United States Accident Analysis Project
Wade Groux
United States Accident Analysis Project

Introduction
This project demonstrates my proficiency in data analysis using a substantial dataset sourced from Kaggle. The dataset covers US traffic accidents from February 2016 to March 2023, and my analysis involves critical thinking, meticulous data cleaning, thorough analysis, and effective visualization. SQL was used for initial cleaning, followed by detailed visual analysis in Tableau.
Note: The problem statement and objectives were generated using ChatGPT as an illustrative example to showcase my analytical skills for my portfolio.
Problem Statement
The project delves into the US-Accidents dataset, spanning 49 states and collected from multiple Traffic APIs. The objective is to gain insights into car accidents, enabling real-time prediction, hotspot identification, environmental impact analysis, and severity assessment.
Objective
Conduct an in-depth analysis of the US-Accidents dataset to unravel patterns contributing to a holistic understanding of car accidents.
Questions To Be Answered During Analysis
Hotspot Identification:
Environmental Impact:
Accident Severity Analysis:
Data Sourcing
The dataset is sourced from Kaggle, titled "US-Accidents," and provided by Sobhan Moosavi, Mohammad Hossein Samavatian, Srinivasan Parthasarathy, Rajiv Ramnath, and Radu Teodorescu. Their work, "A Countrywide Traffic Accident Dataset" (2019), and the associated paper provide valuable insights.
Citations
Moosavi, Sobhan, et al. "A Countrywide Traffic Accident Dataset," 2019.
Moosavi, Sobhan, et al. "Accident Risk Prediction based on Heterogeneous Sparse Data: New Dataset and Insights."
Data Exploration: Checking for Missing Values
Overview
This section outlines the process of checking for missing values in the dataset ('us_accidents_data') using dynamic SQL. Identifying missing values is a crucial step in ensuring the integrity and completeness of the dataset.
I created a query that would return the total number of missing values for each column the dynamic script generates all columns in the specified table ('us_Accidents_data'). It uses 'INFORMATION_SCHEMA.COLUMNS' view to fetch the column names and constructs the query accordingly. Using this is a lot faster than typing in multiple different blocks. I found that there were missing values from the columns Temperature_F, Weather_Condition, and Sunrise_Sunset.
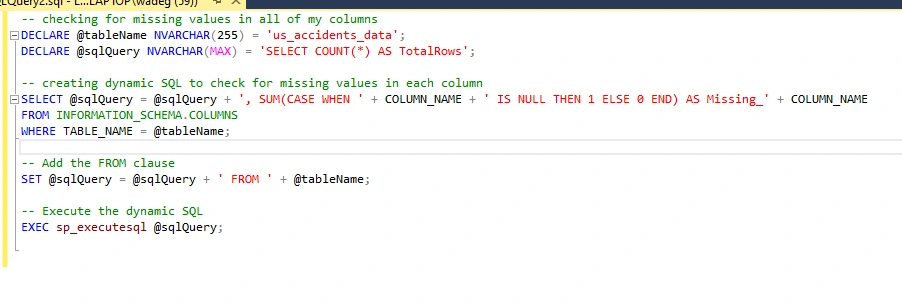


I ended up deleting all of the rows that had missing values.

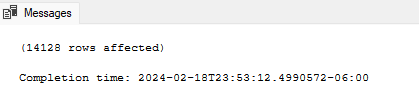
After the rows had been deleted I went and double checked to insure that all of the missing values were equal to 0
Data Cleaning: Checking/Removing Duplicates
To check for duplicate entries, I focus solely on the 'ID' column. The uniqueness of each entry is attributed to its ID number. Therefore, by crafting a query that groups rows based on the 'ID' column and counts the occurrences of each 'ID,' I can identify duplicates. The condition 'HAVING COUNT(*) > 1' filters out unique records, presenting only those with more than one occurrence.
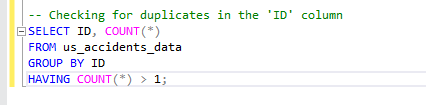
Upon execution, it was determined that there were no duplicate rows within the 'ID' column. This indicates that the dataset is devoid of any duplicate entries.
Data Exploration: Checking/Removing Outliers
I am going to check for outliers in columns Sunrise_Sunset, Severity, and Temperature_F.


There were no outliers in these two columns.
To find outliers in the 'Temperature_F' column, I'll use the Interquartile Range (IQR) method by calculating the lower and upper thresholds based on the quartiles of the data. Values beyond these thresholds are considered outliers.
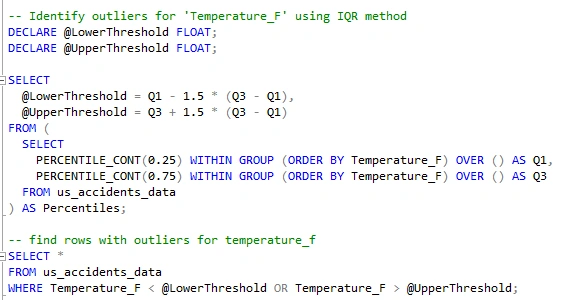
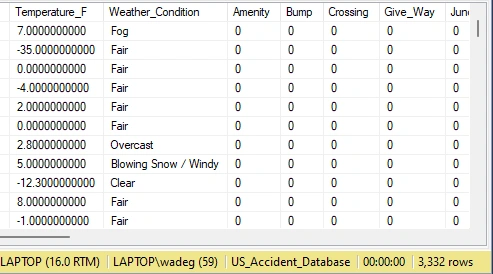
I identified 3,332 rows of outliers using the IQR method. The outliers, mostly associated with extremely cold weather conditions, suggest a correlation between icy conditions and accidents. I've decided not to delete these outliers but will make a note for further analysis. Upon reviewing the data, the reported temperatures align with the corresponding states and cities, indicating accuracy.
