Local RAG Pipeline Development for 1artifactware
Adam J. Rychlik
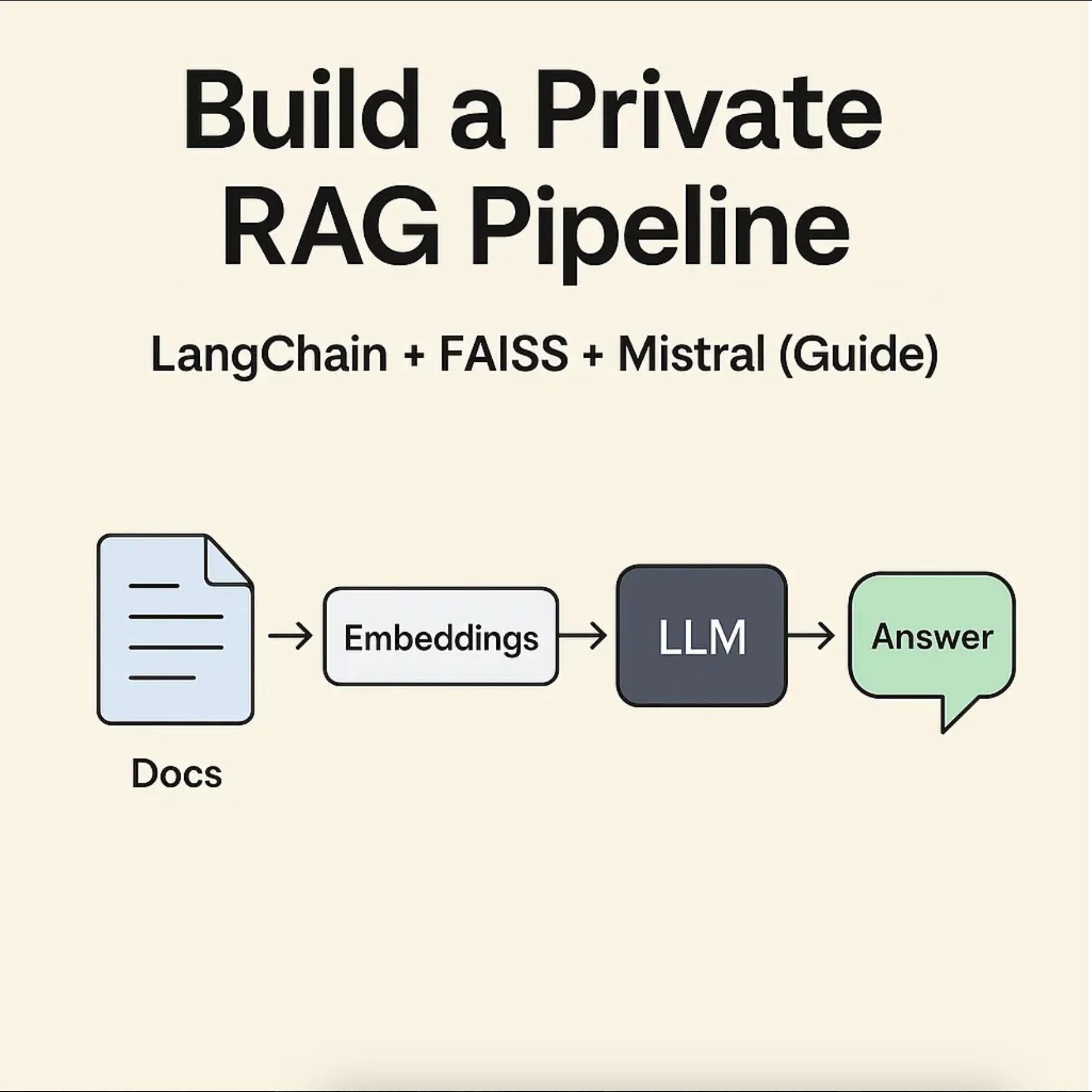
Table of Contents
Introduction
Why Local RAG
Architecture Overview
Chunk and Embed Documents
Retrieval and Generation
Model Selection
Deployment
Real World Examples
FAQ
Next Steps
Introduction
Large Language Models (LLMs) are amazing, but they have a memory problem. Out of the box, they don’t know anything about your internal documentation, client projects, CRM entries, or product catalogs. That’s where Retrieval-Augmented Generation (RAG) comes in — by connecting your own documents to the model, you unlock grounded, factual, context-aware outputs. But here’s the twist: you don’t need to use expensive, privacy-compromising cloud APIs to do this. Thanks to advances in local LLMs like Mistral, LLaMA 3, and Phi-2, and the incredible flexibility of LangChain and FAISS, you can now build a complete RAG system that runs entirely on your machine. This guide is your blueprint for doing just that. Whether you’re a solo dev, a founder with technical chops, or running a small agency — this article shows how to build a fully local, fast, private RAG pipeline from scratch, using production-ready tools. We’ll cover:
✅ What RAG is (and why you should care)
🔎 Real-world examples of RAG in action
🛠️ How to chunk, embed, store, retrieve, and generate
💡 Best practices on model choice, performance tuning, and architecture
📦 Deployment strategies with Docker, Ollama, and FastAPI
🧪 Testing and optimizing your pipeline for accuracy and latency And yes — with code you can copy, use, and ship. — -
Why Local RAG Is a Game Changer
Retrieval-Augmented Generation systems improve LLM accuracy by injecting relevant snippets from your knowledge base into the model’s prompt at runtime. But most implementations rely on OpenAI or Anthropic APIs, which:
💸 Cost money per token — especially with large prompts
🔓 Raise privacy and compliance concerns
🌐 Require internet access, slowing down response time
🎛️ Lock you into specific models or providers With local RAG, you take control:
✅ Run LLMs locally (Mistral, LLaMA 3, Mixtral, Phi-2)
✅ Search your data instantly using FAISS or Chroma
✅ Inject private knowledge into a model without sending anything to the cloud
✅ Deploy anywhere: laptop, server, offline machine, air-gapped network In short: local RAG turns an LLM into a private, intelligent assistant for your business or product. — -
Real-World Use Cases
