AI Agent Workflow Development with Python & TypeScript
Wahyu Ikbal
Building AI Agent Workflows with Python & TypeScript
Recently, AI agents have been on the rise among developers and engineers. For those of you who don’t know, agent AI is an implementation of the LLM process, where LLM is equipped with tools, memory, and the ability to make decisions. Think of it as an assistant that can perform tasks, not just give output in the form of text.
The concept of AI agents is very powerful, especially when multiple agents work together in a system. The process of inter-agent interaction and coordination is called workflow. In this article, we will not focus on the theory of AI agents in depth, but more on the engineering and practical side. So make sure you have a basic understanding of RAG (Retrieval-Augmented Generation) and LLM before proceeding.
Building an Effective Agent Workflow
In this section, we will learn common patterns that are often used in agentic systems implemented in various applications. This time we will practice them using Vercel AI SDK and Langgraph. In addition, I will explain a little bit about LangGraph and AI SDK. If you are already familiar with these frameworks, you can skip to the code implementation section.
Why LangGraph?
LangGraph is a library built on top of LangChain, designed for LLM-based applications, making LangGraph a solid choice for complex agent systems. LangGraph makes building graph-based workflows super easy and efficient. It simplifies handling complex tasks like orchestrating LLM calls and managing structured outputs. It also integrates seamlessly with Pydantic for data validation and type enforcement, ensuring that the inputs and outputs of each workflow step are well-structured and reliable.
At the heart of LangGraph is the concept of a stateful graph:
State: Stores and updates context throughout the workflow, enabling dynamic decision-making.
Nodes: Represent computation steps, handling tasks like processing inputs, decision-making, or external interactions.
Edges: Define the flow between nodes, supporting conditional logic for flexible, multi-step workflows.
Why Vercel AI SDK
Vercel AI SDK is a TypeScript library designed for building AI-powered applications, especially within React-based frameworks like Next.js, Svelte, and Vue. It streamlines AI development with a standardized approach to prompts, structured data, and tool integration.
AI SDK Core has various functions designed for text generation, structured data generation, and tool usage. These functions take a standardized approach to setting up prompts and settings, making it easier to work with different models.
- streamText: Streams text and tool calls, perfect for chatbots and content streaming.
- streamObject: Streams structured objects matching a Zod schema, making it easy to generate UI components from JSON-like data.
Vercel AI SDK also includes AI SDK UI, which simplifies building LLM-based interfaces. That’s why it’s my go-to library for developing AI applications on Next.js! 🔥
Workflow Patterns
Workflow is a generic term for orchestrated and repeatable patterns of activity, enabled by the systematic organization of resources into processes that transform materials, provide services, or process information.
The concept of workflow is often encountered in everyday life. For example, in college where we follow a structured organization, or in a work environment where there is a system.
If you want a more detailed explanation, you can read the research of Anthropic here. Anthropic’s research is a required reference for many AI developers, and can be additional learning material for you as well. Among them are:
Prompt Chaining (Sequential Processing)
Routing
Parallel Processing
Orchestration
Evaluation/Feedback Loops
For the code that you want to learn, you can check my github or check the source code repo at the end of this article.
Set up workflow
Before we start, we need to set up the framework we will be using. You can choose to use either Typescript or Python. The API we use here is groq provider. Don’t forget to install the library first.
Setting up Typescript with Vercel AI SDK
Python setup with langgraph
Prompt Chaining
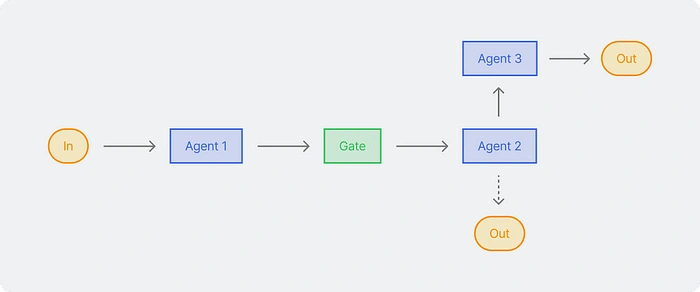
This is the simplest workflow. Prompt chaining breaks down a single task into multiple steps. It involves multiple outputs from one prompt as inputs for the next. This pattern is ideal for tasks where the order of each step is clear.