Next, I will further examine the outliers within the identified 3,332 rows that are above 32 degrees. This step aims to determine if these specific outliers can provide valuable insights.
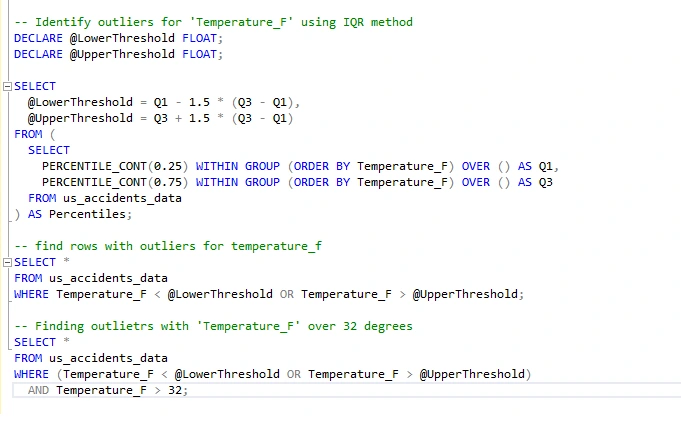

After this analysis, I found that out of the 3,332 outliers, only 5 had temperatures above 32 degrees. Removing these 5 outliers helps refine the dataset for a more accurate analysis. I will proceed to remove them and confirm the completion of this step.

Data Cleaning: Checking Data Types
I will now ensure that the data types for my data table are correct. Note: I already did this when importing my dataset, but it never hurts to double-check.
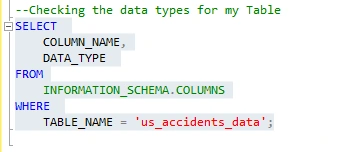
This allowed me to confirm, that my data types are correct.
Exploration: Validating Constraints
Checking Unique Constraints Now, I will write a query that checks for duplicate records by comparing the total count of records with the count of unique values in the 'ID' column.
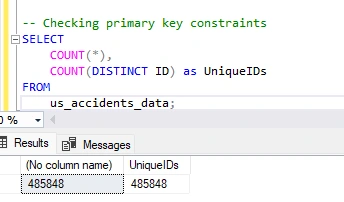
This allowed me to see that the counts are equal, indicating that there are no duplicate entries.
Checking Primary Key Constraints
I will now write a new query that checks for NULL values in the primary key column ('ID'). The result should be 0 NULL values.
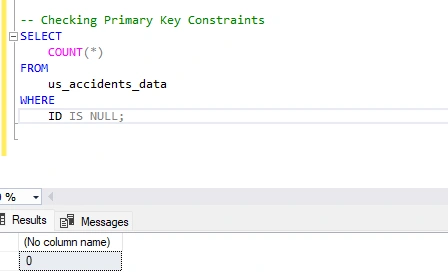
Result = 0 NULL VALUES FOUND
Checking Consistency in 'STATE' and 'CITY' Columns I will write a query that checks for NULL values in the state, and city columns.
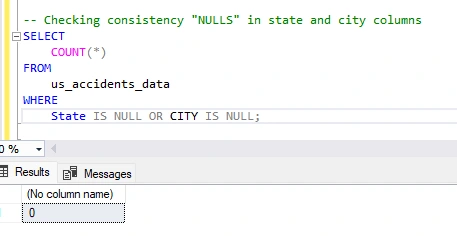
The columns contained 0 NULL values.
Data Exploration: Aggregate Functions For Summarization
Counting Number Of Accidents Per State I will now write a query that counts the number of accidents for each state and displays the results in descending order.
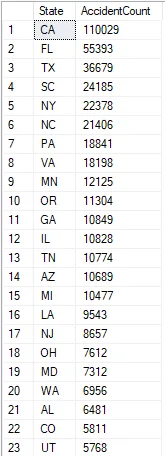
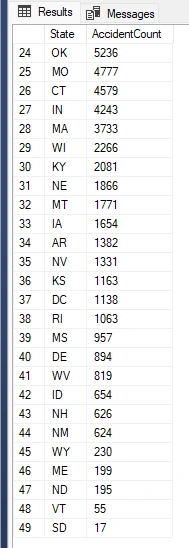
NOTE: From examining these results, I need to consider that states with higher populations may skew the analysis. A higher population could lead to a higher probability of accidents occurring compared to states with lower populations.
Calculating AVG Temperature For Each State
I will write a query to calculate the average temperature for each state.
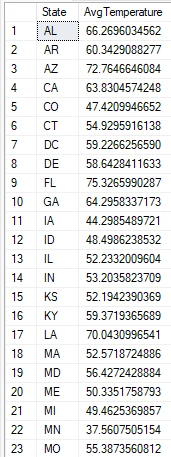
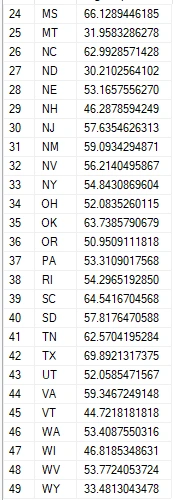
Summarizing Severity Levels By State
I will write a query to summarize severity levels (1-4) by state, providing the count of each severity level for every state.
