HUMOUR DETECTION USING NLP
TechAPeek Services
PROBLEM STATEMENT
The field of Natural Language Processing (NLP) has experienced a notable surge in interest in the domain of humour detection, aiming to computationally discern the nuanced aspects of humour in text. This research addresses the multifaceted challenge of understanding and identifying humour in written content, centring around jokes. The ultimate goal of this study is to advance our comprehension of humour detection using NLP techniques and provide practical solutions for applications that require the recognition of humour in text.
KEY OBJECTIVES
1. Exploration of Humour in Text Data: The primary objective of this research is to delve into thedistinctive characteristics of humour, encompassing elements like wordplay, punctuation ratio,and tag ratio, by conducting an Exploratory Data Analysis (EDA) on a dataset of textual content classified as either humorous (jokes) or non-humorous (plain text).
2. Feature Engineering for Humour Identification: The study aims to develop effective feature engineering techniques, including Part-of-Speech (POS) tagging, tokenization, and punctuation ratio analysis, to gain insights into linguistic and structural attributes that distinguish humorous texts from non-humorous ones.
3. Visualizing Elements that Construct Humour: By constructing box plots and other visual representations, the research intends to depict the distribution of linguistic and structural features across humorous and non-humorous text categories, shedding light on the differences that contribute to humour identification.
4. Supervised Learning Models: Employing various supervised learning techniques, such as the Naive Bayes classifier, Random Forest, and advanced Pre-Trained Language Models like XLNet and BERT, the study seeks to classify text as humorous or non-humorous, providing a systematic approach for automating humour detection.
5. Comparative Analysis of Models: The research will undertake a comprehensive comparative analysis of the performance of different models in humour classification, aiming to determine which techniques and architectures are most effective for identifying humour in text.
SIGNIFICANCE
This research aims to bridge the gap between computational systems and human humour perception, contributing to the evolving field of humour detection using NLP. Humour Detection has numerous real-world applications, but is a challenging task in NLP. Understanding and automating the recognition of humour in text can enhance various applications such as sentiment analysis, chatbots, content filtering, and recommendation systems. Furthermore, the study's findings will provide valuable insights into the linguistic and semantic aspects of humour, advancing our comprehension of this complex facet of human communication
ABSTRACT
The field of Natural Language Processing (NLP) has witnessed a surging interest in the elusive realm of humour detection. Humour, deeply rooted in the human experience, has posed a unique challenge for computational systems. Researchers have embarked on diverse endeavours to computationally recognize humour, ranging from the exploration of wordplay within jokes to the identification of humorous texts and satire in social media. These studies span a spectrum of methodologies and approaches, incorporating theories of humour, linguistic and semantic features and machine-learning techniques. From the computational recognition of wordplay through Raskin's theory of humour to the employment of word-association-based semantic features that surpass traditional methods, the research landscape is rich and diverse. Generative language models and pre-trained language models, such as BERT and Transformer architectures, play pivotal roles in this domain, offering novel avenues for humour detection. Furthermore, comparative studies explore the intersection of irony detection and established humour classification techniques, shedding light on their efficacy. This diverse array of methodologies and models collectively contributes to the evolving field of humour detection using NLP.
LITERATURE REVIEW
The realm of NLP has seen increased interest in humour detection, with researchers exploring various methods to computationally recognize humour, including wordplay in jokes, satire on social media, and humorous text in online reviews and tweets. These studies leverage theories of humour, linguistic and semantic features, machine learning techniques, and external text sources to understand how machines can detect humour in written language.
Key Studies in Humour Detection:
Taylor and Mazlack (2004): Focused on wordplay in "Knock Knock" jokes, using Raskin's Semantic Theory of Verbal Humour. They developed algorithms to recognize joke structures and punchlines but found challenges in validating humorous utterances.
Cattle and Ma (2018): Used word-association-based semantic features to detect humour, outperforming traditional methods like Word2Vec. Their approach, tested on the Pun of the Day and 16000 One-Liner datasets, showed significant improvements in humour recognition.
Barbieri and Saggion (2014): Examined irony and humour detection on Twitter, using a classification-based approach with features like frequency, sentiment, and ambiguity. Their model improved cross-domain classification performance.
Barbieri, Ronzano, and Saggion (2015): Explored multilingual satirical news detection on Twitter using both language-independent and dependent features. Their system effectively classified satirical content across English, Spanish, and Italian tweets.
Weller and Seppi (2019): Introduced a Transformer-based model for humour detection, achieving high accuracy on Reddit's Puns and Short Jokes datasets. Their model demonstrated human-like performance in recognizing jokes.
