Multi-Document Conversational AI: Chat with PDFs, Word Docs, an…
Chinelo Nweke
Multi-Document Conversational AI: Chat with PDFs, Word Docs, and Text Files Using Streamlit.

·
7 min read
·
Jan 10, 2025
--

Introduction
In today’s world, being able to pull useful information from different types of documents — like PDFs, Word files (DOCX), spreadsheets (CSV), JSON files, and more — is super important for both businesses and researchers. This project is all about creating a chatbot app using Streamlit and LangChain. The cool part? This chatbot won’t just handle PDFs — it’ll work with various document and text file formats to make finding information quick and easy.
This app will also include a user login feature, ensuring each user can interact with their own data securely. The app won’t come with any preloaded data — users will upload their own documents, which will then be stored in the database. Once uploaded, users can ask the chatbot questions and get answers, but only based on their own data. This makes the app personalized, and tailored to each user’s specific needs. These are the steps I took in building and deploying the chatbot app:
Step 1: Environment and Requirement Setup
To kick things off, I started by creating a new repository on GitHub and cloning it to my local machine. This step is important because it gives me a clean, version-controlled space to work on the project. Once the repository was set up, I created an
.env file to securely store my API keys. This way, I could keep credentials out of the code itself and make the app more secure.Next, I created a
requirements.txt file. This file lists all the necessary libraries and dependencies the project will need, such as streamlit, langchain, and others. By having this file, I can easily manage the project’s dependencies and ensure everything runs smoothly. This setup is pretty straightforward but essential because it ensures that the environment is ready to handle the rest of the app’s components.Step 2:User Authentication
I set up user authentication so that users can register and log in using their username and password. To make sure their passwords stay secure, I use SHA-256 hashing, which protects their sensitive info. After logging in, each user can upload their own documents and interact with the chatbot, keeping their data private and accessible only to them.
Step 3: Text Extraction from Documents
Next, the app extracts text from the documents users upload. If they upload PDFs, I use the PyPDF2 library to pull the text from them. For Word documents (DOCX), the app uses the docx library to access the content. If the user uploads a text file, the app processes it just the same. This way, all the content from different file types is turned into raw text that the chatbot can work with.
Step 4:Text Splitting
Once the text is extracted, it needs to be broken down into smaller chunks. This is where LangChain’s
CharacterTextSplitter comes in. This step is super important because it helps the chatbot search through long texts more easily. The text is split into manageable pieces, with a bit of overlap to make sure the context remains intact across different chunks.Step 5:Vector Store Creation
Then comes the part where the app turns the text into something the chatbot can really work with: embeddings. Using LangChain’s FAISS and HuggingFaceEmbeddings, the app converts those text chunks into numerical representations, which are stored in a vector database. This makes it quick and efficient to retrieve information when the user asks a question.
Step 6: Building the Conversational Chain
Now that we have the vector store with embeddings, the app sets up a conversation model using LangChain’s ChatGroq. The model comes with a memory buffer that keeps track of the chat history, allowing the chatbot to respond more intelligently by remembering what’s been said. This means users get answers based on the content they’ve uploaded.
Step 7: Handling User Input
When a user asks a question, the app uses the conversation model to pull the most relevant info from the vector store. It updates the chat history and shows the conversation in real time. The app also refines the chatbot’s responses, cutting out unnecessary phrases and giving direct, clear answers to user queries.
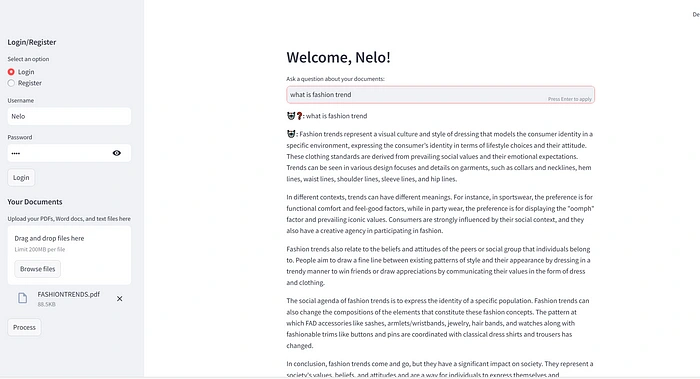
Step 8: User Interface and Document Upload
The app is built using Streamlit, which makes the interface super simple and user-friendly. Users can register, log in, and upload documents directly through the sidebar. The file uploader handles multiple formats, and once the files are uploaded, the app processes them in the background, preparing everything for interaction. The chat interface makes it easy for users to ask questions and read the responses.
Step 9: Running the App
Finally, the app is designed to run smoothly whether locally or on a cloud platform like Streamlit Cloud. The main function kicks things off by initializing all the necessary components — from authentication to document processing and user interactions. Once everything is set up, users are ready to start interacting with their documents in a personalized, engaging way.
Conclusion:
By combining all these tools and technologies, the app makes it easy for users to extract valuable insights from their documents in a seamless, scalable way. Whether it’s PDFs, Word docs, or text files, the chatbot can help users find exactly what they’re looking for.
Note: This is a personal project but for a business, the app should have the ability to store data from user chat history.
You can interact with the app via this link
Here is link to the Github repository
Thank you for reading and please leave your opinion.
You can find me here;
LinkedIn: Chinelo Nweke
x: Nelo Nweke
Like this project
Posted Jan 30, 2025
In today’s world, being able to pull useful information from different types of documents — like PDFs, Word files (DOCX), spreadsheets (CSV), JSON files, and m…
Likes
0
Views
0