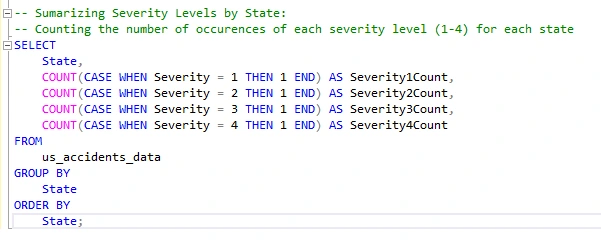
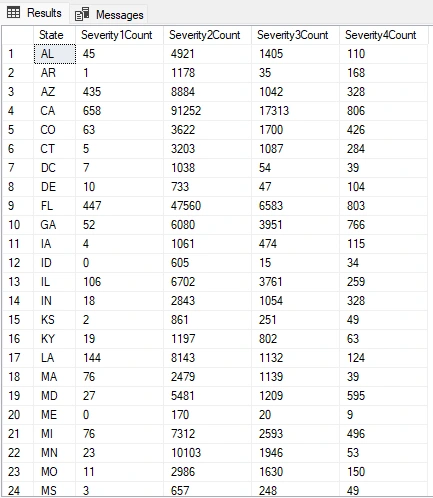
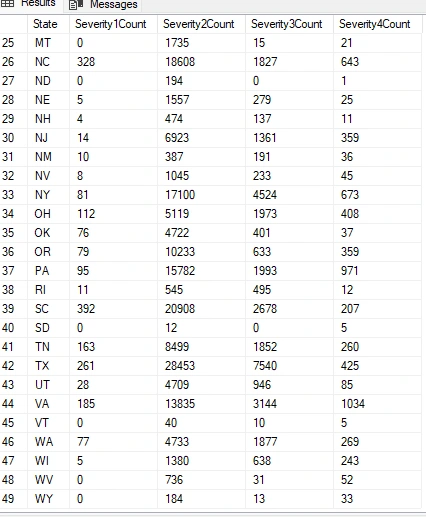
NOTE: The data opens up various possibilities for analysis, including the identification of high-severity areas, comparison of severity levels, trend analysis, correlation with weather conditions, geospatial visualization, safety recommendations, and evaluation of the impact of traffic management.
Data Exploration: Review and Understand Data Distributions
Frequency Distribution of Severity Levels
I will now write a query that shows how many accidents fall into each severity category(1-4).
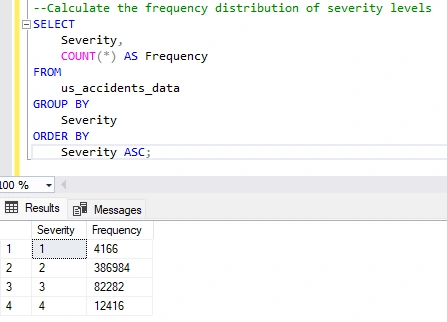
Result: Shows me the distribution levels.
Histogram of Temperature Distribution I will create a query that generates a histogram, grouping temperature values into ranges and displaying the frequency of accidents in each range.
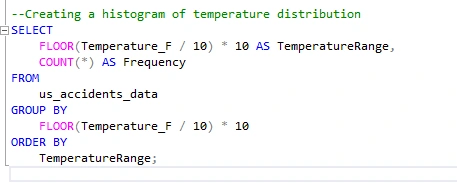
Result: Distribution of Severity Levels
Distribution of Day, Night, and Severity I will write a query that categorizes accidents based on the Sunrise_Sunset column. For each category, it will provide the total accident count as well as the severity levels 1-4. This way, I can analyze how severity is distributed during the day and night and identify periods with higher severity level accidents.
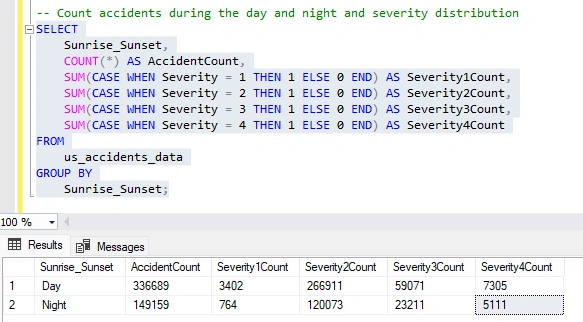
Once I saw these results, I wanted to calculate the severity count as percentages for each option, day and night. To achieve this, I will write a query that utilizes a Common Table Expression (CTE).
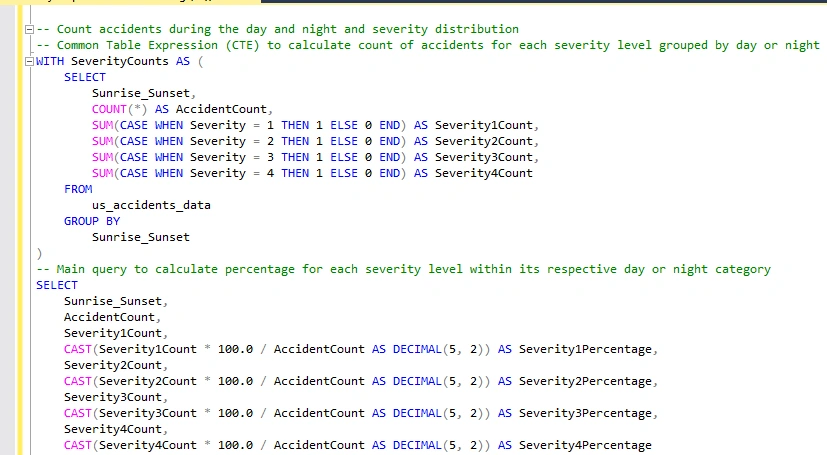

After seeing the new results, I realized that the Severity Level 4 percentage is higher at night than during the daytime, even though the night only accounts for 30.70% of accidents. This leads me to consider that I might be able to substantiate my hypothesis that driving at night contributes to higher severity of accidents.