Morales and Zhai (2017): Employed generative language models and external text sources like Wikipedia to identify humour in reviews. Their approach achieved high accuracy and highlighted the broader applicability of humour detection in identifying helpful reviews.
Annamoradnejad (2020): Developed a method using BERT sentence embeddings and neural networks, achieving a 98.2% F1 score in humour detection. They used a large, curated dataset of formal short texts for evaluation.
Miraj and Aono (2021): Proposed a framework combining BERT and various embedding methods with deep neural networks for humour detection. Their approach effectively assessed the funniness of sentences, using techniques like Bi-GRU and multi-kernel convolution.
These studies collectively explore the complex world of humour detection in text, employing diverse methodologies such as feature engineering, supervised learning models, and advanced pre-trained language models like BERT and XLNet. The research highlights the importance of contextual understanding, linguistic features, and external text sources in developing robust humour detection systems, contributing significantly to the field of Natural Language Processing (NLP).
ABOUT THE DATASET
The dataset that has been used in this research has been taken from Kaggle, titled ‘Jokes Detection’. It is a very popular dataset and is widely used by researchers in the NLP domain. It has 2,00,000 unique text records, which are classified as humorous or non-humorous (joke or plain text) via the ‘humour’ variable. The dataset is balanced, containing 50% True and 50% False values for the humour variable. Following is the snapshot of the data as a pandas data frame:
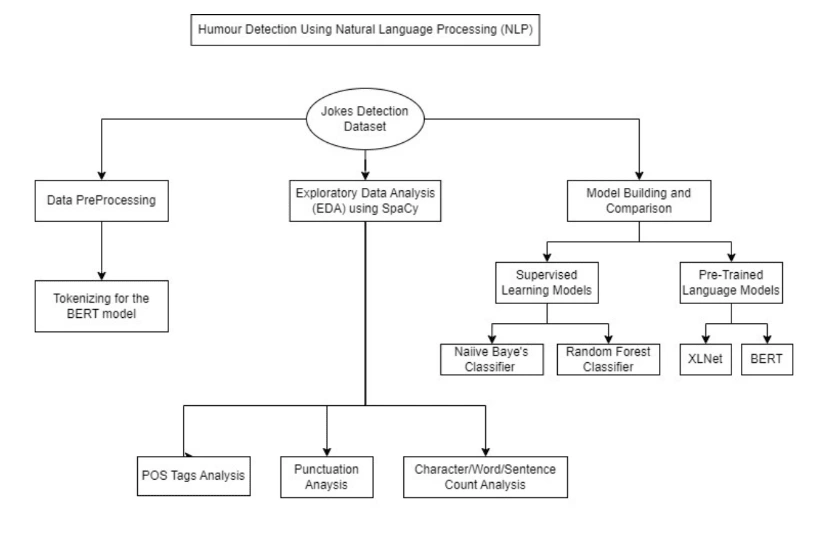
RESEARCH DESIGN FLOWCHART
DATA PREPROCESSING
Tokenization: Tokenizing in NLP is the process of breaking down text into individual units, or tokens, like words or sub-words. Transformers, such as BERT, use sub-word tokenization to handle various languages and morphological variations efficiently. Tokenization in BERT is critical because it allows text to be transformed into numerical representations while preserving the context. These tokenized sequences are then used as input to deep neural networks, enabling BERT to capture rich contextual information and achieve state-of-the-art results in various NLP tasks. Tokenizing in BERT architecture serves as the initial step, allowing the model to comprehend language and extract intricate patterns within the text.
EXPLORATORY DATA ANALYSIS (EDA)
1. Wordplay Comparisons between Humorous and Non-Humorous Texts
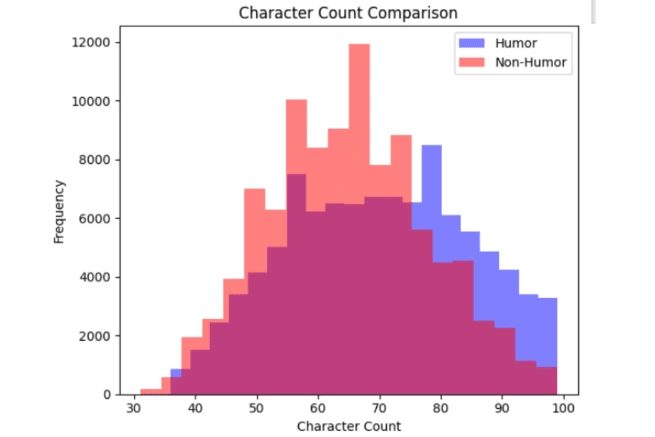
Taking a look at the character count comparison histogram, according to their frequencies, we observe that more no. of non-humorous texts have a lower character count as compared to the humorous texts, which tend to have a higher character count.
