Analyzing Customer Energy Consumption Patterns
Mohammed Alsamdani
1.Introduction
The purpose of this project is to analyze a single customer’s energy consumption data over one year to identify patterns and classify usage behaviors. By utilizing data clustering and classification techniques, we aim to create distinct clusters of daily energy usage and build a predictive model to understand future consumption behaviors.
2. Data Overview
The dataset represents one year of energy consumption data with eleven features, providing a comprehensive overview of the customer's daily usage patterns. To effectively analyze this data, we preprocess it into 365 unique days, each containing 24 hourly data points.
2.1 Data Processing
The first step involved transforming the raw data into a structured format that captures daily energy consumption. Key attributes extracted from the data are summarized in Table 1:
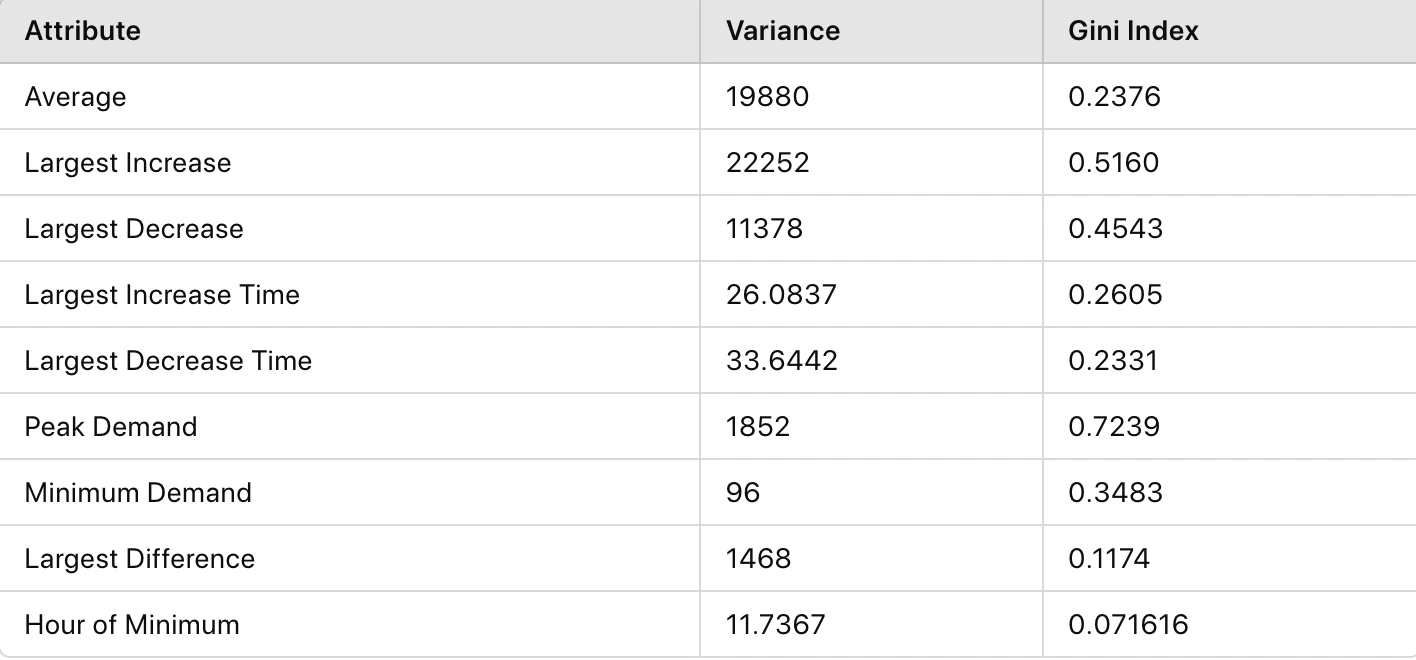
Table 1.