For example, when creating copywriting for a brand, it starts with agent A crafting the CTA. Then, agent B assesses the emotional aspect. Next, agent C assesses the fit with the brand tone. Each step is sequential, and the output from one step becomes the input for the next.
Once the agent specializing in marketing is declared, the next step is to verify that the quality is relevant and to reduce hallucinations, in which case you can create additional, more complex agents that not only improve but also increase the output of the previous agent.
Workflow with LangGraph python
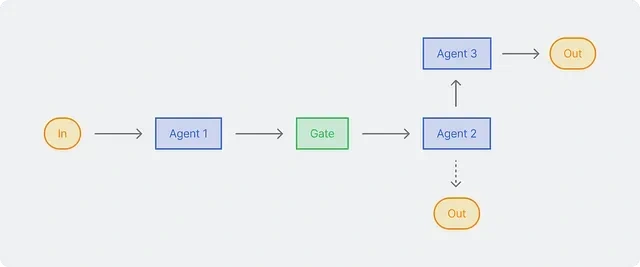
Routing
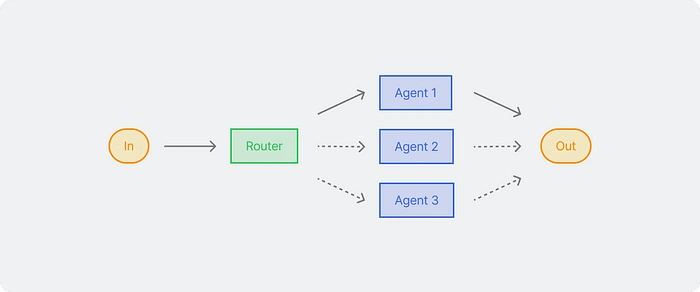
This pattern allows the model to determine the correct process path based on context and previous results. The routing pattern works well when there are several different categories that require special handling. This pattern ensures that each case is handled with the most appropriate approach. As in the example above, the result of the first LLM determines which path to take for the next step, adapting the process based on the input characteristics.
We first create a routing agent that classifies the inputs by dividing them based on the type of input, as well as its complexity and detailed reasoning.
The results of the classification are then directed to multiple agents. Simple, but this is really useful for customer service, which is directed to tools such as scheduling, contacting other people, and others, so that the output issued is personalized according to user needs.
Workflow with LangGraph python
Parallelization
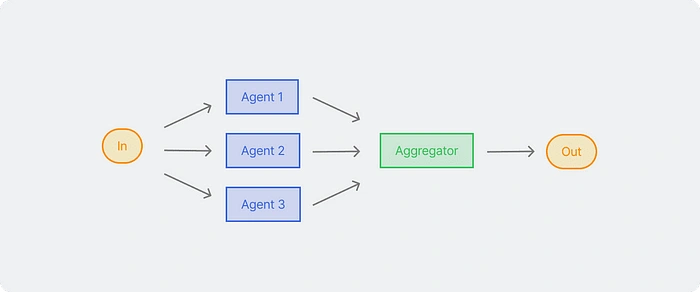
LLMs sometimes need to run at the same time and combine their outputs for more accurate results. This workflow is quite effective when a long task can be broken down into several parts and run at the same time to make it run faster. For complex tasks that require a lot of consideration, LLMs usually perform better than focusing on the specific attention of a context.
In this workflow, there are two variations:
Sectioning: Breaking a task into several subtasks that run at the same time.
Voting: Running the same task multiple times to produce different outputs.
Just like how an IT team focuses on application development, there are those who focus on performance, quality, and security. So for the flow of the website generation prompt, it is broken down into several aspects so that the results obtained not only work but also have stable performance and a high security side.
