Datapipeline Application For IDfy
Het Desai
About Job:
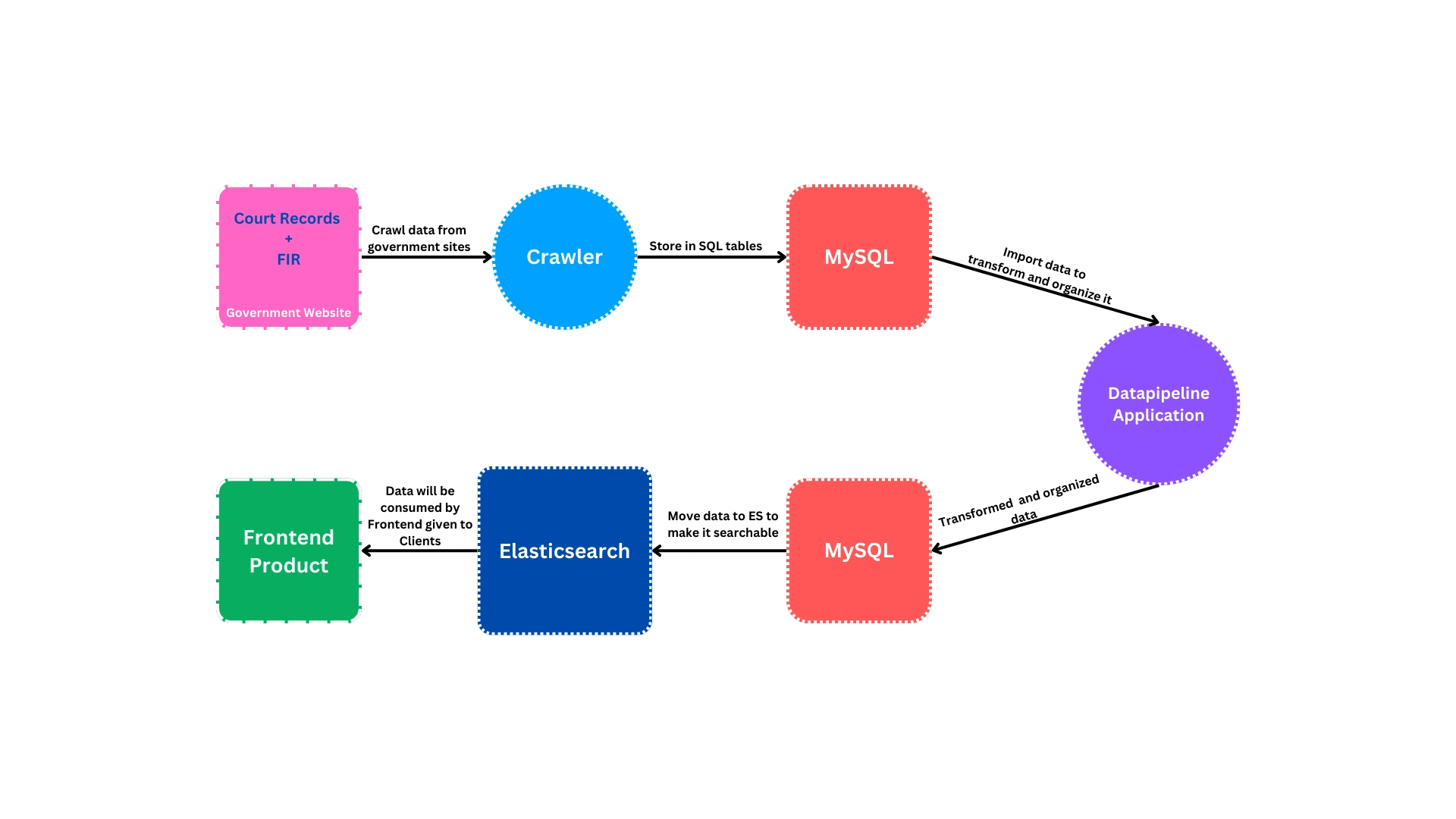
In the highly regulated and intricate domain of loan approval risk assessment, our team developed a sophisticated data pipeline to meticulously analyze cases for both companies and individuals. This system seamlessly orchestrated the entire data flow from web crawling and SQL storage to data transformation and extraction culminating in the synchronization of enriched data to Elasticsearch. The objective was to enhance search capabilities, ensure data integrity, and streamline the decision-making process for loan approvals.
