Custom Voice AI Orchestration Engine (LiveKit)
Jin Park
Proprietary Voice AI Orchestration Engine
A custom-built Voice AI backend designed to replace commercial wrappers like Vapi and Retell.
I engineered this proprietary orchestration layer to demonstrate that high-performance voice agents do not require expensive third-party middleware. By building the engine from scratch using LiveKit, I achieved full ownership, significant cost savings, and granular control over the conversational pipeline.
🚀 Production Status: This engine is currently deployed in production as the core voice AI infrastructure for my voice AI Saas for dental clinics, a vertical SaaS platform handling real-time appointment scheduling for 20+ dental clinics across Canada.
Core Technical Components
🔄 Dynamic Agent Configuration
Real-Time Hydration: Implemented a
get_agent_configuration function that executes an API call to the application backend upon initialization.Hot-Swappable Personas: Dynamically retrieves and applies agent settings such as Agent Name, System Prompt, Welcome Message, Temperature, and Voice ID. This allows a single engine instance to serve infinite unique agent personas based on backend parameters.
🛠️ Context-Aware Function Router
Dynamic Tool Injection: Developed a helper function that automatically assigns specific tools and capabilities to the agent based on the configuration received from the backend.
Modular Logic: This router decouples the orchestration engine from specific business logic, ensuring the agent only loads the functions required for the specific use case (e.g., loading "Appointment Booking" tools only when configured).
💾 Data Persistence & Post-Call Intelligence
Full-Cycle Storage: A
save_conversation function that aggregates the session payload and pushes it back to the backend. This triggers two critical sub-functions:Call Summary: Generates a concise natural language recap of the conversation.
Call Evaluation: Performs a structured quality check to classify the call outcome (e.g., "Booked", "Inquiry", "Failed").
Granular Metrics: Captures critical engineering metrics including Token Usage (for precise billing) and Latency statistics alongside the message history.
🛡️ Production Guardrails
Inactivity Monitor: A background process that actively monitors user audio input. If silence is detected for 30 seconds (default/adjustable), the session automatically terminates to prevent "zombie" connections and wasted resources.
Session Limit Monitor: A hard safety stop that enforces a maximum call duration (default: 15 minutes). This prevents infinite loops or abuse that could lead to runaway LLM/Telephony costs.
