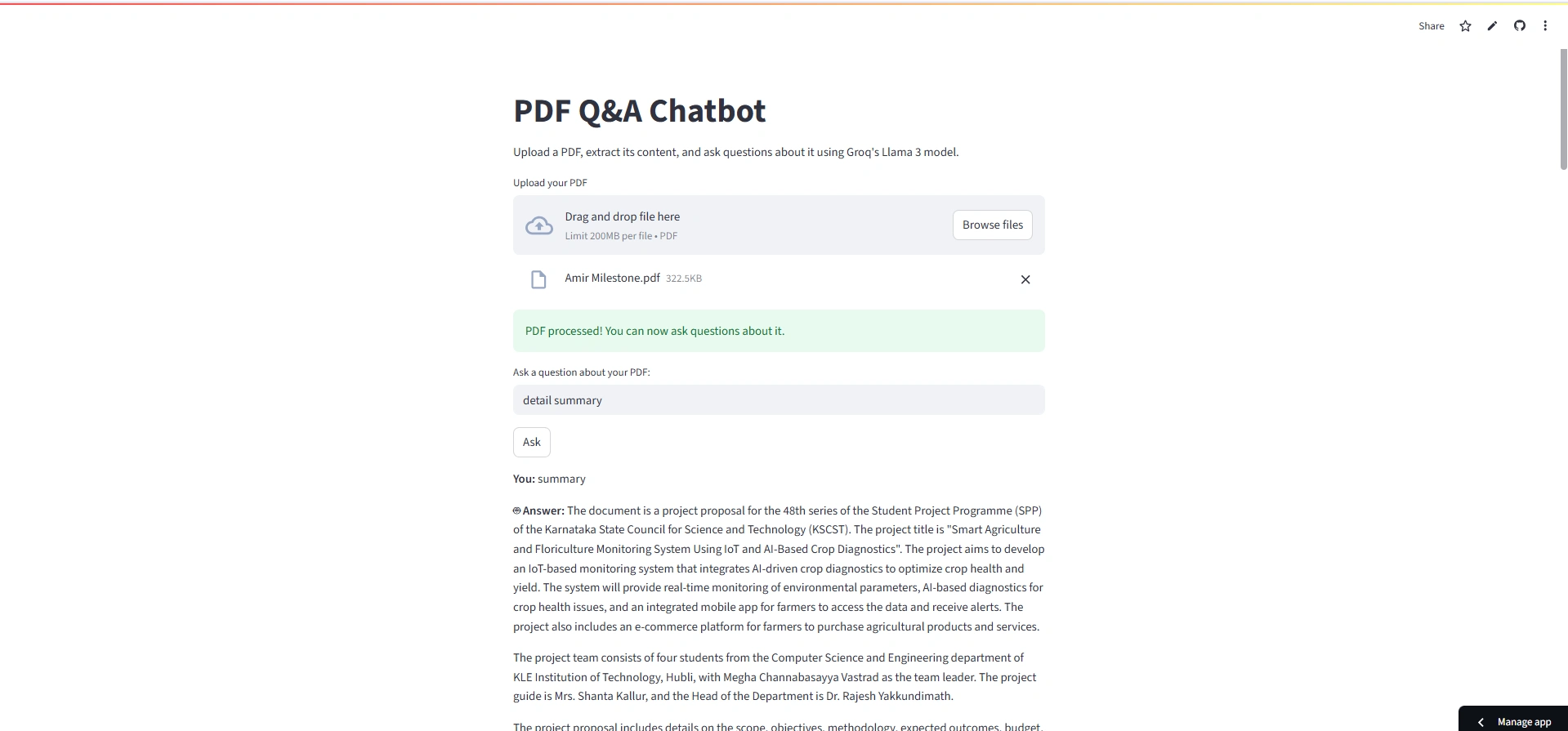
PDF Q&A Chatbot with Groq API
Amir Hamza Betgeri
PDF Q&A Chatbot with Groq API
Overview:
A Python-based chatbot application that allows users to interact with PDF documents using natural language questions. It leverages Groq's LLaMA 3 model to provide intelligent responses based on the content of the PDF.
1. Text and Image Extraction
Extracts complete text and embedded images from any standard PDF file using PyMuPDF.
2. Simulated Image Captioning
Generates placeholder captions for embedded images to provide context, although no real image understanding is performed.
3. PDF Content Summarization
Automatically summarizes extracted text and stores the summary in a structured JSON format for further use.
4. Interactive Question-Answering
Enables users to ask questions related to the PDF content through a terminal-based chatbot powered by Groq's LLaMA 3 model.
5. JSON Output Generation
All extracted and summarized content, including simulated image captions, is saved in a
pdf_summary.json file for reference.6. Terminal-Based Chat Interface
Provides a simple and user-friendly command-line interface for users to interact with the PDF and receive real-time responses.
7. API Integration with Groq
Utilizes Groq's API for natural language processing and response generation, enabling high-quality language understanding.
8. Lightweight and Dependency-Based
Built using lightweight Python libraries with minimal dependencies for ease of setup and use.
Like this project
Posted Jul 29, 2025
Created a PDF Q&A chatbot using Groq API and Python.
Likes
1
Views
3
Timeline
Jul 22, 2025 - Jul 24, 2025
Clients

Groq
Llama