Out of Harm's Way – AI-Powered Code Security MLOps System
Ayesha Javed
It started with 20 hours of 𝐅𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠…
inside Kaggle’s 30-hour/week GPU limit.
Initially, I experimented with models, tuned parameters, and monitored logs.
But soon it became something deeper:
-I started saving checkpoints before every crash,
-planning runs like experiments with constraints,
and rebuilding pipelines every time things broke.
And somewhere in that process…
I stopped thinking in terms of models and started thinking like an 𝐌𝐋𝐎𝐩𝐬 𝐞𝐧𝐠𝐢𝐧𝐞𝐞𝐫 designing a full system under limitations.
(𝐎𝐮𝐭 𝐨𝐟 𝐇𝐚𝐫𝐦'𝐬 𝐖𝐚𝐲)
V1
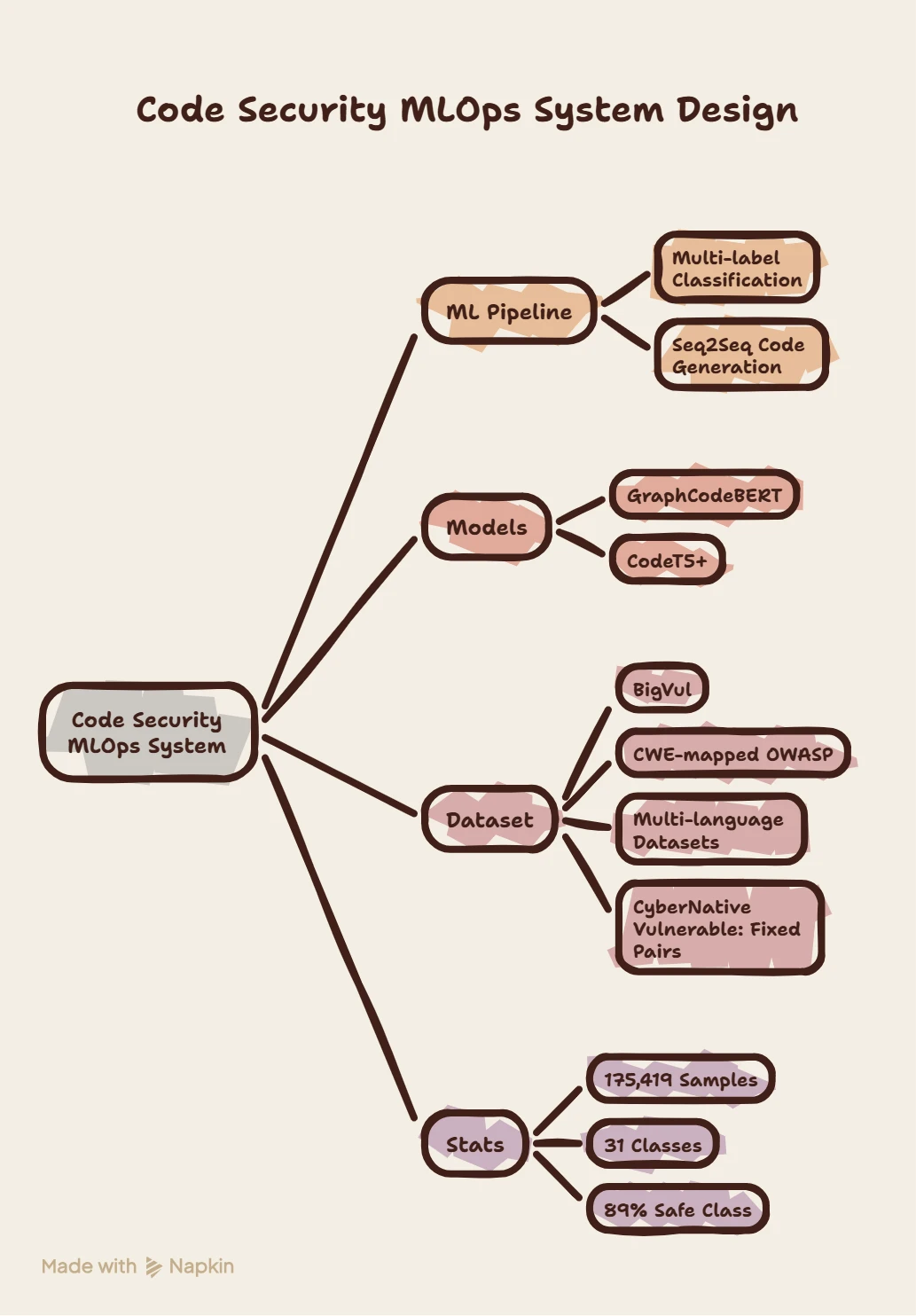
I built a 𝐂𝐨𝐝𝐞 𝐒𝐞𝐜𝐮𝐫𝐢𝐭𝐲 𝐌𝐋𝐎𝐩𝐬 𝐬𝐲𝐬𝐭𝐞𝐦 for two tasks:
-Vulnerability detection
-Automatic fix generation
