itashiUchiha/fork_ET-BERT
cheikh Sadibou sidibe
ET-BERT


Note:
⭐ Please leave a STAR if you like this project! ⭐
If you find any incorrect / inappropriate / outdated content, please kindly consider opening an issue or a PR.
The repository of ET-BERT, a network traffic classification model on encrypted traffic.
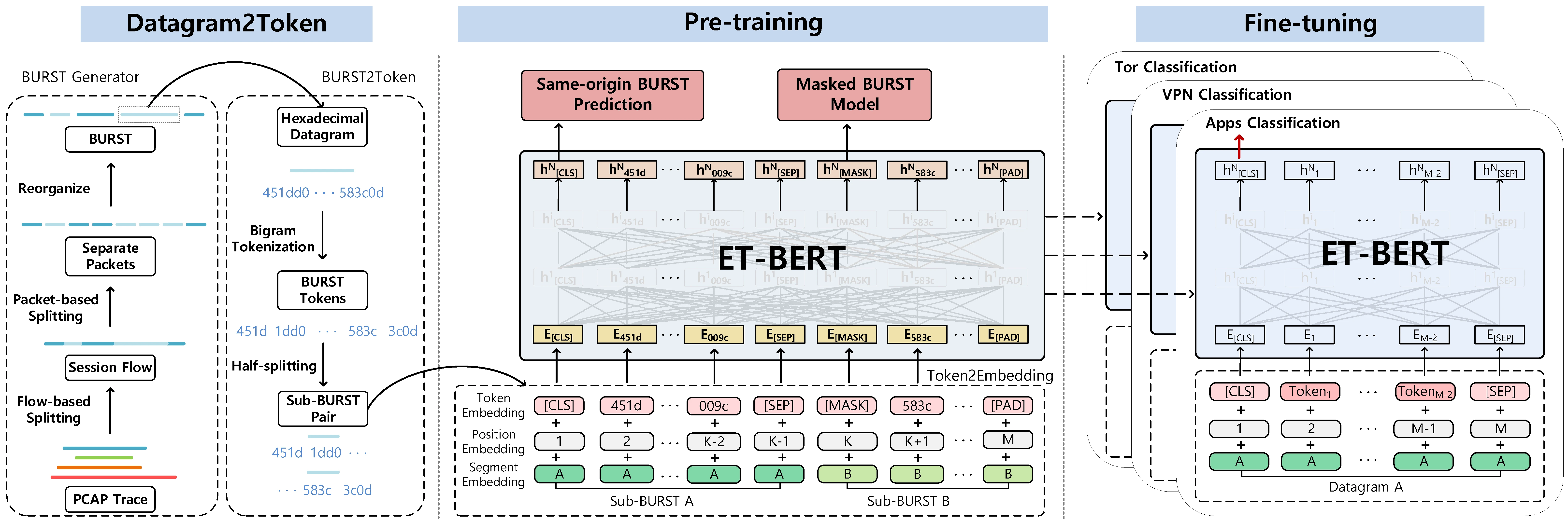
ET-BERT is a method for learning datagram contextual relationships from encrypted traffic, which could be directly applied to different encrypted traffic scenarios and accurately identify classes of traffic. First, ET-BERT employs multi-layer attention in large scale unlabelled traffic to learn both inter-datagram contextual and inter-traffic transport relationships. Second, ET-BERT could be applied to a specific scenario to identify traffic types by fine-tuning the labeled encrypted traffic on a small scale.
The work is introduced in the 31st The Web Conference:
Note: this code is based on UER-py. Many thanks to the authors.
Table of Contents
Requirements
Python >= 3.6
CUDA: 11.4
GPU: Tesla V100S
torch >= 1.1
six >= 1.12.0
scapy == 2.4.4
numpy == 1.19.2
shutil, random, json, pickle, binascii, flowcontainer
argparse
packaging
tshark
For the mixed precision training you will need apex from NVIDIA
For the pre-trained model conversion (related with TensorFlow) you will need TensorFlow
For the tokenization with wordpiece model you will need WordPiece
For the use of CRF in sequence labeling downstream task you will need pytorch-crf
Datasets
The real-world TLS 1.3 dataset is collected from March to July 2021 on China Science and Technology Network (CSTNET). For privacy considerations, we only release the anonymous data (see in CSTNET-TLS 1.3).
Other datasets we used for comparison experiments are publicly available, see the paper for more details. If you want to use your own data, please check if the data format is the same as
datasets/cstnet-tls1.3/ and specify the data path in data_process/.Using ET-BERT
You can now use ET-BERT directly through the pre-trained model or download via:
After obtaining the pre-trained model, ET-BERT could be applied to the spetic task by fine-tuning at packet-level with labeled network traffic:
The default path of the fine-tuned classifier model is
models/finetuned_model.bin. Then you can do inference with the fine-tuned model:Reproduce ET-BERT
Pre-process
To reproduce the steps necessary to pre-train ET-BERT on network traffic data, follow the following steps:
Run
vocab_process/main.py to generate the encrypted traffic corpus or directly use the generated corpus in corpora/. Note you'll need to change the file paths and some configures at the top of the file.Run
main/preprocess.py to pre-process the encrypted traffic burst corpus. python3 preprocess.py --corpus_path corpora/encrypted_traffic_burst.txt \
--vocab_path models/encryptd_vocab.txt \
--dataset_path dataset.pt --processes_num 8 --target bert
Run
data_process/main.py to generate the data for downstream tasks if there is a dataset in pcap format that needs to be processed. This process includes two steps. The first is to split pcap files by setting splitcap=True in datasets/main.py:54 and save as npy datasets. Then the second is to generate the fine-tuning data. If you use the shared datasets, then you need to create a folder under the dataset_save_path named dataset and copy the datasets here.Pre-training
To reproduce the steps necessary to finetune ET-BERT on labeled data, run
pretrain.py to pre-train.Fine-tuning on downstream tasks
To see an example of how to use ET-BERT for the encrypted traffic classification tasks, go to the Using ET-BERT and
run_classifier.py script in the fine-tuning folder.Note: you'll need to change the path in programes.
Citation
If you are using the work (e.g. pre-trained model) in ET-BERT for academic work, please cite the paper published in WWW 2022:
Contact
Please post a Github issue if you have any questions.
Like this project
Posted Feb 26, 2024
The repository of ET-BERT, a network traffic classification model on encrypted traffic. The work has been accepted as The Web Conference (WWW) 2022 accepted pa…