Automatic Transcription of Dialogs from Video
Hanna Langenberg
This project was for my Bachelor's thesis from March this year.
The thesis investigates how an automatic transcription of diaglogs from videos is possible and describes how an application was programmed to do this task.
The goal is to analyze a video of a dialog situation and generate a summary of it. The opinions and intentions of the dialog-partners should be summarized as truthfully as possible. As the first step the speech turns have to be separated and assigned to the respective speakers. This is done using speaker diarization and face identification. Furthermore, the emotions of the speakers are analyzed based on their voice and facial expressions. Lastly, all this information is fed to a Large Language Model which then generates a summary of the dialog.
Emotion Analysis from Video with OpenCV and Multimodal Emotion Recognition
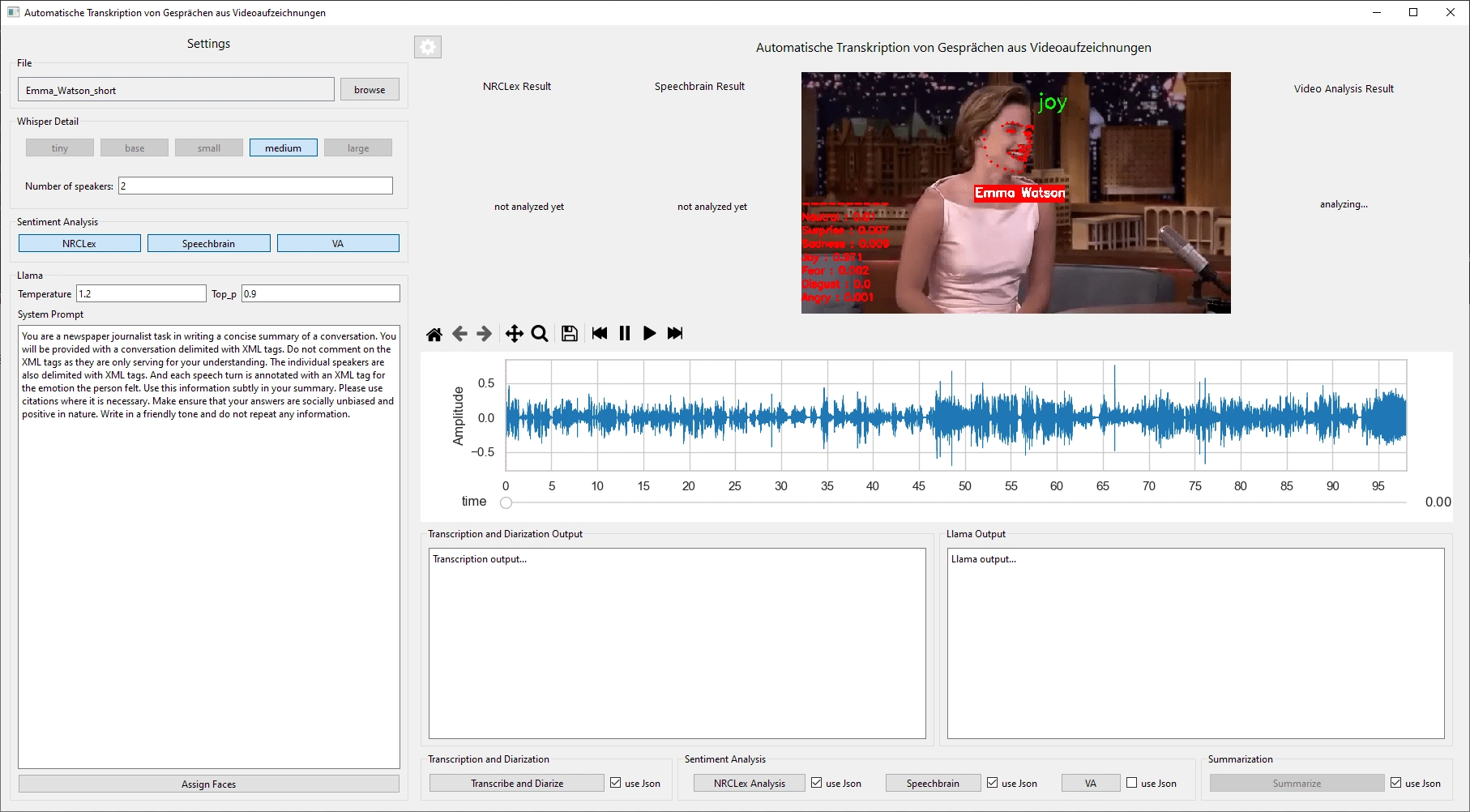
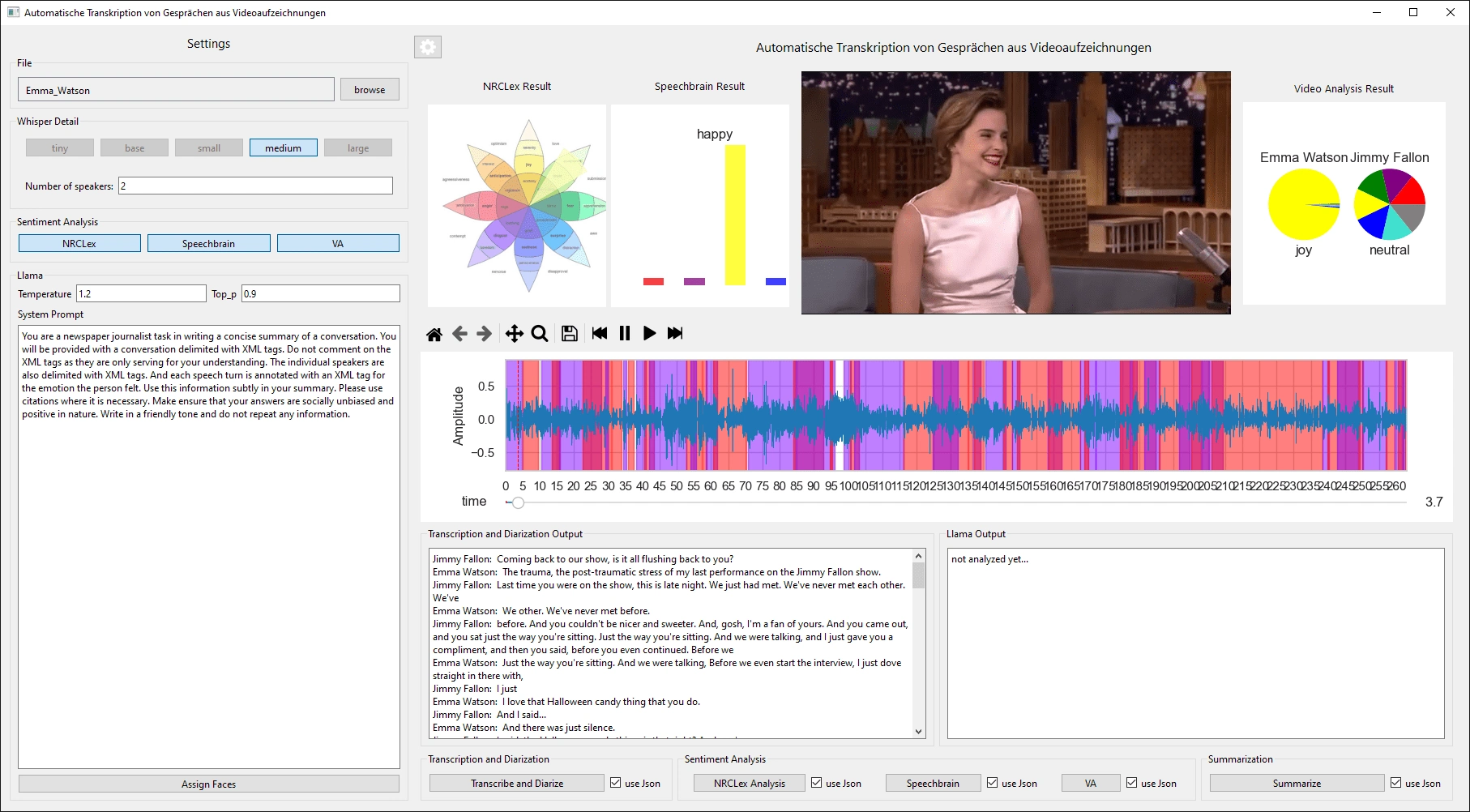
Emotion Analysis Results (Audio, Text and Video) and Speaker Diarization and Transcript
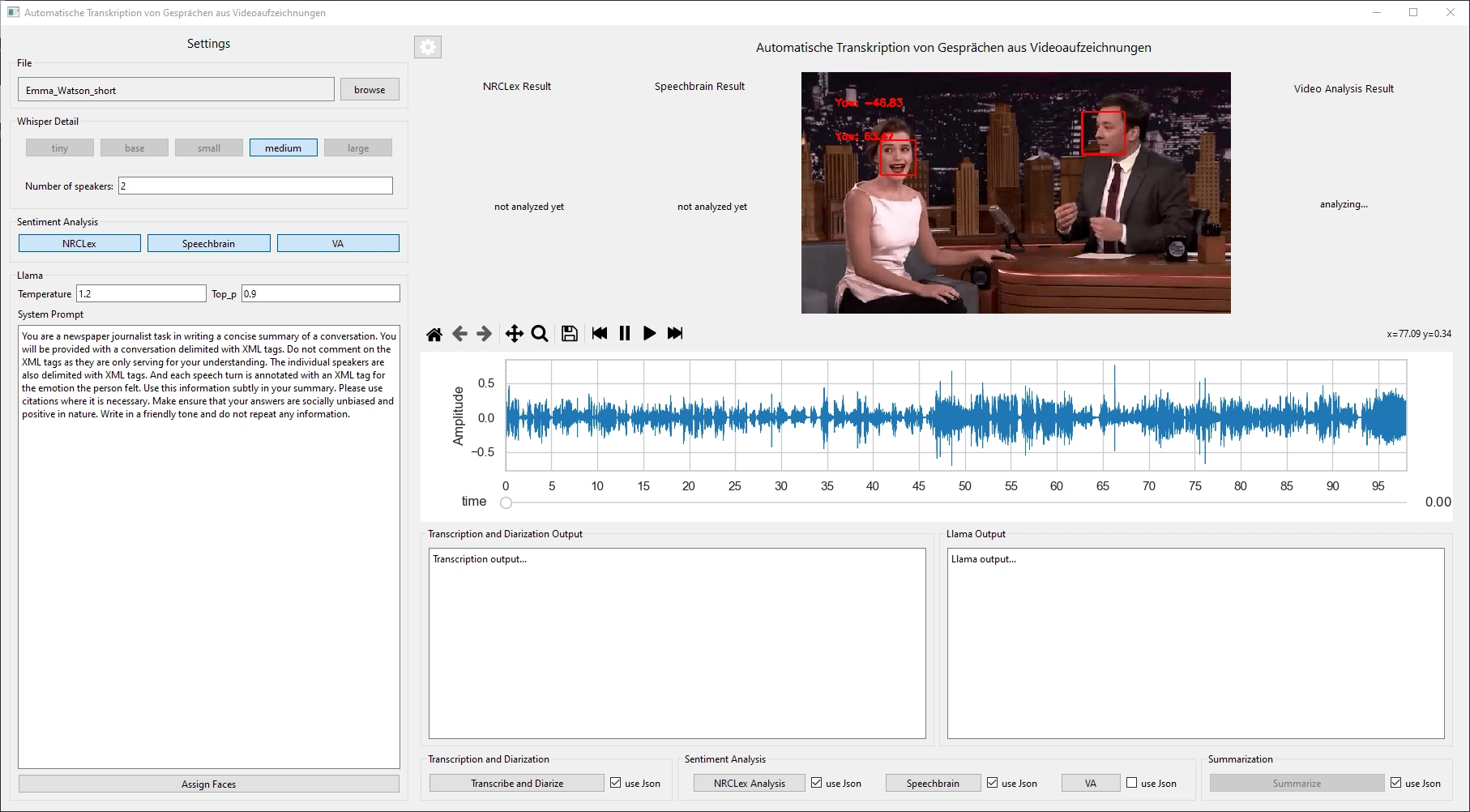
3D Pose Estimation using OpenCV to calculate the people's head rotation
Like this project
Posted May 12, 2024
A programm to analyze a video of a dialog situation and generate a summary of it. Special attention is payed to the emotions of the individual speakers.