NeuBlog - AI Automated Blog System
Matthew Wood
Example: https://blog.neutalk.io
Welcome to the Future of SEO Blogging
Backstory
NeuBlog was created through a fun experiment with me, and other members of the OpenAI community to find interesting ways to let an LLM search for information before posting.
For my contribution I created a simplified interface that exposed two functions. One to gather relevant news articles on Google News, and another that ingests the article by stripping LLM-irrelevant tags, and returning the content in markdown.
As can be noticed, this was created on December 2023. Over 1 year ago.
Upon creation, a team of community members noted the potential of this type of tool, and told me to continue the project to fruition.
Process
The process of this service is simple and can be broken down into clear pipeline steps:
It's important to note that each LLM is given specific instructions on the company, the CTA, the target audience, and other general background information.
Gather Headlines
Using a theme, a Google News search is conducted. The results of this search is sent to an LLM which determines which headlines seem to being in new, interesting, and potentially contrasting information
Gather Articles
Once the headlines are gathered, each article is ingested, filtered, and converted into markdown
Distill Facts
Each article is distilled into their facts by a capable LLM
Write Article
Using the facts, and optionally keywords to target, a specific LLM is used based on the target audience (Creative VS factual. Educated VS Mass-appeal). The article is written in MDX format. It also creates prompts for imagery for a header and subsections.
At this point we have each step saved locally
Generate Images
The prompts provided by the model for imagery are converted to images using both Veo2 by Google, and Dall-E by OpenAI. The reason behind this is that Veo2 currently has many limitations that Dall-E doesn't. Such as blocking any sort of prompt that implies the presence of people.
Link & Clean
The image prompts generated are replaced with the file reference, and citations are placed to back up all facts with their respective article. Some artifacts created by the LLM are also cleaned up.
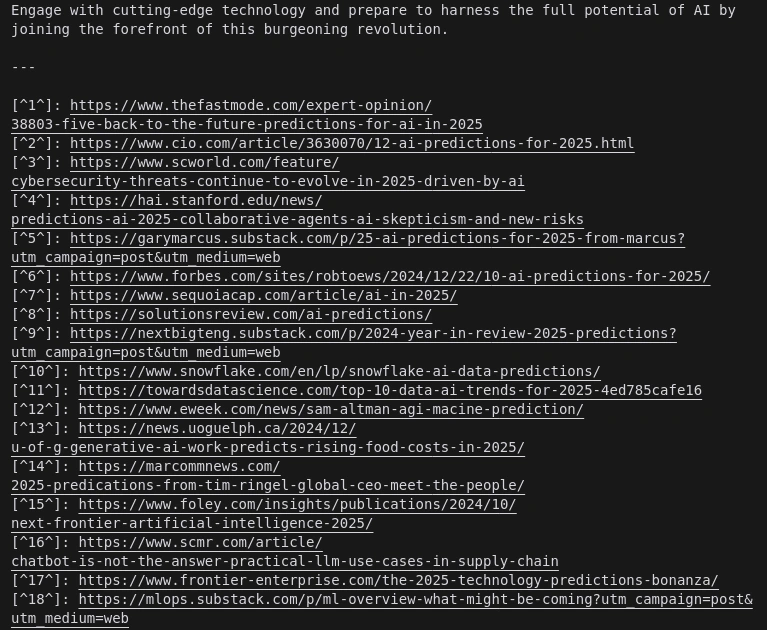
All citations are placed at the bottom and are appropriately linked
Move & Publish
The files are moved to a specific location that is then immediately uploaded to GitHub. Triggering a website update.
All files are moved, and ready to go
The Result - Check for yourself!
Ultimately, we have a fully capable automated blogging system that is up-to-date with recent news. Gathering numerous data-points from numerous sources, distilling it, and synthesizing it all into one potent article.
Warning: There still are some edge-cases with citations. For example, adding two citations together for whatever reason causes the renderer to spit out a different number:
> 2025 is set to witness massive adoption across various platforms and industries[^2^][^7^]
This for whatever reason turns into
Like this project
Posted Jan 3, 2025
An automated blogging system that uses recent Google News, along with company information and SEO. Can also be used to automatically blog projects!