Data Exploration: Continued (EDA)
I will review any available data dictionary or metadata that describes the variables.
The only variable I need to understand more is the "Weather Condition." I can create a query to retrieve all unique values from this column.

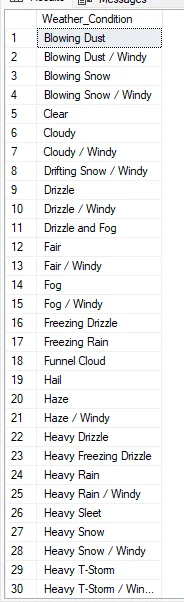
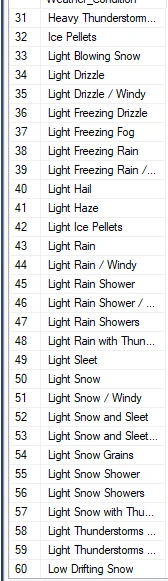
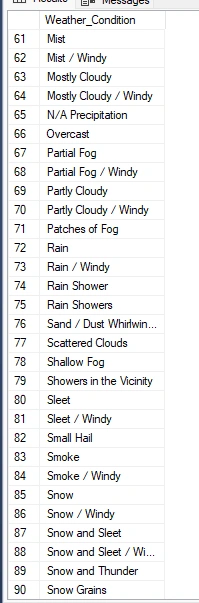
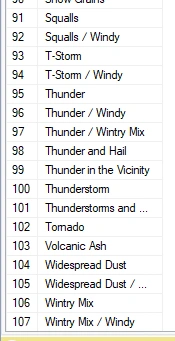
After reviewing this, I plan to summarize it to simplify my analysis process, reducing the number of unique variables in the columns. I will utilize the 'CASE' statement to generate a new column with summarized categories for the 'Weather Condition' column.
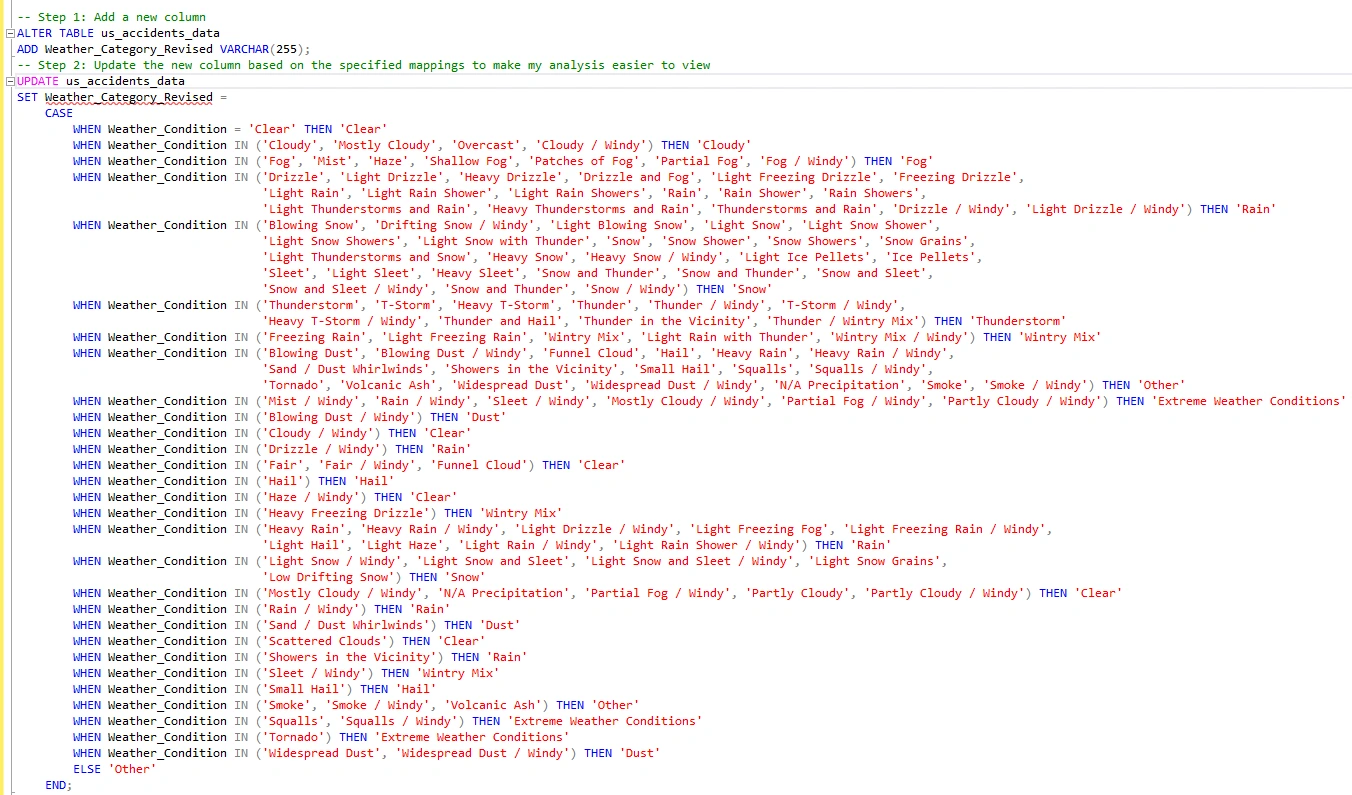
SIDE NOTE: THIS TOOK FOREVER! Following the execution of this operation, the new column has been successfully created. To ensure the accuracy of all values, I will verify the uniqueness of values in the weather category column.