Before we dive into architecture and code, here are just a few companies using RAG in production:
Morgan Stanley: AI assistant for financial advisors that pulls from proprietary research reports
Assembly (HR SaaS): Internal chatbot that answers employee questions using indexed HR docs
Telescope (Sales Automation): Recommends leads by retrieving CRM win/loss history
Causal (Finance SaaS): Auto-generates reports from indexed P&L spreadsheets At 1artifactware, we use RAG pipelines to:
Score leads by scraping and indexing 8,000+ agency sites
Automatically match content with service offerings
Generate tailored blog posts and emails based on each agency’s positioning You can do the same. — -
Architecture Overview
Here’s a simplified overview of the system you’re about to build:
Each piece can be swapped, optimized, and deployed as needed. We’ll walk through it all — including:
Which embedding models to use and why
Why FAISS beats Chroma for speed (and when to use Chroma anyway)
How to manage memory and context size in Mistral
How to run the whole thing via Docker or locally in Python
Step 1: Chunk and Embed Your Documents
Before you can search anything, you need to break your documents down into manageable chunks and convert them into vectors (numerical representations of meaning). This step is critical for semantic search — the heart of your RAG pipeline. — -
🔪 Text Splitting (Chunking)
LLMs can’t process unlimited text, and embeddings become fuzzy when a chunk is too long. You want chunks that:
Are semantically coherent (not mid-sentence)
Fit within the context window of your embedding model (typically 512–1024 tokens)
Include slight overlap so context isn’t lost between chunks 📌 Pro tip: 250–300 tokens (~1–2 paragraphs) with 20–50 token overlap is a sweet spot.
— -
🧠 Embedding the Chunks
Once the text is chunked, each chunk must be embedded into a vector. You’ll use a model like
all-MiniLM-L6-v2 from Sentence Transformers — fast and performant for most tasks.Alternatives for embeddings:
E5-large (more accurate, slower)MPNet (very robust across domains)OpenAI’s
text-embedding-ada-002 (if you want to go cloud) — -📦 Store Vectors in FAISS
FAISS is the go-to vector store for blazing-fast local similarity search.
💡 Note: FAISS is in-memory. You’ll save the index and reload it during app startup. — -
🧪 Bonus: Index More Than One File
For a real application, you’ll want to ingest multiple Markdown, PDF, or HTML files.
Store filename and page in metadata if you want traceability for citations later.