This is a two-stage ML pipeline:
-𝐌𝐮𝐥𝐭𝐢-𝐥𝐚𝐛𝐞𝐥 𝐜𝐥𝐚𝐬𝐬𝐢𝐟𝐢𝐜𝐚𝐭𝐢𝐨𝐧 (𝟑𝟏 𝐂𝐖𝐄 𝐜𝐥𝐚𝐬𝐬𝐞𝐬)
-𝐒𝐞𝐪𝟐𝐒𝐞𝐪 𝐜𝐨𝐝𝐞 𝐠𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧
"𝘋𝘦𝘵𝘦𝘤𝘵 𝘸𝘩𝘢𝘵’𝘴 𝘸𝘳𝘰𝘯𝘨 𝘪𝘯 𝘤𝘰𝘥𝘦 𝘢𝘯𝘥 𝘨𝘦𝘯𝘦𝘳𝘢𝘵𝘦 𝘢 𝘴𝘢𝘧𝘦 𝘧𝘪𝘹."
Models I Used:
-𝐆𝐫𝐚𝐩𝐡𝐂𝐨𝐝𝐞𝐁𝐄𝐑𝐓 (~𝟏𝟐𝟓𝐌, 𝐄𝐧𝐜𝐨𝐝𝐞𝐫)
-𝐂𝐨𝐝𝐞𝐓𝟓+ (𝟐𝟐𝟎𝐌, 𝐄𝐧𝐜𝐨𝐝𝐞𝐫–𝐃𝐞𝐜𝐨𝐝𝐞𝐫
Dataset:
Merged ~𝟏𝟕𝟓𝐊 𝐬𝐚𝐦𝐩𝐥𝐞𝐬 from:
-BigVul (real CVE vulnerabilities)
-CWE-mapped OWASP datasets
-Multi-language datasets (Python, JS, Java, PHP, Go)
-CyberNative vulnerable: fixed pairs
Stats:
175,419 samples
31 classes (30 CWEs + safe)
~89% safe class → severe imbalance
Challenges:
Extreme class imbalance (rare CWEs <10 samples)
Mixed real + synthetic data
Language bias (C/C++ dominant)
Long-tail distribution issues
Fine-Tuning Strategy:
Two-phase training (freeze -> unfreeze)
Asymmetric Loss (ASL) for imbalance
