NovaBench AI Recommendation Engine
Rohith Singh

AI Recommendation Engine for NovaBench Content Platform
Helping users find the right laptop using natural language, real benchmark data, and content they already trust.
The Challenge
NovaBench helps people choose laptops, but most users don't think in terms of CPU models, RAM configurations, or benchmark scores.
They ask questions like:
I'm a computer science student with a budget of $1,200. I code every day and play games on weekends. What should I buy?
The existing experience relied on filters and quiz flows. While functional, it often missed important context and couldn't take advantage of the platform's growing library of content.
That meant:
Users had to fit themselves into predefined categories
Recommendations often felt generic
YouTube reviews and editorial content weren't being used
Benchmark data lived separately from the recommendation experience
Search struggled with nuanced, real-world questions
The goal was to create a system that could understand how people naturally describe their needs and return recommendations backed by real data.

RAG Pipeline for Laptop Recommendations
The Solution
We built a Retrieval-Augmented Generation (RAG) system that combines structured benchmark data, editorial content, and semantic search to generate personalized recommendations in real time.
Instead of relying solely on an LLM, the system retrieves relevant information from multiple sources before generating a response.
This ensures recommendations are grounded in actual content rather than model assumptions.
High-Level Architecture
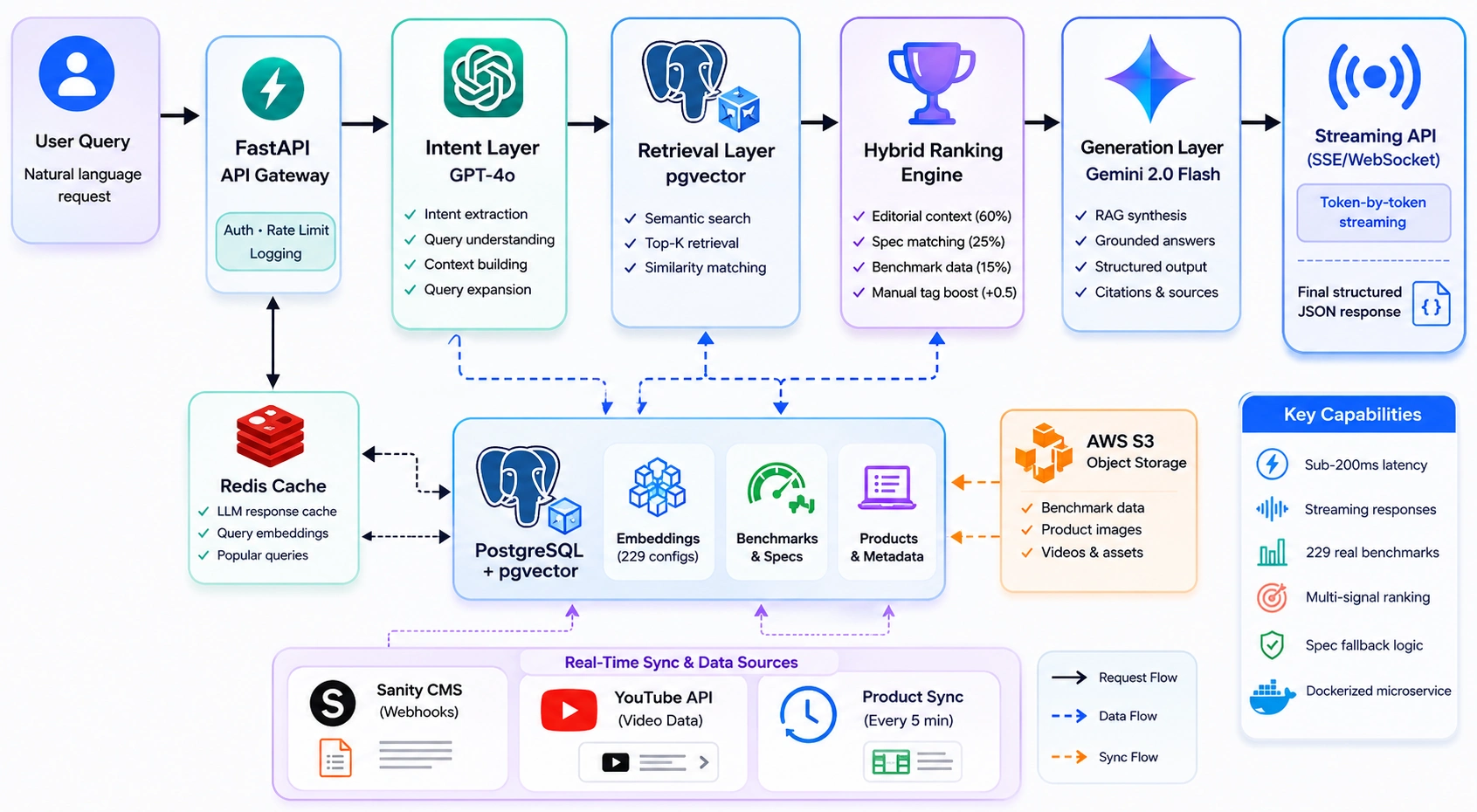
High-Level System Architecture
The recommendation engine combines several retrieval signals before producing an answer:
Editorial relevance
Hardware specification matching
Benchmark performance data