⚙️ Get Agent Configuration
File:
get_agent_configuration.py
This function is responsible for the real-time hydration of the voice agent. Instead of hardcoding behavior, it executes a synchronous API call to the application backend immediately upon call initialization.Dynamic Retrieval: Fetches the specific
Agent Name, System Prompt, Welcome Message, Temperature, and Voice ID associated with the phone number.Hot-Swapping: Enables a single engine instance to power infinite unique personas, allowing for instant updates to agent behavior without redeploying the code.
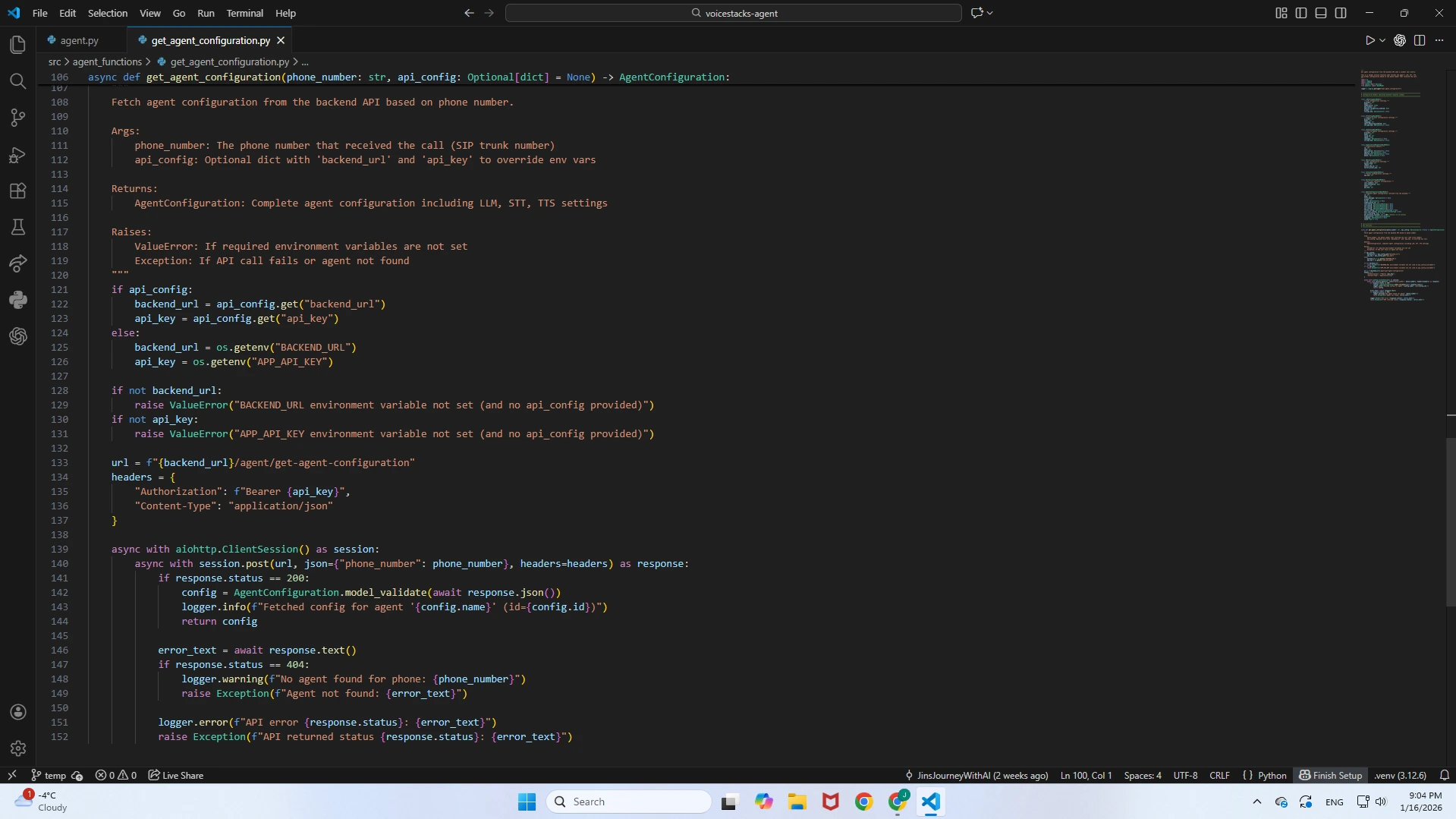
Get Agent Configuration
💾 Save Conversation
File:
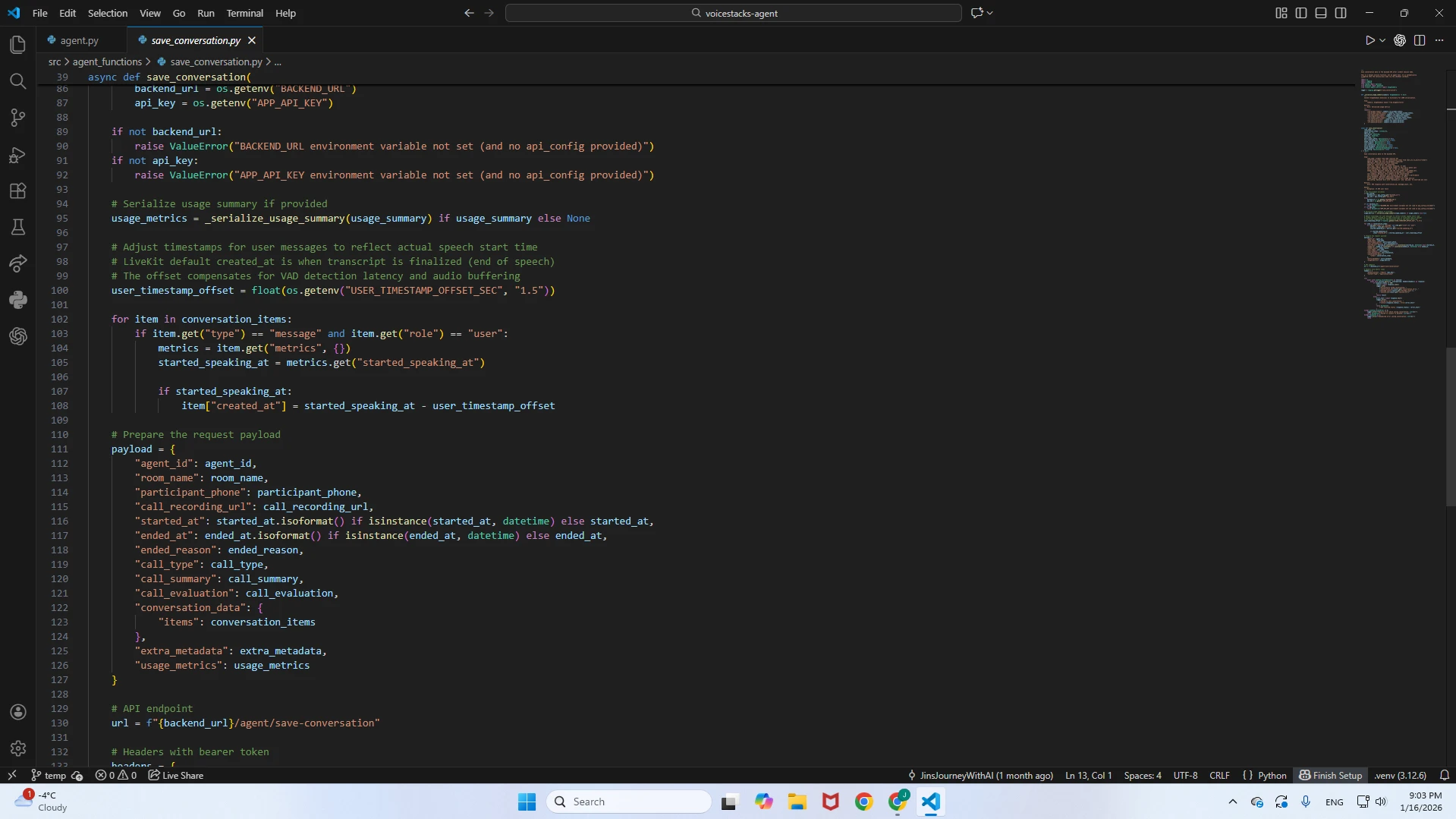
save_conversation.py
The comprehensive data persistence layer that executes immediately after a session ends. It aggregates the session payload and pushes it back to the main application backend.Telemetry & Metrics: Logs full transcripts, function calling history, token usage (for billing), and latency statistics.
Post-Call Intelligence: Triggers two critical sub-functions:
Call Summary: Generates a concise natural language recap of the conversation.
Call Evaluation: Performs a structured quality check to classify the call outcome (e.g., "Booked", "Inquiry", "Failed") for analytics.