Role and Responsibilities
Full-Stack Engineer
Data Pipeline Optimization: Advanced the automation of the existing data pipeline, enhancing efficiency and reliability in data processing workflows.
Elasticsearch Management: Took full ownership of Elasticsearch configurations, ensuring optimal performance and scalability to handle high data loads.
Pipeline Enhancement: Optimized specific sections of the comprehensive web crawling process, improving data accuracy and processing speed.
Automation Initiatives: Automated Jira issue creation, including relevant comments and watchers, to streamline project management and team collaboration.
Performance Tuning: Configured Logstash for faster data movement, significantly improving the system's responsiveness and throughput.
Cross-Functional Collaboration: Engaged with the Elastic community to troubleshoot and implement solutions, contributing to broader knowledge sharing and system enhancements.
Technologies and Tools Used
Backend & Data Processing: Node.js, Express.js, Python
Database: MySQL
Containerization & Deployment: Docker, Google Cloud Platform (GCP)
Search & Analytics: Elasticsearch, Logstash
Web Crawling: Puppeteer
Automation & CI/CD: Jira, GitHub Actions
Monitoring & Logging: Elastic Stack (ELK)
Key Contributions
Enhanced Speed and Performance: Implemented multifaceted optimizations to accelerate data movement and boost Elasticsearch performance, resulting in a 50% reduction in data processing time.
Streamlined Automation: Developed automated workflows for Jira issue creation, integrating comments and watchers to enhance project tracking and team communication.
Logstash Configuration: Spearheaded the configuration of Logstash for accelerated data ingestion, leveraging insights from the Elastic community to achieve significant performance gains. Explore my contributions.
Migration to Python: Led the migration of data processing models from Node.js to Python, utilizing Python’s multi-threading capabilities to handle large datasets more efficiently.
Scalable Elasticsearch Solutions: Designed and implemented scalable Elasticsearch architectures capable of handling high-volume data loads, ensuring consistent search performance and reliability.
Challenges and Solutions
Complex Data Integration: Faced with integrating diverse data sources, I streamlined the data pipeline by implementing robust transformation and extraction processes, ensuring seamless data flow and integrity.
Performance Bottlenecks: Identified and resolved performance bottlenecks in the data processing pipeline by optimizing Logstash configurations and migrating critical processes to Python, resulting in enhanced system responsiveness.
Scalability Issues: Addressed scalability challenges by designing modular and scalable Elasticsearch configurations, enabling the system to handle increased data volumes without compromising performance.
Automation Complexity: Simplified complex automation tasks by developing custom scripts and workflows, reducing manual intervention and increasing overall system efficiency.
Achievements and Outcomes
Significant Performance Gains: Achieved a 50% improvement in data processing speeds and a 40% increase in Elasticsearch query performance.
Enhanced Automation: Successfully automated key aspects of the data pipeline and project management processes, leading to a 30% reduction in manual tasks and improved team productivity.
Community Recognition: Contributed valuable insights to the Elastic Forum, aiding in the optimization of Logstash configurations and earning recognition from the Elastic community.
Robust and Scalable Systems: Delivered a highly scalable and reliable data pipeline that supported the client’s growing data needs, ensuring sustained performance and operational excellence.
Client Impact
Improved Decision-Making: Enabled faster and more accurate risk assessments for loan approvals through enhanced data processing and search capabilities.
Operational Efficiency: Streamlined data workflows and automated project management tasks, reducing operational overhead and allowing the client to focus on core business activities.
Scalable Solutions: Provided a scalable data pipeline that could effortlessly handle increasing data volumes, supporting the client’s expansion and long-term growth.
Enhanced Data Insights: Leveraged advanced analytics and search functionalities to deliver deeper insights, empowering the client to make informed, data-driven decisions.
Project Duration
23 Months (From July 2022 to June 2024)
Additional Highlights
Expert Collaboration: Worked closely with data scientists, DevOps engineers, and project managers to ensure seamless integration and alignment with project goals.
Continuous Improvement: Established a culture of continuous improvement by regularly reviewing and optimizing pipeline performance, adopting best practices, and staying updated with the latest industry trends.
Comprehensive Documentation: Developed detailed documentation for the data pipeline and Elasticsearch configurations, facilitating easier maintenance and future enhancements.
Like this project
Posted Feb 7, 2025
Built a Node.js & Express pipeline with Puppeteer for web crawling, MySQL, Docker, GCP, Logstash, and Elasticsearch to enhance search, and ensure data integrity
Likes
0
Views
17