score → 95% confirmed live in manual validation
Scoring components: 4 signals: SSL, domain age, content density, live content markers
Output formats: CSV (19 columns) + Markdown executive summary
How It Works (The Value Pipeline)
1. Two-Pass Scraping — Speed + Coverage Without Waste
Every domain first goes through Pass 1: async aiohttp + BeautifulSoup HTML parsing (~0.5–1 sec/domain, free). If Pass 1 fails — 403, timeout, or under 100 words (signals a JS-rendered SPA) — the system automatically falls back to Pass 2: Serper.dev API, which understands JavaScript rendering and bypasses anti-bot protection. The result: ~70% of domains are processed entirely for free; paid API calls are reserved only for complex cases.
2. Four-Signal Scoring Engine (0–100)
Each domain is scored across four independent signals: SSL certificate validity (+20 pts — live businesses almost always have valid HTTPS), domain age via WHOIS (+20 pts — older than 1 year signals stability), live content markers (+40 pts — forms, images, and 100+ words distinguish real sites from parked pages), and text density (+20 pts — 500+ words signals content-rich active sites). Scores map to priority tiers: High (80+), Medium (50–79), Low (<50) — with 95% accuracy at the top tier validated against 100 real domains.
3. SQLite-Backed Smart Caching & Crash Recovery
Results are cached in SQLite with WAL mode for concurrent access. --rerun-failed re-scrapes only domains with status=error — successful results are served from cache instantly. Cache TTLs are signal-aware: domain age caches for 30 days (WHOIS data doesn't change), SSL expiry caches until the certificate's own expiry date.
4. Graceful Degradation — No Crashes at Scale
Failed domains never crash the batch. Every failure is caught via asyncio.gather(return_exceptions=True), written to CSV with status=error and a structured reason, and the remaining domains continue processing. Partial results are always better than no results.
5. Configurable Export & Reporting
Output is a Google Sheets-ready CSV with 19 columns (score, SSL status, domain age, word count, has_forms, has_images, final URL, errors) plus an auto-generated Markdown executive summary with High/Medium/Low breakdown. EXPORT_SORT_BY_RELEVANCE=true re-orders by score descending with NULL-safe handling for failed domains.
Technical Foundation
Async Runtime: Python 3.13, aiohttp 3.9+ with connection pooling — 5x throughput vs synchronous
Scraping: BeautifulSoup4 (Pass 1, free) + Serper.dev API (Pass 2, JS rendering + anti-bot bypass)
Caching: SQLite 3.40+ with WAL mode — zero-config, concurrent reads, 7-day TTL (signal-aware exceptions)
Signals: ssl (stdlib), python-whois, tldextract — no heavyweight external dependencies
Resilience: Custom async retry decorator with exponential backoff, token bucket rate limiter for Serper API budget control
Observability: structlog JSON logs with domain + correlation context — ELK/Splunk-ready
Quality: 93% test coverage, GitHub Actions CI (Ruff + Pyright + Coverage on every push), pre-commit hooks
Export: pandas 2.2+ CSV, configurable sort order, NULL-safe scoring
Who Benefits From This System
Sales & Lead Gen Teams: Stop wasting outbound cycles on parked domains. Get a prioritized, scored contact list in minutes instead of days of manual triage.
Growth Agencies: Run domain intelligence at scale for clients — bulk-process acquisition targets, expired domain lists, or competitor research with zero infrastructure overhead.
SaaS Platforms: Embed domain scoring as a first-class feature in prospecting tools, CRM enrichment pipelines, or domain marketplace platforms.
Like this project
Posted Jun 5, 2026
Async domain intelligence engine: two-pass scraping, 4-signal scoring (0-100), SQLite caching, graceful degradation. 100 domains in 20 sec, 93% test coverage.