Save Conversation
🛠️ Function Router
File:
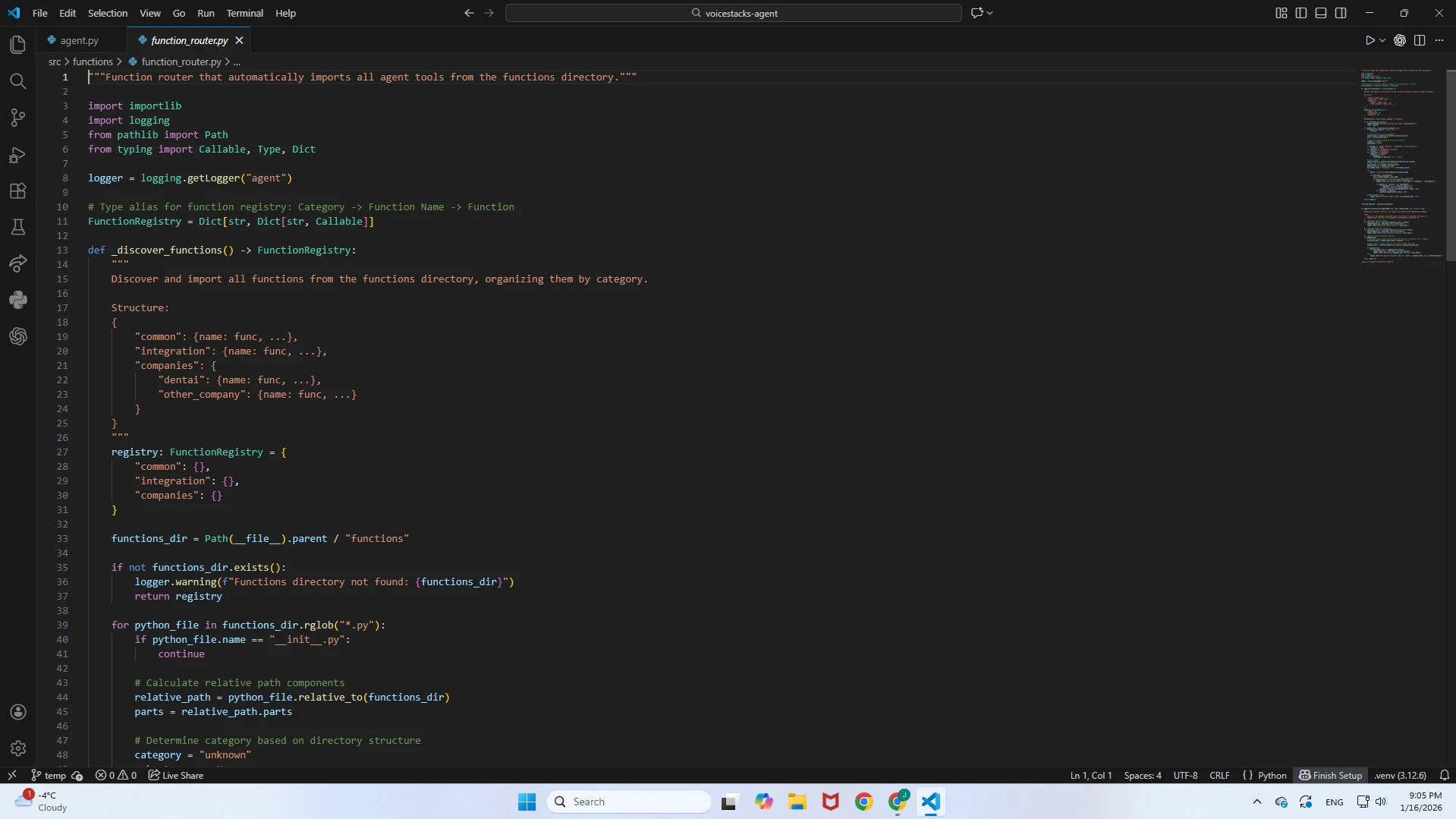
function_router.py
A specialized helper function that acts as the bridge between the configuration and the agent's capabilities.Context-Aware Injection: Parses the configuration received from
get_agent_configuration and dynamically assigns only the necessary tools to the agent.Modular Architecture: Decouples the core orchestration engine from specific business logic, ensuring the agent is lightweight and only loads tools relevant to the specific use case (e.g., loading "Appointment Booking" tools only for dental clients).