Manual relevance boosts for curated content
This hybrid ranking approach produces recommendations that feel much closer to what a knowledgeable reviewer would suggest.
Data Pipeline
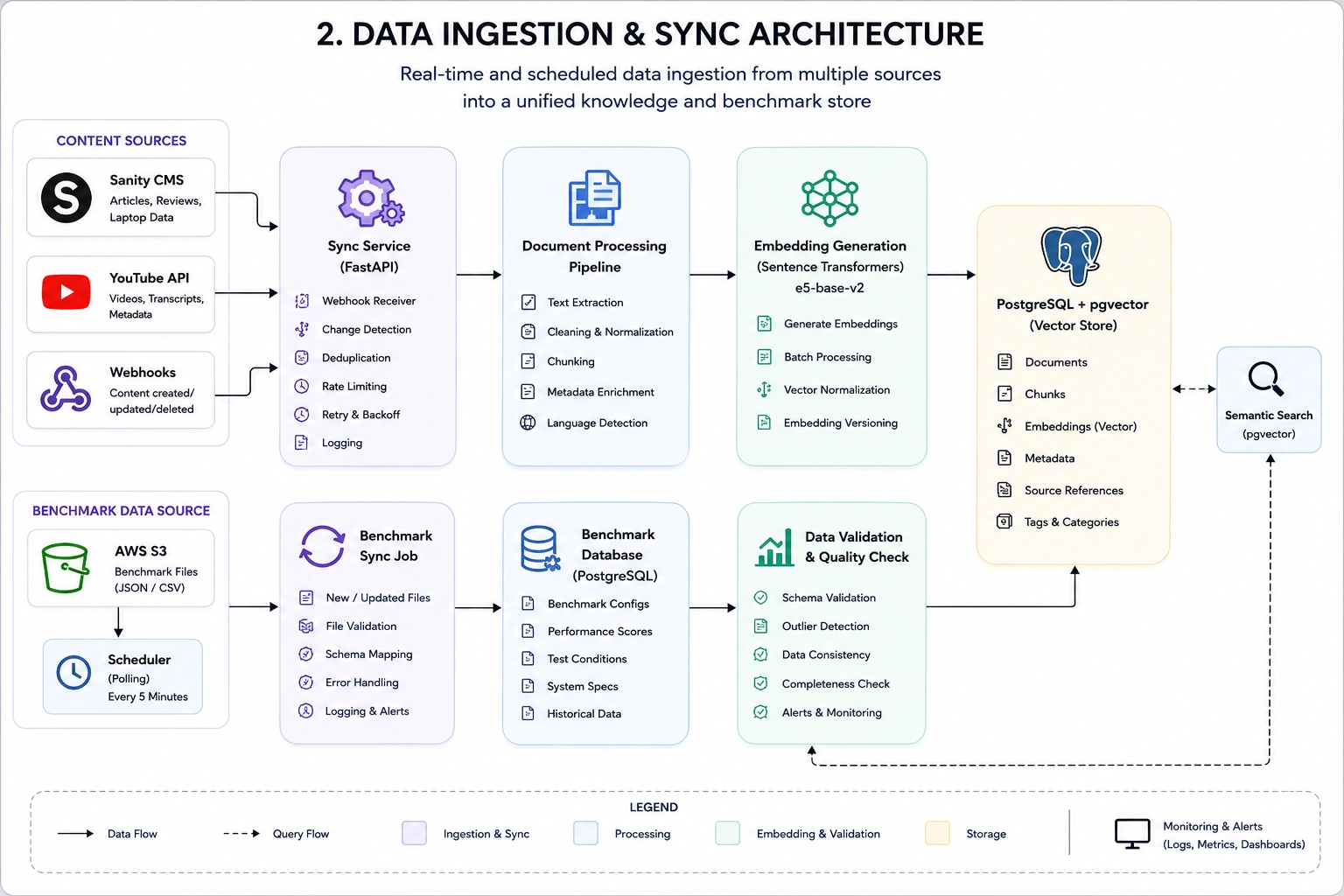
Date Ingestion & Sync Architecture
Content is continuously synchronized from multiple sources:
Sanity CMS
YouTube reviews and metadata
Benchmark datasets stored in AWS S3
New content is processed automatically, embedded, and made searchable without manual intervention.
What We Built
Real-Time Content Sync
A webhook-driven ingestion pipeline keeps the knowledge base up to date as new articles, videos, and benchmark data become available.
Content changes are reflected in search results within minutes.
Semantic Search Layer
Using Sentence Transformers and pgvector, the platform can retrieve content based on meaning rather than exact keywords.
Users don't need to know technical terminology to find relevant recommendations.
Hybrid Ranking Engine
Retrieved results are re-ranked using multiple signals, including benchmark performance and specification matching.
This helps surface recommendations that are not only relevant, but genuinely suitable for the user's needs.
Streaming Recommendation API
Responses are streamed back to the client as they are generated, creating an experience that feels immediate and interactive.
The final response also includes structured product data such as:
Product links
Pricing information
Images
Benchmark scores
Performance Optimization
To keep response times low, we introduced:
Redis caching
Batched database lookups
Optimized retrieval queries
Reduced database round trips
The result was consistent sub-200ms retrieval performance in production.
Reliability & Fallbacks
When semantic retrieval confidence drops below a threshold, the system automatically falls back to specification-based matching.