First, we need to create specialists who work simultaneously with more or less the same message.
Next we need to merge all the objects together. We need an agent as an Aggregator. That needs to review and summarize, if necessary add correction tasks to minimize errors.
Workflow with LangGraph python
Orchestration
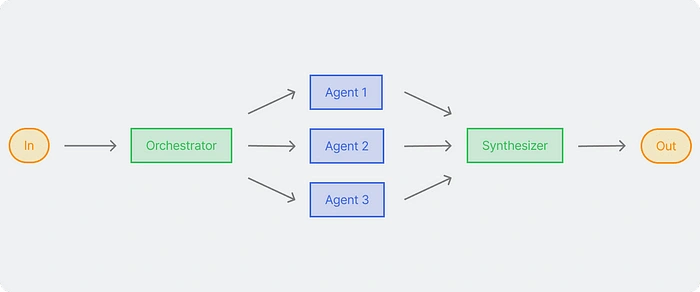
In the workflow of orchestrator workers, the first LLM (orchestrator) dissects and delegates tasks in a manner similar to decomposition and combines the results into one. This first LLM plays an important role in coordinating and executing worker specialization. Each worker is optimized for a specific subtask.
Let’s think like a team. In this example. In this team there are several sections: Business Analyst, Content Strategist, Social Media Manager, Marketing Analyst. Then, based on the project manager’s instructions, a measurement of the level of difficulty, type of assignment and task delegation is performed.
After the product manager has successfully delegated the task, the next step is to use the previous parallel pattern and delegate to employees.
Workflow with LangGraph python
Evaluation/Feedback Loops
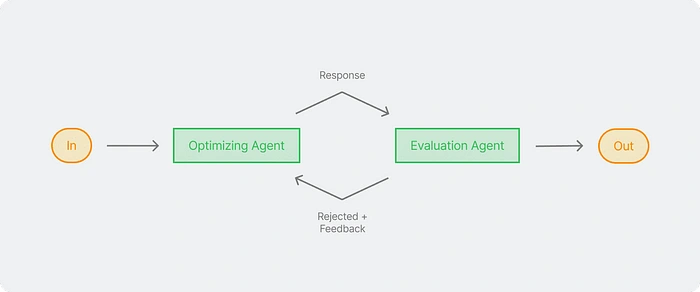
It’s not easy to tell ChatGPT to write a thesis. It’s hard for ChatGPT to think on its own. To improve the quality of the results, we need feedback from other people. We can do this by working on the parts of the thesis one at a time. For example, we can start with the background, then the content, and finally the conclusion. We need someone here to evaluate the results and provide feedback.
Workflow with LangGraph python
When to use Typescript and Python
Vercel AI SDK and langgraph are one of the frameworks that have quite complete and neat documentation. In addition to Vercel AI SDK, there are other recommended frameworks such as
Agentic, AI agent standard library that works with any LLM and TS AI SDK.
Agno, open-source python framework for building agentic systems
Rivet, a drag and drop GUI LLM workflow builder; and
Crew ai, Python Framework for orchestrating collaborative AI agents
Using a framework allows us to easily use standard patterns such as tools, memory, components and connect them by calling certain parameters.
While Python has traditionally been the dominant language for AI and ML development due to its extensive libraries and frameworks, Typescript — a superset of JavaScript — has emerged as a strong contender for building scalable, maintainable, and efficient AI/ML applications.
The use of Typescript and Python depends on your needs: if you need to develop a full-stack application quickly, Typescript is sufficient without adding more stacks; if you want to be separate and build a more complex agent, Python is recommended. Python is more recommended for building AI agents because of its full AI/ML library support and more frameworks, while Typescript is suitable if you focus on integration with the react framework, especially for fullstack developers.
For both Python and Typescript, you can check out the source code for other frameworks here.
Like this project
Posted Jun 14, 2025
Developed AI agent workflows using Python and TypeScript with LangGraph and Vercel AI SDK.
Likes
1
Views
16
Timeline
Jun 15, 2025 - Jun 19, 2025