Function Router
💤 Inactivity Monitor
File:
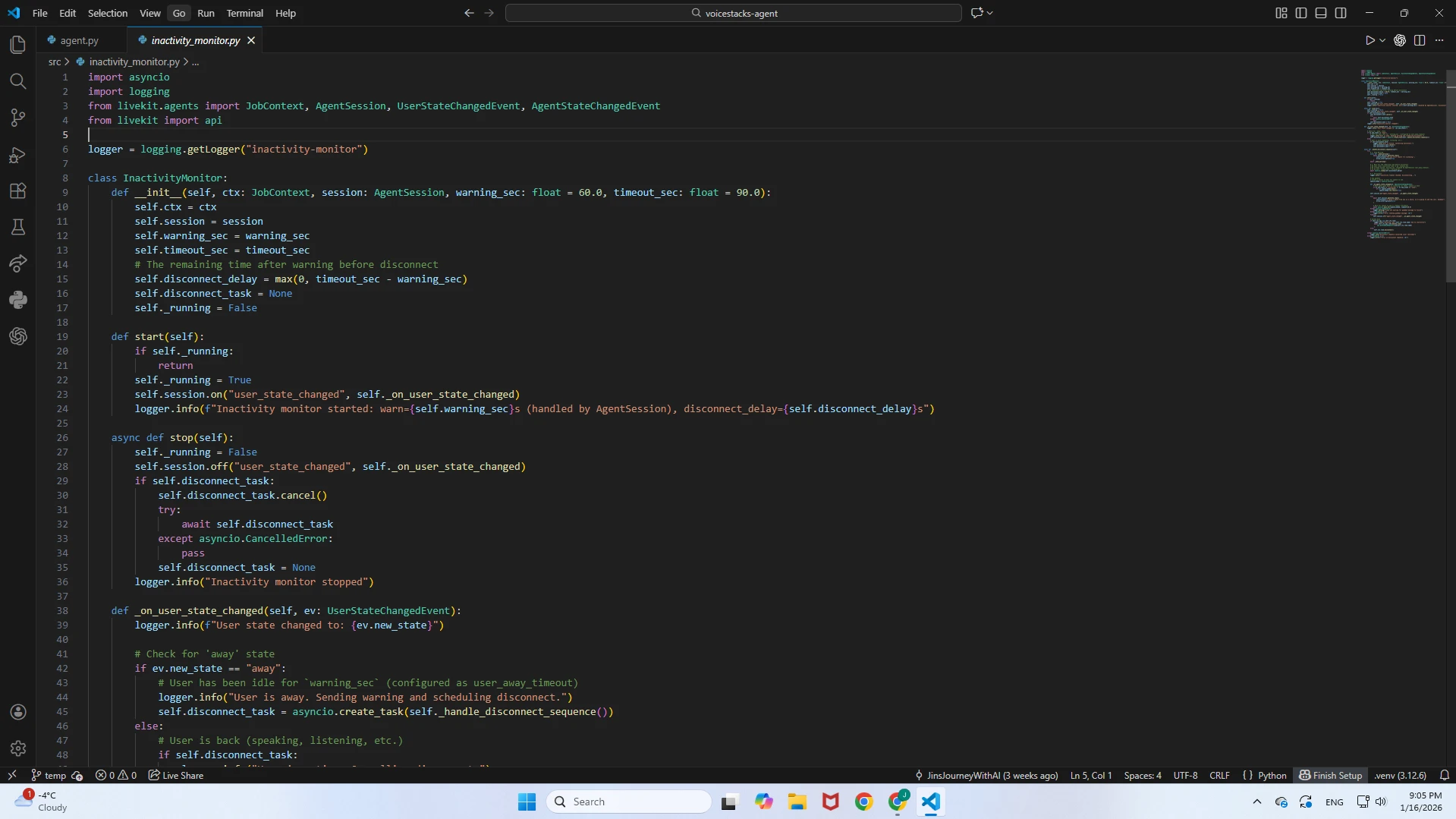
inactivity_monitor.py
A background process designed to manage connection hygiene and resource efficiency.Silence Detection: Actively monitors the user's audio input stream in real-time.
Auto-Termination: If the user remains silent for 30 seconds (default/adjustable), the monitor gracefully closes the session. This prevents "zombie" connections where a user walks away but leaves the line open.