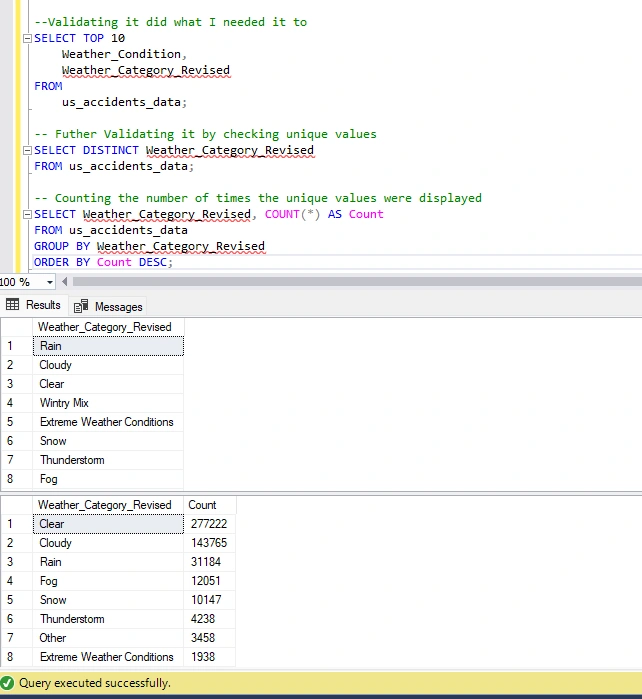
The reduction from 107 different variables to 10 in the weather condition category significantly simplifies the data, making it more conducive to analysis and extraction of insights.
I will now write a query that calculates the total number of accidents, the count for each severity level, and the percentage of accidents for each severity level within each weather category. It then orders the results by the total number of accidents in descending order.
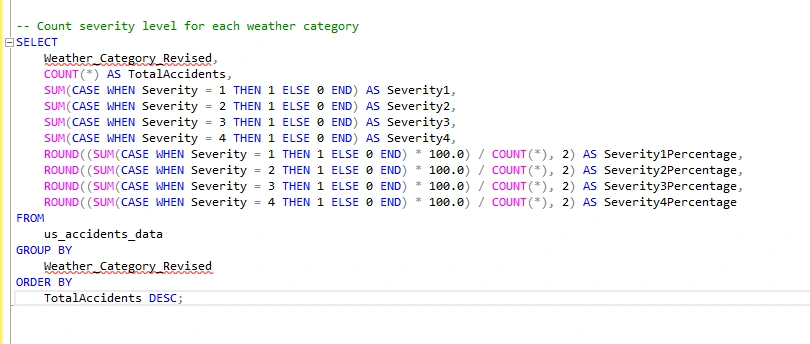
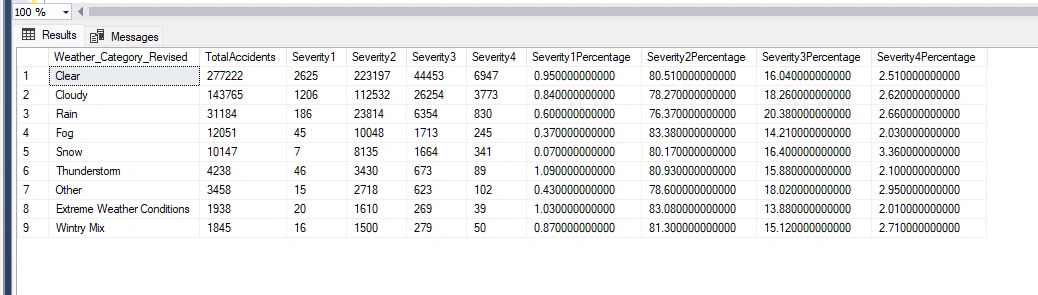
I need a new query that returns the top 5 weather conditions with the highest severity percentage in Severity 2-4 levels, excluding clear and cloudy conditions. This analysis will help me understand the impact of weather conditions on accidents and severity levels.