2.2 Clustering Methodology
To identify distinct usage patterns, we applied the K-means clustering algorithm. K-means was chosen for its simplicity and interpretability. An iterative approach was utilized to optimize model parameters, as summarized in Table 2.

Table 2.
2.3 Evaluation Metrics
The Calinski-Harabasz Score, a measure of the ratio of intra-cluster variance to inter-cluster variance, was utilized to determine the effectiveness of the clustering. The goal was to minimize variance within clusters while maximizing variance between clusters.
3. Classification Approach
After clustering, multiple classifiers were evaluated, including Logistic Regression, Linear Discriminant Analysis, and Multi-Layer Perceptron (MLP) Classifier. Ultimately, Logistic Regression was selected due to its superior accuracy, weighted accuracy, and F1-score.
3.1 Performance Metrics
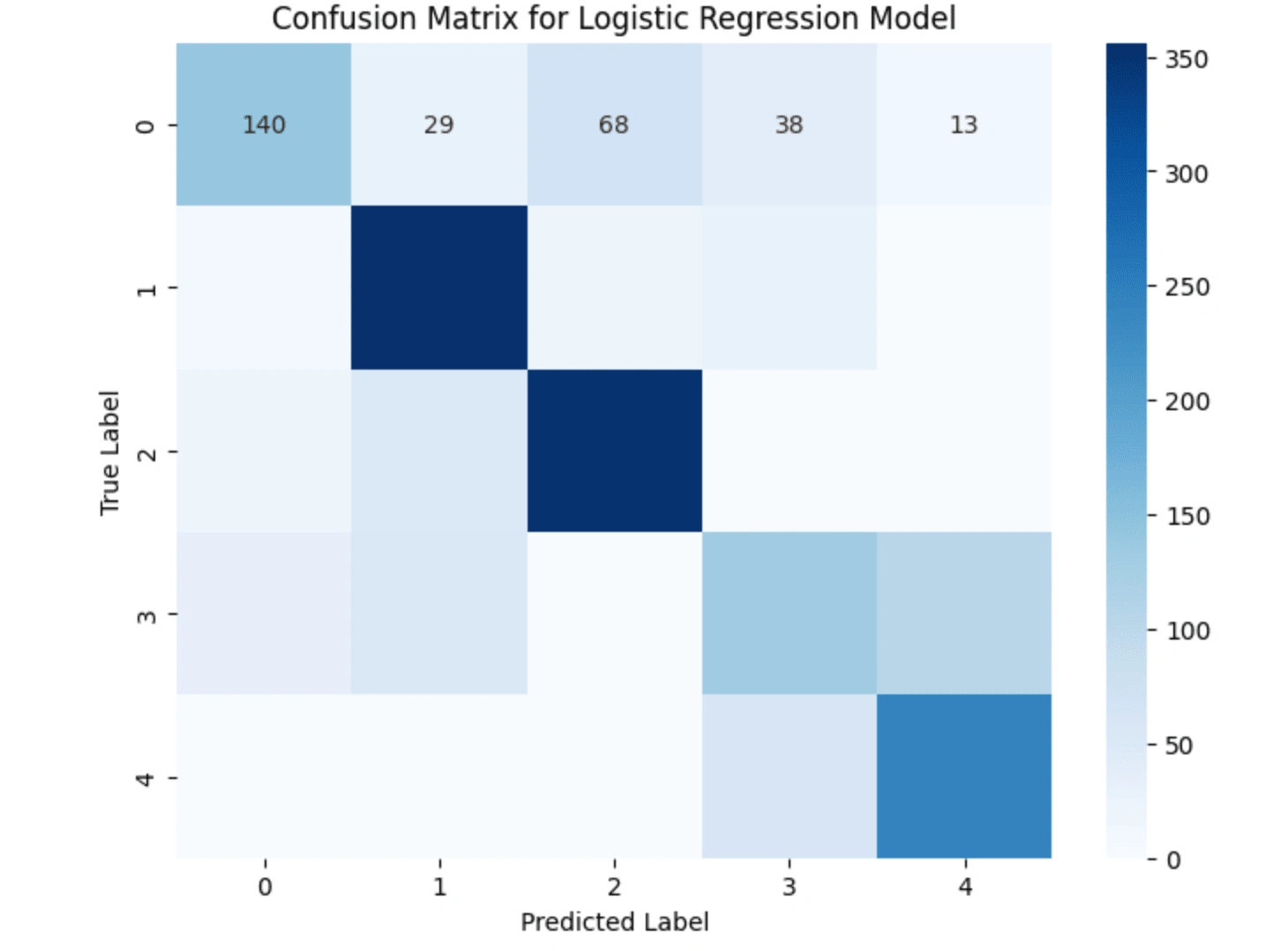
The performance of the Logistic Regression model is detailed in the confusion matrix for logistic regression model below.