Inactivity Monitor
⏳ Session Limit Monitor
File:
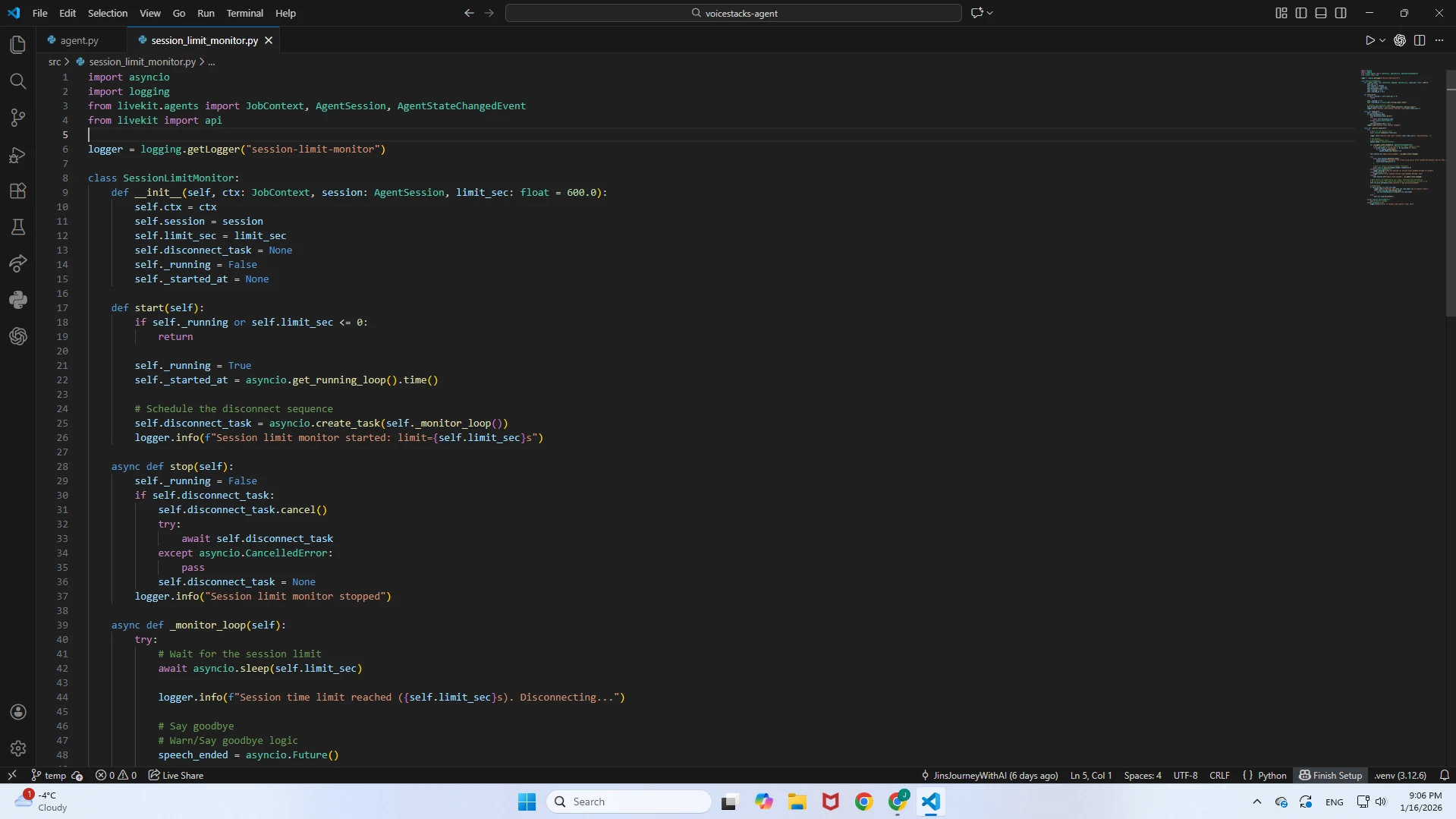
session_limit_monitor.py
A critical production guardrail that enforces hard limits on interaction length.Cost Control: Enforces a maximum call duration (default: 15 minutes, adjustable).
Abuse Prevention: Acts as a safety stop to prevent infinite loops or malicious usage that could lead to runaway LLM and telephony costs.
Session Limit Monitor
Like this project
Posted Jan 17, 2026
Proprietary Voice AI engine replacing Vapi/Retell. Powers SaaS with full orchestration: storage, dynamic agents, functions & monitoring. Seamless integration.
Likes
0
Views
5