Step 2: Set Up Retrieval + Generation
Now that your documents are chunked, embedded, and indexed, it’s time to build the actual Retrieval-Augmented Generation (RAG) pipeline. This means:
Taking a user question
Finding the most relevant content from your FAISS index
Injecting that content into the prompt
Letting the LLM generate a grounded answer We’ll use LangChain to orchestrate the entire flow — and Ollama to run Mistral locally. — -
🧠 Load Your Index and Chunks
— -
⚡ Connect LangChain to Mistral (via Ollama)
💡 Ollama is a local runtime that supports multiple open-source LLMs. It’s fast, reliable, and doesn’t require special setup — just install the model you want:
You can run Ollama on CPU or GPU depending on your hardware. — -
🔗 Build the RetrievalQA Chain
🔧 k=4 controls how many chunks are retrieved per query. Start small (3–5), or tune dynamically based on prompt size. — -
🌐 Wrap It in a FastAPI Server
This lets you send natural language questions and get grounded answers — served from your local system. — -
📊 Example
If you indexed a proposal titled
agency-intro.md, a query like:“What services does 1artifactware provide?” Will trigger FAISS to pull the right chunks, and Mistral will generate an answer like: “1artifactware offers cloud migration, API integration, and scalable backend development tailored to marketing agencies.” All without ever touching OpenAI or sending data outside your system.
Step 3: Choose the Right Local Model (and Make It Fast)
Not all LLMs are created equal — and not all are optimized for local use. Choosing the right one for your RAG pipeline means balancing:
🧠 Model quality
⚡ Inference speed
💾 Hardware compatibility
🔓 Licensing + privacy Let’s break it down. — -
🥇 Top Local Models for RAG
| Model | Params | Strengths | RAM (fp16 / 4-bit) | | — — — — — — | — — — — — — | — — — — — — — — — — — — — — — — — — — — — | — — — — — — — — — | | Mistral | 7B | Fast, accurate, great out-of-the-box | ~13GB / ~6GB | | Mixtral | 12.9B (MoE) | Very strong factual recall (MoE active) | ~24GB / ~12GB | | LLaMA 3 | 8B | Well-rounded, strong long-form generation | ~12GB / ~6GB | | Phi-2 | 2.7B | Tiny, CPU-friendly, surprising reasoning | ~6GB / ~2GB | Most users will start with Mistral or LLaMA 3 for the balance of quality and footprint. — -
⚙️ Hardware Considerations
You need at least 8GB RAM (or 4GB VRAM with quantization) to run most 7B models smoothly.
A modern laptop with a decent CPU can run Phi-2 or Mistral 4-bit with tolerable speed.
For real-time performance, use a GPU (6GB+ VRAM for 4-bit Mistral is ideal).
With quantization, you can run 70B models like LLaMA2–70B on a single A100 or a high-end CPU (slowly). — -
🔎 How Quantization Works
Quantization shrinks model size and speeds up inference by reducing precision.
🧮 16-bit (fp16): Full precision, highest quality
🔹 8-bit: Faster, minor accuracy loss
🧊 4-bit: Massive size reduction, slower but very efficient on CPU Use
GPTQ, AWQ, or Ollama’s built-in quantizers to load 4-bit weights with minimal performance hit.Become a member Or use
llama.cpp with AVX2 acceleration for bare-metal CPU serving. — -🚀 Inference Performance Tuning
Use batching if serving multiple users
Preload models into memory and keep them hot
Keep your retrieved context small (2–5 chunks)
Avoid 16K token models unless needed — they consume 3–4× the memory Rule of thumb: A 7B 4-bit model with 4K context will run well on most dev-class machines. A 13B or 70B model will need dedicated hardware. — -
📈 Evaluation & Benchmarking
Want to see how your setup compares? Check:
Hugging Face’s Open LLM Leaderboard
MTEB (Massive Text Embedding Benchmark)
Private evals using LangChain’s
QAEvalChain or LlamaIndex’s evaluate() functions Example:You can even compare:
RAG answers vs. pure LLM output
Different retrievers or chunk sizes
Quality at 8-bit vs. 4-bit
Step 4: Deploy Your RAG Pipeline Like a Pro
You’ve got a working RAG system locally. Now let’s deploy it so it can run 24/7, scale with traffic, and be managed like a real application. We’ll cover:
🐳 Dockerizing your app
⚙️ Running with process managers or containers
📊 Monitoring and logging
☁️ Scaling locally or on cloud
🔐 Security and access control — -
🐳 Dockerize Your RAG Service
Docker allows you to package your whole app — embeddings, FastAPI, Ollama or llama.cpp — into a portable unit. Here’s a sample
Dockerfile for your FastAPI server:If you want Ollama inside Docker too:
Then build + run:
— -
🔁 Managing the Vector Index
You don’t need to re-index every time. Save the vector store with FAISS or Chroma and load on startup:
Or store it in:
pgvector if you prefer PostgresQdrant for metadata filteringChroma if you want quick reloads — -📊 Add Monitoring (Basic)
You can track:
Latency per request
Tokens used per answer
Retrieval match quality Simple tools:
loguru or logging module for logsFastAPI middleware for timings
Use LangChain’s
tracing or CallbackHandler for tracing prompt + retrieval flow — -☁️ Where to Host
Local dev machine: Perfect for private internal tools
Cloud VM (e.g. AWS EC2, Oracle Free Tier): Easy to deploy with GPU or large CPU
Raspberry Pi / Edge device: Use Phi-2 or a small quantized model
Docker on-prem: Secure, air-gapped, totally private Some users run RAG inside:
Docker Swarm or Kubernetes
Lambda + S3 for retrieval-only (stateless + cheap)
Next.js / Flask + React frontend — -
🔐 Security & Access Control
If your RAG app is client-facing:
Add rate limiting (e.g.