Classification Report
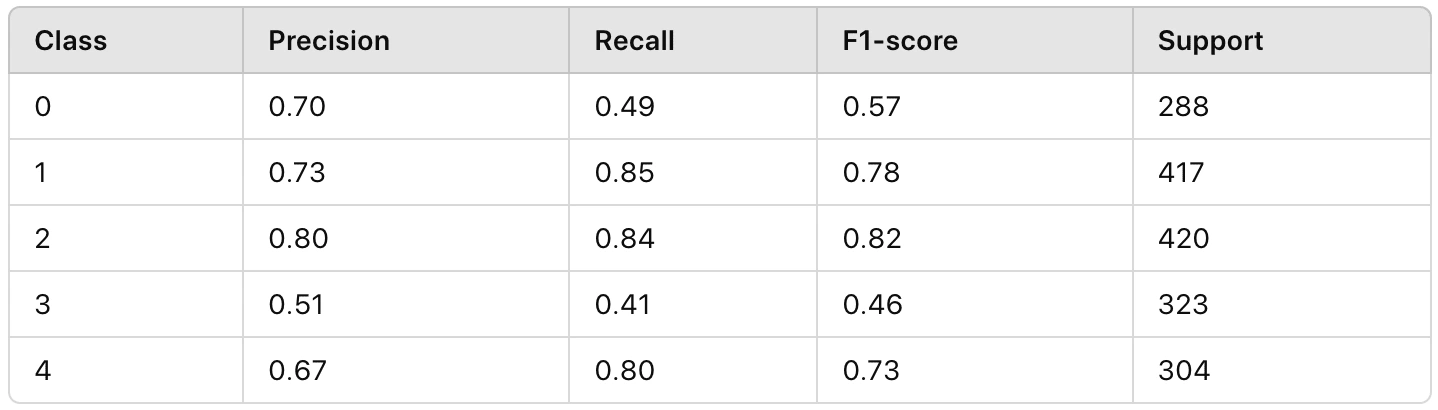
Overall Accuracy
Accuracy: 0.70
Macro Average:
Precision: 0.68
Recall: 0.68
F1-score: 0.67
Weighted Average:
Precision: 0.69
Recall: 0.70
F1-score: 0.69
4. Results Analysis
The results indicate a strong performance in clusters 1 and 2, with high precision and recall scores, demonstrating effective identification of these energy usage patterns. Conversely, clusters 0 and 3 presented challenges, particularly cluster 3, which showed lower performance metrics across all classifications.
5. Conclusion
The project successfully analyzed a year’s worth of energy consumption data, leading to the development of a classification model capable of predicting future consumption behaviors. While the overall accuracy was commendable, there are clear areas for improvement, especially regarding less accurately classified clusters. Future work will focus on enhancing model performance through additional data exploration, feature engineering, and model optimization strategies.
Like this project
Posted Sep 29, 2024
Designed and managed the implementation of renewable energy solutions for urban areas, focusing on solar and wind integration.