This shows that now has the highest Severity Level 4 Percentage
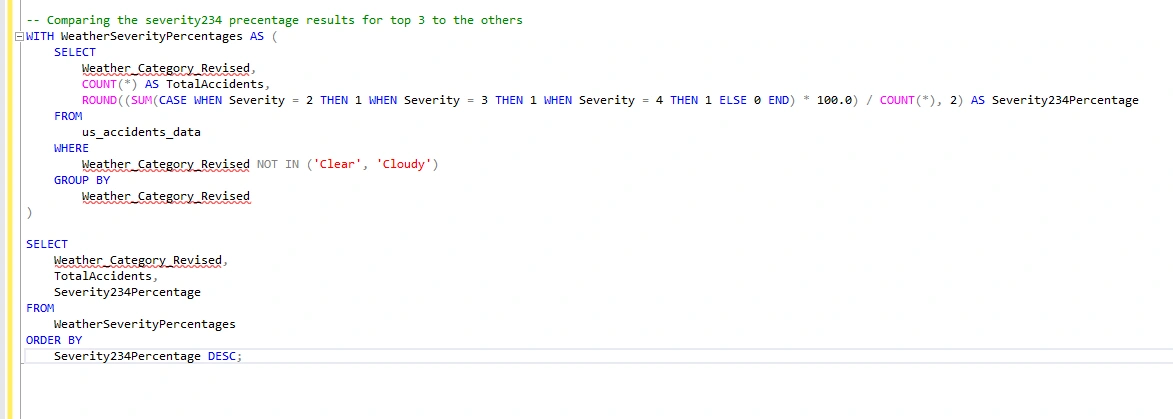
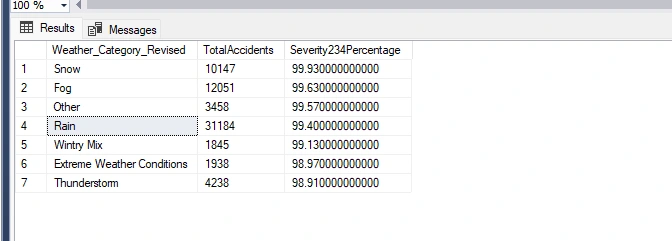
This tells me the relationships of accidents by each weather condition and how there is a relationship with weather that has an influences higher severity level.
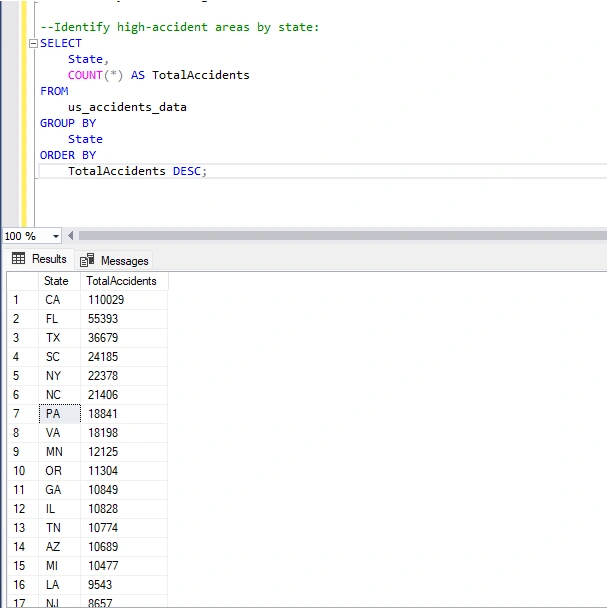
Identify High Accident Areas by State To pinpoint high-accident areas and understand contributing factors by state, I need to perform analysis based on the states considering factors such as accident counts severity levels and weather conditions.
First I will write a query that allow me to Identify High-Accident Areas by State
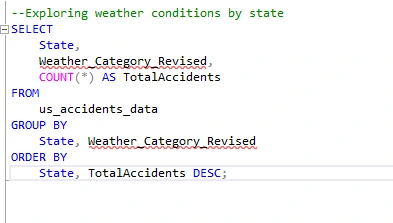
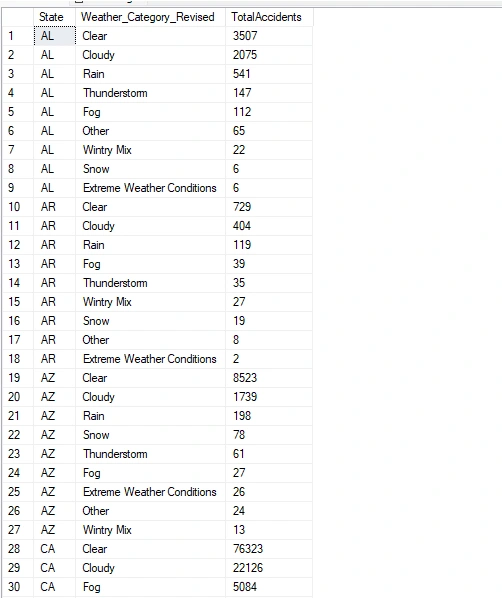
Explore Weather Conditions by State I will now write a query that provides a breakdown of severity levels for each state
I will now combine the previous 3 query's to get a holistic view of high-accident areas, severity levels, and contributing factors by state. I only want to see the top 10 for my analysis.