This prevents weak or unsupported recommendations and improves consistency across edge cases.
Technical Stack
The stack was intentionally kept simple and operationally efficient.
FastAPI
PostgreSQL + pgvector
Redis
Docker
GPT-4o
Gemini Flash
Sentence Transformers
AWS S3
Sanity CMS
One notable decision was using pgvector instead of a dedicated vector database.
Since the application's data already lived in PostgreSQL, keeping vectors in the same system reduced operational complexity while providing more than enough performance for the dataset size.
Outcome
NovaBench's recommendation experience went from a filter-and-quiz flow to a conversational assistant grounded in real benchmark data. Users now describe their situation in plain language and get recommendations backed by editorial content, performance scores, and specifications, all in a single response, delivered in under 200ms.
The same RAG architecture is reusable for any business with existing content, documents, or structured data they want to make intelligent.

RAG Pipeline & Knowledge Base Specialist
The architecture is reusable across many domains where businesses already have valuable content, documents, or structured data that should power intelligent recommendations.
Whether it's product discovery, internal knowledge bases, support systems, or document search, the same pattern can be adapted to fit the problem.
We don't build generic AI features bolted onto existing products. We architect systems where the AI understands your specific domain, your data, your content, your customers.
Like this project
Posted Jun 8, 2026
Built a RAG-powered laptop recommendation engine that combines benchmarks, content, and semantic search to deliver personalized results in under 200ms.
Likes
2
Views
4
Timeline
Feb 9, 2026 - Mar 23, 2026