Swiggy Distance Service
Ayush Bagla

Image source:
Online food ordering is so easy these days. Open Swiggy, tap a restaurant, create a cart and place your order. Little does one know that in order to make this a delightful and hassle-free experience for the customer, from opening the app to delivering the order, a lot goes on behind the scenes.
Distance and time to travel between two locations are unarguably the two most important things that are heavily used in Swiggy’s ecosystem. These values are used to:
fetch the distance of restaurants in the vicinity from a customer’s location and list the serviceable restaurants
determine the food delivery times
find the delivery executives and assign the most suitable one
figure out if two orders lie on a similar route and batch them
Current Solutions
We currently use Google Distance Matrix API (GDMA) primarily to fetch distance. A single API key has usage limits to fetch only 1000 origin-destination pairs per second, which are very small for our business, although we can cache (and we do!) these distance values for a maximum up to 30 days
Whenever we exhaust our GDMA usage limits, we fallback to Open Street Maps (OSM). We have found that distances provided by OSM deviate from actual distances by more than 10% and we eventually end up using not so accurate distance values
Why are we building this?
Depending upon the use case from the ones mentioned above, every service was implementing its own way to fetch distance using GDMA (using a shared API key) and OSM. There was inconsistency in distance values between different services for the same customer.
Since the same GDMA client key was shared among multiple services, they had unforeseen impact on each other and skewed usage limits
Since every service had its own implementation of GDMA and GDMA cache, there was very high redundancy on hitting same requests to GDMA, leading to earlier exhaustion of GDMA limits
Swiggy is growing fast. The faster we grow, the more difficult it gets in terms of distance accuracies, if we stick to the existing solution because all the extra calls will go to OSM
So, there was a high need of a common service that would manage distance values for entire Swiggy and ensure better accuracies.
Approaching the problem
Caching the distance values at a very large scale (hundreds of billions of point-to-point distance pairs) was the most difficult challenge that needed to be addressed before starting to design this service. Storing distance from every possible Geo location to other Geo locations that we need in the areas we serve, is practically impossible.
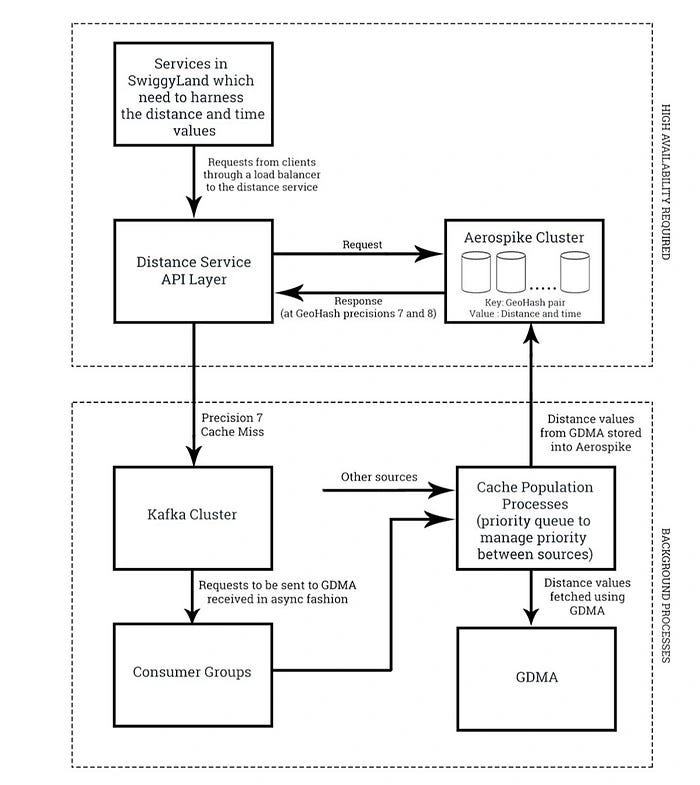
So, we decided to split the Swiggy planet into cells which would serve as the smallest unit of geography in our ecosystem. The cell unit which will be born now should form the base of every other service, algorithm, and analysis that works in the context of geographies. Anything that worked upon geographies was linked to finding the distance between these cells at its core. It was soon realized that anything that works as a unit cell for distance service would easily work as the unit cell for any other service (owing to fundamental need of accurate distance values)
For distance service, the requirement for defining the unit cell was very simple. Distance from any point in one cell to another point in the second cell should not differ significantly for any pair of points between these two cells. We decided to go with geohash to accomplish this task and divide the Swiggy planet into cells. The next task was to decide the precision of the unit geohash cell to be adopted.
