Udacity Data Engineer Capstone Project
Jonathan Kamau
Github Link: https://github.com/jonathankamau/udend-capstone-project
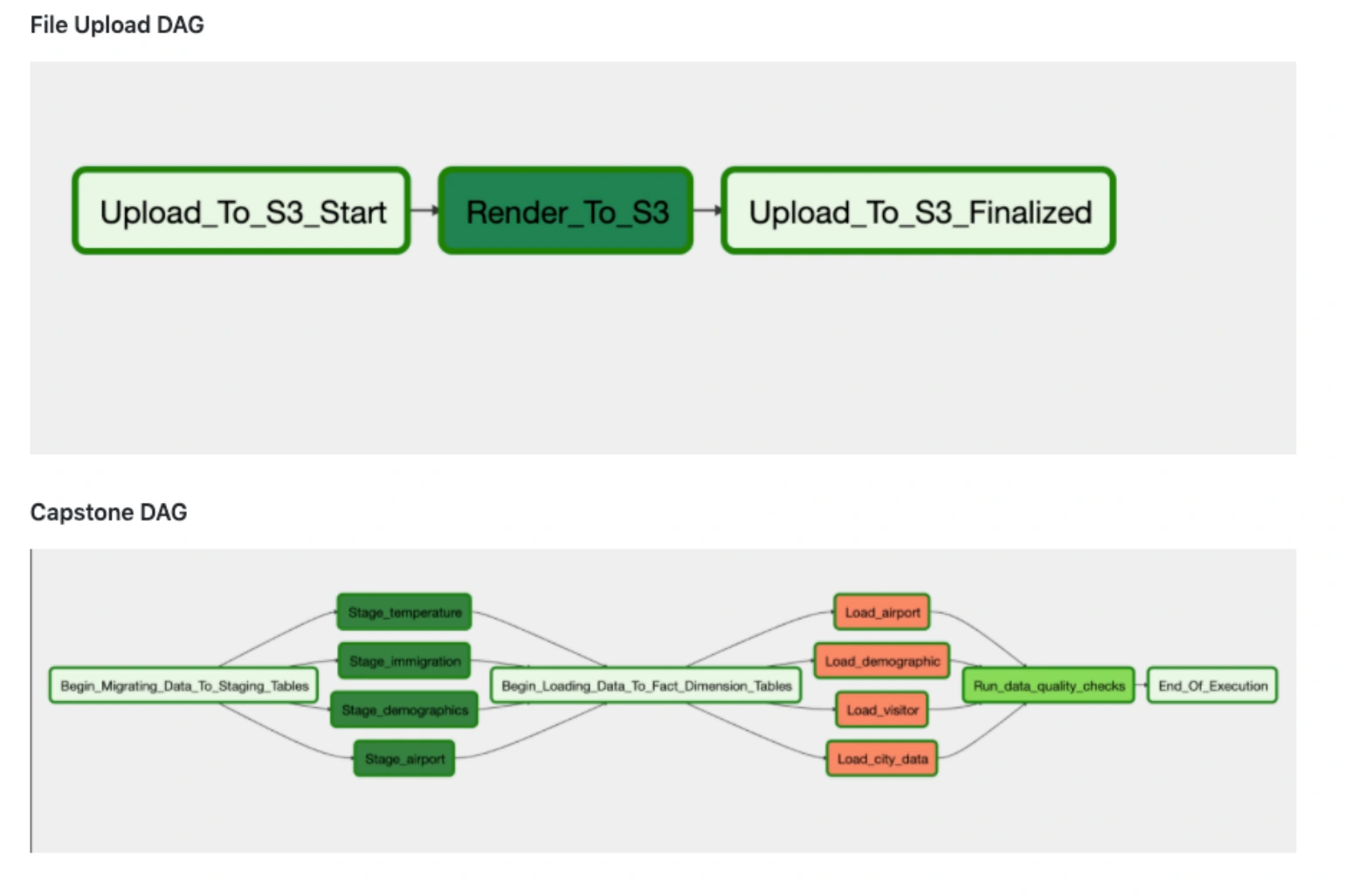
The purpose of this project is to build an ETL pipeline that will be able to provide information to data analysts, immigration and climate researchers e.tc with temperature, population and immigration statistics for different cities. It does this by first extracting temperature, airport, immigration and demographic data from various datasets, perform some transformation on it and convert the data into json files using Apache Spark that can be then uploaded to a Redshift database. Using Apache Airflow, the json files get migrated to s3, then the data gets uploaded to Redshift, undergoes further transformation and gets loaded to normalized fact and dimension tables using a series of reusable tasks that allow for easy backfills. Finally, data checks are run against the data in the fact and dimension tables so as to catch any discrepancies that might be found in the data.
Like this project
Posted Jan 27, 2021
Likes
0
Views
52
Tags