Sigmoid multi-label heads
Temperature scaling (~0.6163)
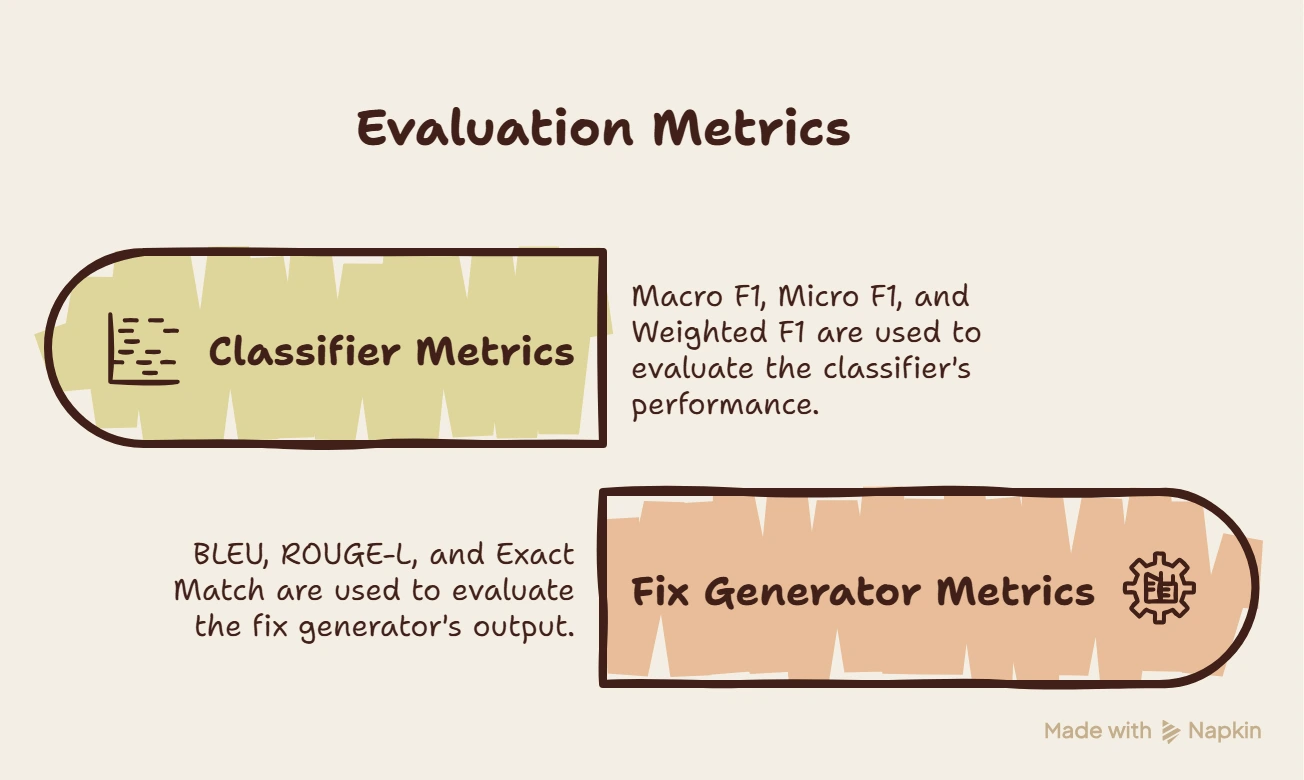
For evaluation:
𝐂𝐥𝐚𝐬𝐬𝐢𝐟𝐢𝐞𝐫:
-Macro F1 (0.476) (weak on rare CWEs, strong impact of imbalance)
-Micro F1 (0.943) (strong overall performance, dominated by frequent classes)
-Weighted F1 (0.945) (inflated due to safe class dominance ~89%)
𝐅𝐢𝐱 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐨𝐫 (𝐂𝐨𝐝𝐞𝐓𝟓+):
-BLEU (81.0) (high semantic similarity, not guaranteed correctness)
-ROUGE-L (0.78) (good overlap with reference fixes)
-Exact Match (1.4%) (low exact correctness, most outputs differ from ground truth)
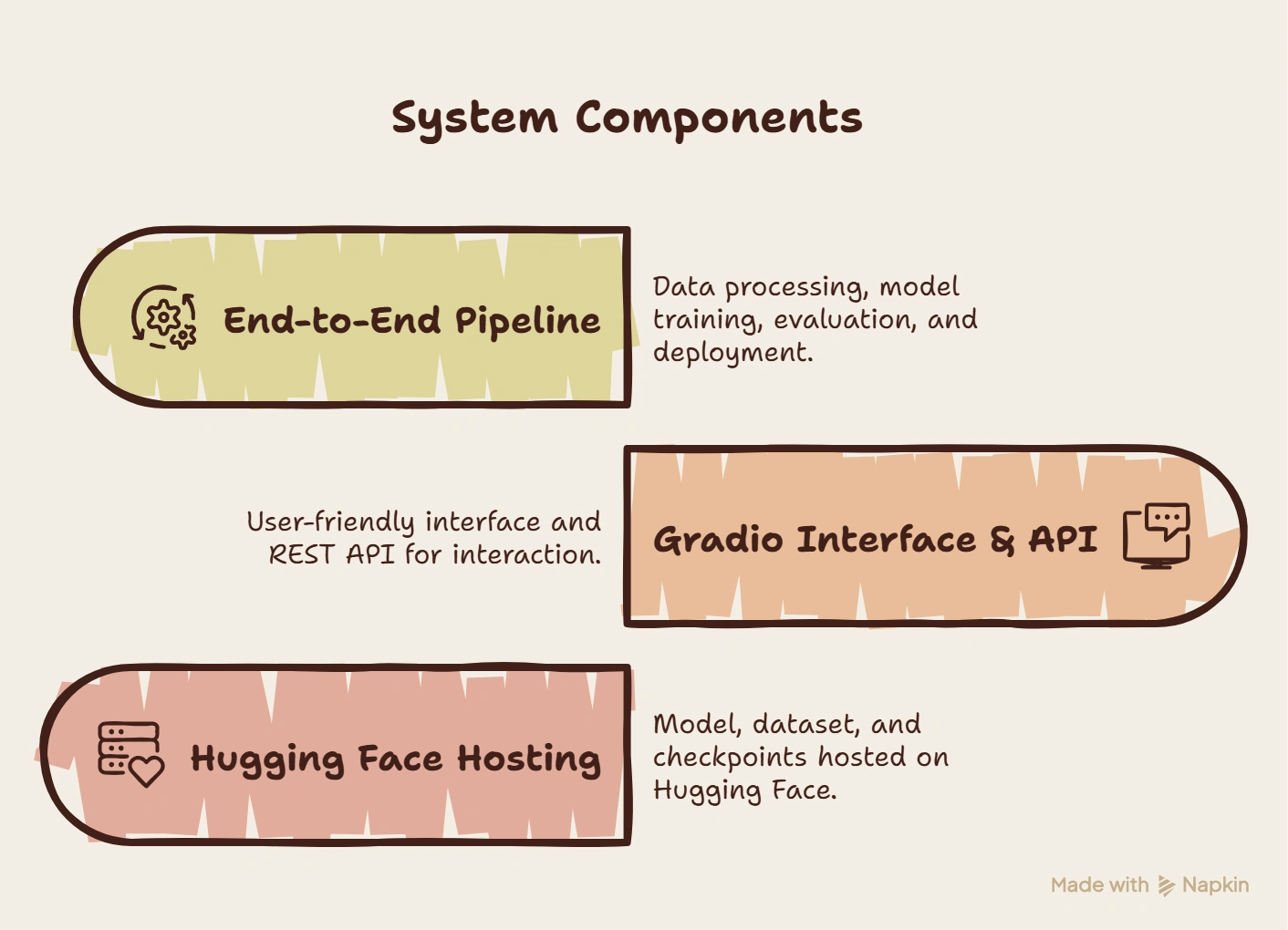
I built a full system:
End-to-end pipeline (data → train → eval → deploy)
Gradio interface + REST API (/analyze, /get_json_report)
Model + dataset + checkpoints hosted on Hugging Face
It's not perfect, but I am enjoying the process!
Results so far:
5𝟎𝟎+ 𝐝𝐨𝐰𝐧𝐥𝐨𝐚𝐝𝐬 𝐚𝐜𝐫𝐨𝐬𝐬 𝐦𝐨𝐝𝐞𝐥𝐬 𝐚𝐧𝐝 𝐝𝐚𝐭𝐚𝐬𝐞𝐭𝐬
Learned a lot and am still learning.
Next Version:
Hybrid system → Rule-based + ML + LLM integration
Not a production system but a complete learning system.
Not perfect, not final, but worth it. Every epoch didn’t just improve the model, it reshaped how I think..
#MLOps #MachineLearning #DeepLearning #LLMs #NLP #CodeSecurity #AI #GraphCodeBERT #CodeT5 #Transformers #HuggingFace #Kaggle #DataScience #SoftwareEngineering #AIEngineering #EndToEndML #Modeling #AIProjects
Like this project
Posted Jun 30, 2026
Engineered an end-to-end MLOps pipeline using GraphCodeBERT & CodeT5+ to detect software vulnerabilities and generate AI-powered code fixes.