There were two major contenders among the precisions to be used as the unit cell. They were namely precision 7 and precision 8.
Precision 7 is a square cell of dimensions roughly 150m x 150m
Precision 8 is a rectangular cell of dimensions roughly 19m x 38m
Distances which differ by values in the range of precision 8 cells were readily accepted by us for our operations. More the precision more is the granularity and more is the accuracy.
Another point to notice was that we breach our GDMA throughput limits mostly during peak times (which is lunch and dinner times for us). Can we do something to uniformly distribute our requests to Google Maps and make the most out of our API plan?
Designing the service
Selecting the data store:
To store the cell to cell distances from GDMA as an adjacency matrix, or more precisely as key-value pairs where the key would be a unique combination of origin and destination geohash addresses and value would comprise of distance and time, a scalable and highly reliable database was needed.
In order to store data at this huge scale along with high-performance requirements, we required a distributed in-memory database. After a few iterations, we locked down with two options in hand; Redis and Aerospike. Redis being a very mature database had an upper hand over Aerospike before even starting to compare them on any criteria.
When we started comparing Redis and Aerospike head to head, Aerospike seemed a better option for our service because of the reasons mentioned ahead. Aerospike being multithreaded offered higher queries-per-second compared to Redis per server node (which means a lesser cost of the cluster). Also, Aerospike comes with auto-sharding, auto-rebalancing, and auto-clustering, resulting into easier management and less development time, the primary reason to select Aerospike as the underlying database for this service.
After choosing Aerospike as our data store, the focus was on how to optimize our GDMA request calls and store them. Majority of our distance queries involved restaurants at either end (as an origin or a destination) of the query. So, it made more sense to pre-cache these values involving restaurants. Wait, what would we choose at the other end of the origin-destination pair? Since those restaurants are serviceable only in their vicinity up to a specified distance, all the cells lying in the haversine distance of a circle with specified serviceable radius keeping restaurant geohash cell as the center was a way to go.
A very crude estimate will tell us that it would require around 500 GB (feasible for us) of memory to store this data for all restaurant-cell pairs at precision 8. And time to pre-cache it would take around 45 days (1000 elements limit from GDMA is a bottleneck here). This even surpasses our 30-day cache allowance and the gap would be more as we scale our business. So, a hybrid approach of storing our distance values at Precision 7 and Precision 8 was the only smart option left to go with. For precision 7, these numbers were around 15 GB of memory and almost a day to pre-cache them all. Rest 29 days of cache bandwidth can be used to store more frequently fetched distance pairs at precision 8 and to fetch pairs, which do not include restaurants as one of the end points in the query.
Now, to uniformly distribute our GDMA queries, precision 8 queries (a major consumer of our GDMA bandwidth left) were not fetched in real time, but these requests were pushed into a Kafka topic and were forwarded to GDMA in a background process. This way, we very smartly avoid overloading our requests to GDMA at peak times and make the most out of our GDMA plan (especially at night times when none of the service hits GDMA).
This service at Swiggy caters the need of more than 15 million distance queries per minute at peak with the help of more than a billion key value pairs in the Aerospike cluster.
— Post contributed by Ayush Bagla, Software Developer at Swiggy
Like this project
Posted May 6, 2024
Online food ordering is so easy these days. Open Swiggy, tap a restaurant, create a cart and place your order. Little does one know that in order to make this …


