Image Similarity Search System Development
Ratnapriya Lal
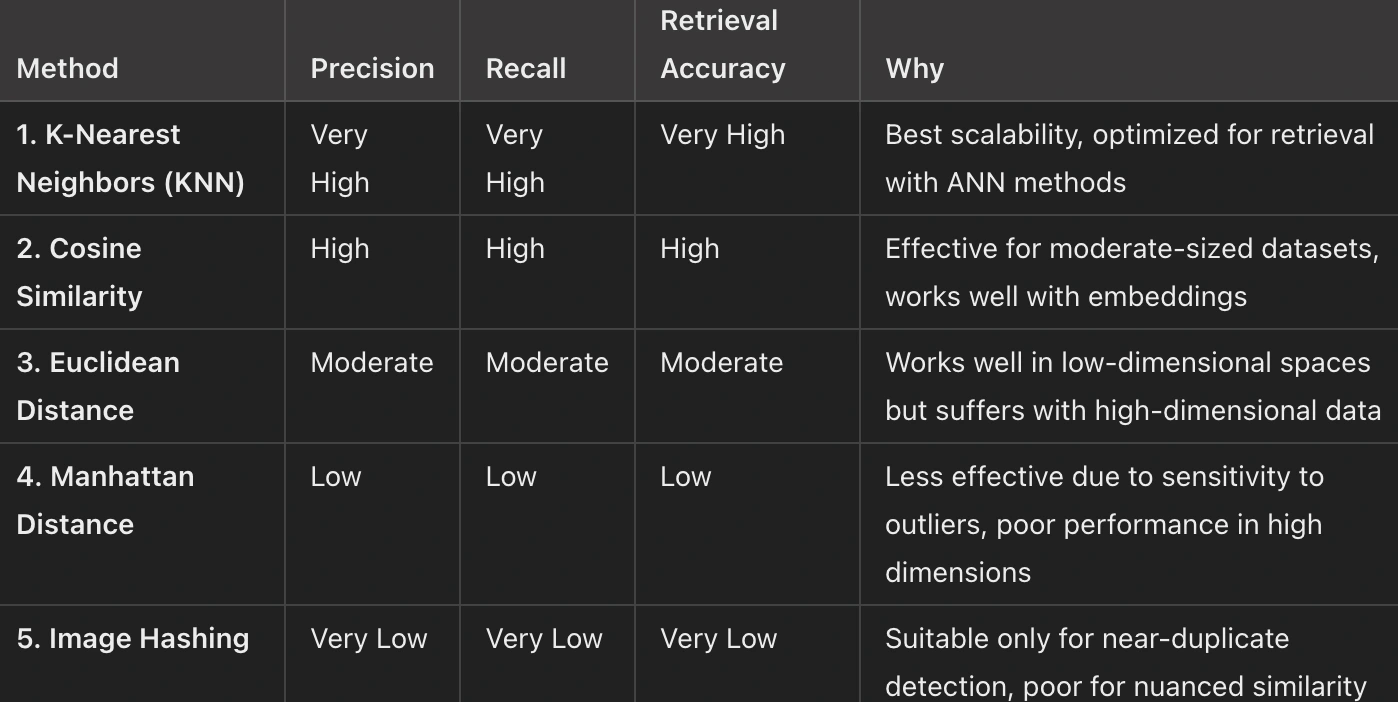
Image Similarity Search System
Objective
This project aims to develop an alternative to Google Lens by implementing image similarity search using multiple deep learning approaches. The goal is to provide a system that can compare a query image with a database of images and find the most similar ones based on various similarity measures.
The project proposes different methods to perform similarity search, leveraging feature extraction and various neural network models, including autoencoders, Convolutional Neural Networks (CNNs), and more.
Methods Implemented
In this implementation, we used a feature extraction model from TensorFlow Hub and cosine similarity to measure the similarity between images. The specific method used here is based on extracting high-level features (embeddings) from images and comparing them to find the most similar ones. Below are some of the methods that can be used in this project to perform image similarity search:
Cosine Similarity: Measures the cosine of the angle between two vectors.
Euclidean Distance: Measures the straight-line distance between two points in a feature space.
Manhattan Distance (L1 Norm): Measures the sum of absolute differences.
K-Nearest Neighbors (KNN): Classifies the closest k neighbors based on a distance metric.
Image Hashing (e.g., Perceptual Hashing): Converts images into fixed-size hashes and compares them.
Summary: Efficiency and Scalability Ranking (Best to Worst)
K-Nearest Neighbors (KNN): Best method for real-time, large-scale similarity search, especially with advanced indexing like KD-Trees, Ball Trees, or ANN methods. Time Complexity: O(N * d), where N is the number of images and d is the dimensionality of the feature space.
Cosine Similarity: Suitable for moderate-scale applications, though it suffers in scalability for large datasets. Good for normalized embeddings. Time Complexity: O(N * d), where N is the number of images and d is the dimensionality of the feature vector.
Euclidean Distance: Efficient for low-dimensional spaces, but struggles with high-dimensional data. Less efficient than cosine similarity at scale. Time Complexity: O(N * d).
Manhattan Distance: Similar to Euclidean but less commonly used in practice. Offers less performance benefit and scalability than other methods. Time Complexity: O(N * d).
Image Hashing (e.g., Perceptual Hashing): Quick but not effective for nuanced similarity detection. Best suited for duplicate detection or smaller datasets. Time Complexity: O(1).
Summary: Performance Ranking (Best to Worst)
(* Analysis on the basis of functionality and evaluation metrics due to lack of labelled dataset)
Conclusion:
For real-time similarity search, KNN with Approximate Nearest Neighbors (ANN) is the most effective method, balancing precision, recall, and retrieval accuracy. Cosine similarity comes close, especially for moderate-sized datasets, but it lacks the optimizations that KNN provides for scalability. Euclidean and Manhattan distances are effective in low-dimensional spaces but struggle as the dataset and dimensionality increase. Image hashing, while fast, is limited to detecting near-duplicates and performs poorly in real-time similarity searches.
Like this project
Posted May 5, 2026
Developed an image similarity search system using deep learning techniques.
Likes
0
Views
3