slowapi or NGINX)Require authentication (JWT or basic API keys)
Sanitize incoming input and never echo raw results without moderation Example middleware:
Step 5: Learn From Real Deployments
Let’s look at how other teams — including us — are using RAG systems in production: — -
🏦 Morgan Stanley — AI for Financial Advisors
They built a private assistant that answers financial queries using internal research. All answers are grounded in proprietary content that gets retrieved and injected on-the-fly. 🔐 Result: Increased advisor productivity while maintaining strict data governance. — -
🧑💼 Assembly — AI-Powered HR Intranet
Employees use a chatbot to ask things like:
“What’s the PTO carryover policy?” RAG retrieves the right chunk from internal docs and the LLM paraphrases it. 🧠 No hallucination. Just clarity. — -
💼 Causal — Financial Analysis From Raw Data
RAG pipeline reads Xero and QuickBooks exports to generate on-demand financial metrics like burn rate, gross profit, and runway. 📈 A literal “AI financial analyst.” — -
🧪 1artifactware — Lead Qualification & Personalization
We scraped and embedded over 8,000 agency websites. Then we used a private RAG pipeline to:
Find agencies that mention “AI,” “infrastructure,” or “cloud”
Score how well their site content fits our services
Generate custom cold emails + blog recommendations for each agency 🚀 Result: High-response outreach with zero manual effort. — -
FAQ: Everything You Wanted to Know About Running RAG Locally
❓ Can I do this without a GPU?
Yes. Use a 4-bit quantized model like Phi-2, Mistral, or LLaMA 3 on CPU. It’s slower, but works — especially for internal tools. — -
❓ What if I don’t want to use Ollama?
Try:
llama.cpp — lightweight and great on CPUvLLM — high-throughput transformer inference for serving APIsLM Studio — GUI + playground for local models — -❓ Can I support follow-up questions or chat history?
Yes. LangChain and LlamaIndex support conversational retrieval chains. Just feed in past messages as part of the prompt. — -
❓ What if I want citations and sources?
LangChain’s
RetrievalQA can return the original documents. Display titles, filenames, or snippets with the answer. — -❓ How big can my document corpus be?
FAISS handles millions of entries. For 10K–100K chunks:
Use
IndexFlatL2 for speedUse
IVF or HNSW for larger corpora (tune for balance) — -What to Do Next
You’ve just built a private, flexible RAG pipeline that:
Works offline
Embeds your own knowledge base
Serves real answers from local LLMs
Costs $0 per token — -
🚀 Promote It
Use your blog, social posts, or a demo video to show it in action. People love seeing:
“Ask our chatbot anything about our services”
“Let AI summarize our process in one click”
“AI assistant that knows our playbook” — -
💰 Monetize It
Sell access to a private RAG for your industry
Offer it as a productized service to agencies
Build internal tools or copilots for specific teams (finance, HR, support) — -
🔄 Iterate On It
Try other retrievers (Chroma, Qdrant, pgvector)
Swap in bigger or faster models
Tune chunk sizes, context limits, and ranking
Add web UI (Gradio, Streamlit, or React frontend) — -
Final Thoughts
This isn’t just a “tutorial.” It’s a launchpad. RAG lets you combine the power of LLMs with the depth of your data — privately, securely, and scalably. You’ve now got the blueprint. If you want help turning it into a real product or internal tool: 👉 Schedule a Free Consultation with 1artifactware 💬 Need help deploying your own RAG pipeline? We offer private AI stack setup, optimization, and integrations. 👉 Check our blog for more AI engineering insights Let’s build something powerful. Originally published on 1artifactware.com
Like this project
Posted Nov 22, 2025
Built a local RAG pipeline for lead qualification and personalization.
Likes
0
Views
4