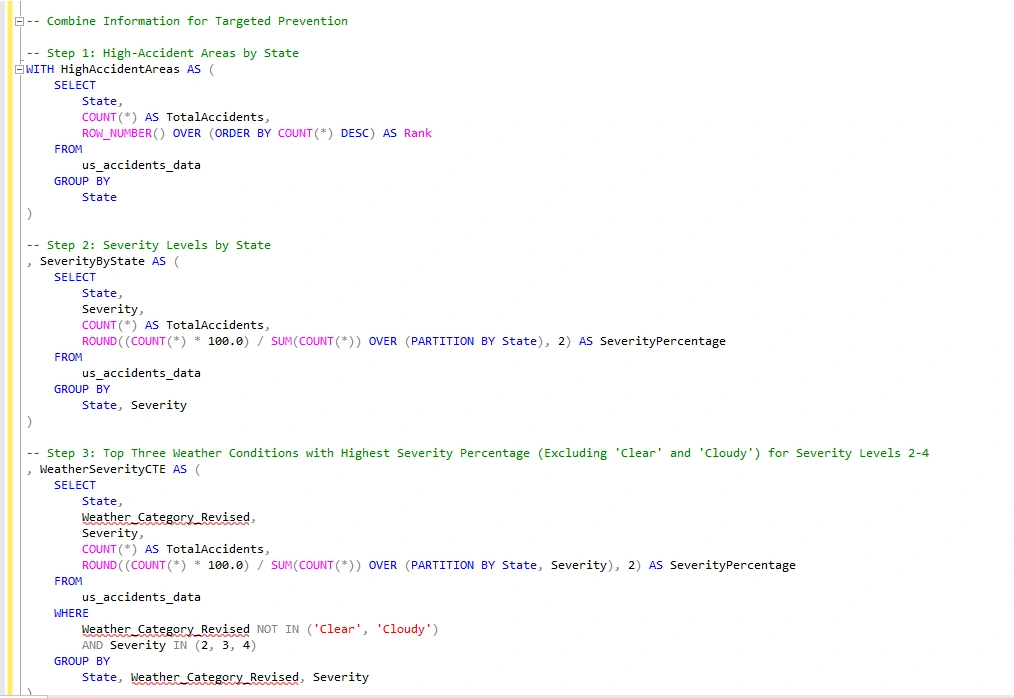
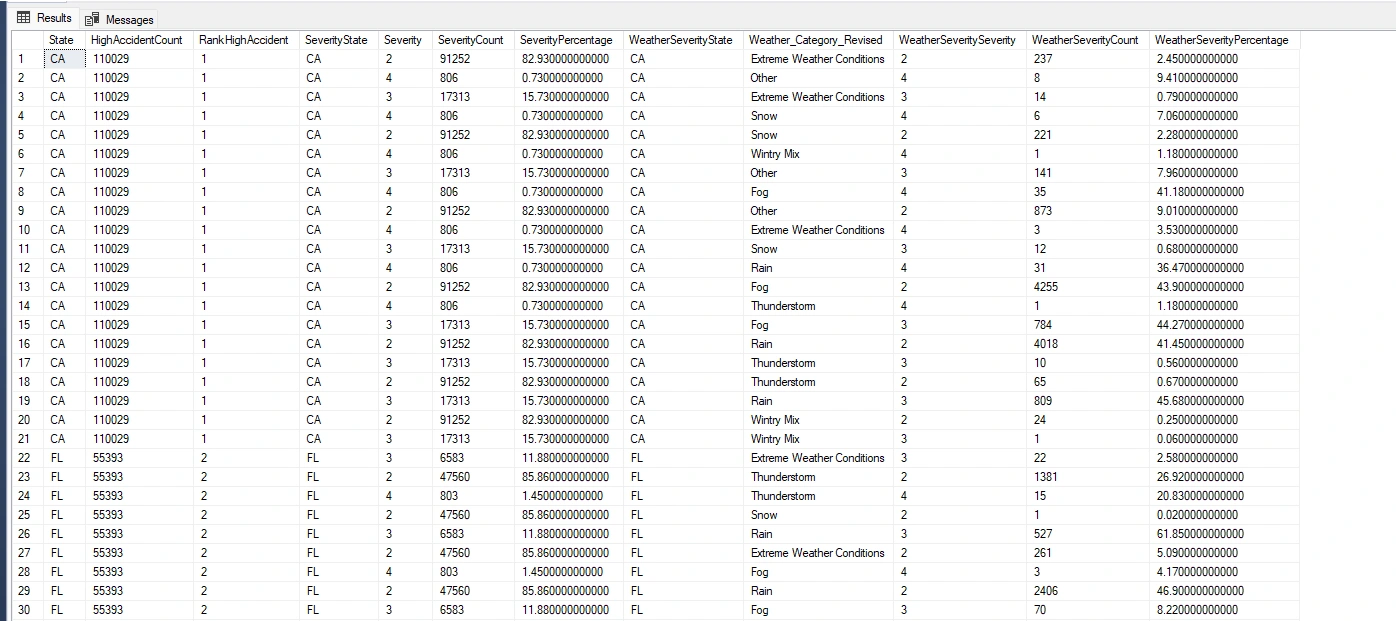
I can use this newly created table for my data visualization. This will allow me to identify high accident areas and understand contributing factors for targeted prevention. By analyzing the accident data, I can see patterns, trends, and commonalities in terms of locations, types of accidents, and contributing factors.
After being able to visualize this information for targeted prevention we could use Consider using machine learning models to predict accident hotspots based on historical data. These models can identify key features contributing to accidents. Another option is Work with local authorities, traffic safety organizations, or law enforcement to gain additional insights and collaborate on targeted prevention initiatives.
Exciting news! Having laid a solid foundation with the data, I'm now taking the next step using Tableau to craft a compelling narrative.
Data Visualizations: Crafting Creative Data Visualizations
You can interact with the Tableau Dashboard Here: https://public.tableau.com/app/profile/wade.groux/viz/USAccidentsPortfolioProject/Dashboard1
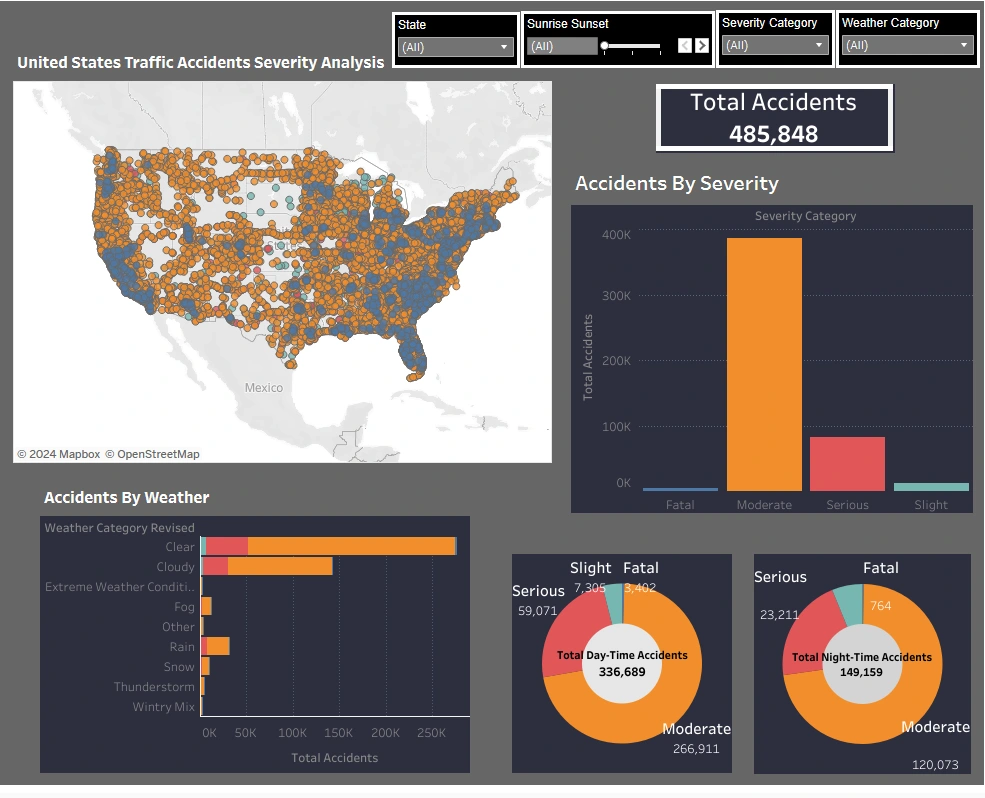
In my Tableau Analysis Visualization, I've developed an interactive dashboard for the United States Traffic Accidents Severity Analysis, featuring:
• Geographical mapping of accidents and total accident count.
• Segmentation of accidents by severity levels.
• Analysis of accidents in relation to different weather conditions.
• Distinction between accidents occurring during the day and night.
• Customizable filters for states, time of day, severity levels, and weather categories.
• A comprehensive exploration of the interplay between these factors, providing insights into the determinants of accident severity in the United States.
Data Analysis: Insights and Recommendations
Insights:
• Daytime accidents exhibited a higher severity level compared to nighttime accidents, suggesting that there might be specific factors contributing to increased severity during daylight hours.
• Incidents occurring in adverse weather conditions such as rain, snow, and fog resulted in a higher severity level, particularly in the serious condition category, when contrasted with clear and cloudy weather. This indicates a correlation between challenging weather conditions and elevated accident severity.
• Geographical analysis revealed that the eastern part of the United States experienced a higher volume of accidents than the western region. This observation might be attributed to the higher population density in the eastern states, potentially leading to increased traffic and a greater likelihood of accidents.
• Analysis of accidents by severity level indicated that a significant proportion of accidents fell into the "minor" category. Further investigation into the specific factors contributing to minor accidents could provide insights into preventive measures to reduce overall accident rates.
• When examining accidents by state, it became evident that certain states consistently showed higher severity levels across different weather conditions and times of the day. This suggests the presence of state-specific factors or road conditions that may contribute to the increased severity of accidents, warranting a closer look into localized safety measures.
Recommendations:
• Daytime Safety Measures: Implement targeted safety measures during daytime hours, considering the observed higher severity of accidents during this period. This could include enhanced visibility measures, increased law enforcement presence, and public awareness campaigns emphasizing safe driving practices during daylight.
• Weather-Responsive Traffic Management: Develop weather-responsive traffic management strategies, especially during rain, snow, and fog. This may involve deploying weather-specific road maintenance crews, updating signage for adverse conditions, and implementing technology-driven alerts to drivers when severe weather is anticipated.
• Eastern States Safety Initiatives: Given the higher accident rates in the eastern part of the United States, collaborate with states in this region to develop and implement region-specific safety initiatives. These could include targeted educational programs, improved infrastructure, and stricter law enforcement to address the unique challenges contributing to the higher accident volume.
• Focus on Minor Accidents: Devote attention to understanding and preventing minor accidents, as they constitute a significant portion of incidents. Investigate the specific causes behind these minor accidents and introduce preventive measures, such as driver education campaigns or road design improvements, to reduce their occurrence.
• State-Specific Safety Plans: Work with states showing consistently higher severity levels across different conditions to develop state-specific safety plans. These plans could involve a combination of targeted enforcement, infrastructure improvements, and community engagement to address the localized factors contributing to elevated accident severity.
Conclusion
In conclusion, the Tableau Analysis Visualization of United States Traffic Accidents Severity has provided valuable insights into the patterns and factors influencing accident severity. The findings underscore the need for targeted interventions to enhance road safety. Recognizing the higher severity of daytime accidents suggests the importance of specific measures during daylight hours, while the correlation between adverse weather conditions and increased severity advocates for weather-responsive traffic management strategies. The geographical disparity in accident rates between the eastern and western regions highlights the necessity for region-specific safety initiatives, acknowledging the potential influence of population density. Additionally, attention to minor accidents and collaboration with states showing consistently higher severity levels present opportunities for comprehensive safety improvement. By implementing the recommended measures, it is possible to address the identified risk factors and contribute to a safer and more secure road environment across the United States.
Like this project
Posted Mar 2, 2024
Portfolio Project
Likes
0
Views
79