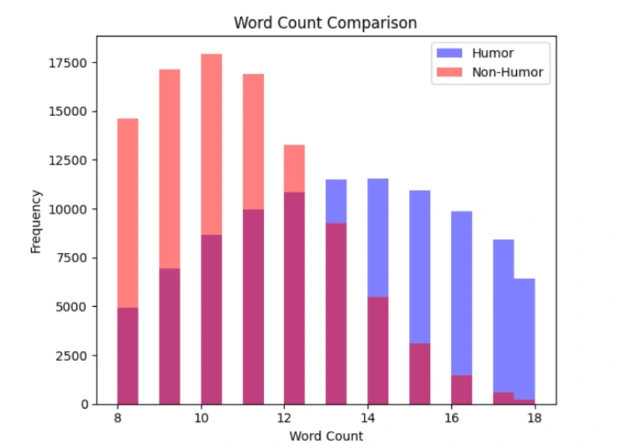
From the above Word Count Comparison Graph, we can observe that the frequency of low-word-counted (8 to 12) non-humorous texts is quite higher than the humorous texts, which tend to have a higher word count comparatively.
2. How Proportionate is the Data
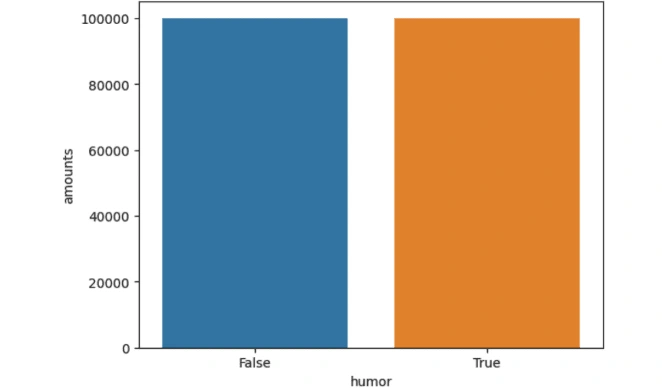
We can see from the above plot that the data is balanced between the two categories humorous and non-humorous texts. Having an equal balance between jokes and non-jokes is crucial. Understanding the data proportion is vital because if it's significantly imbalanced, the model may become biased towards the category with more data, impacting its performance. In such cases, the model is more likely to favour the label with a larger training dataset due to a better understanding of the same.
3. How Frequently Does the Question Mark ‘?’ Symbol Appear
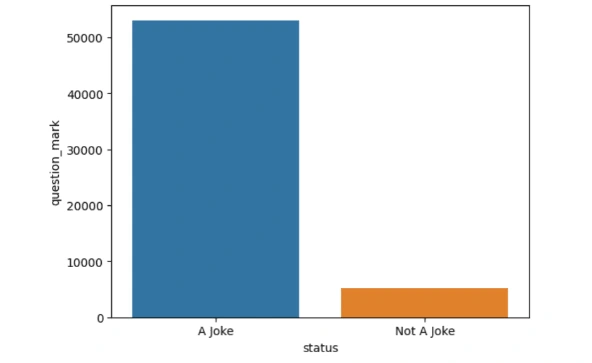
From the above barplot, it's evident that the question mark is more prevalent in data labelled as jokes. Out of 100,000 data samples, over 50,000 contain a question mark, while those labelled as "_not_ajoke" consist of only around 5,000. Consequently, we can conclude that text classified as jokes has a greater tendency to include question marks.
4. Punctuations Analysis
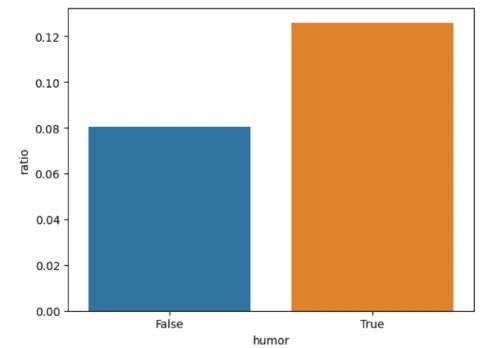
From the above plot, we can observe that the ratio of punctuations (0.12) is greater in humorous texts as compared the non-humorous texts (0.08), validating our previous observation as well.
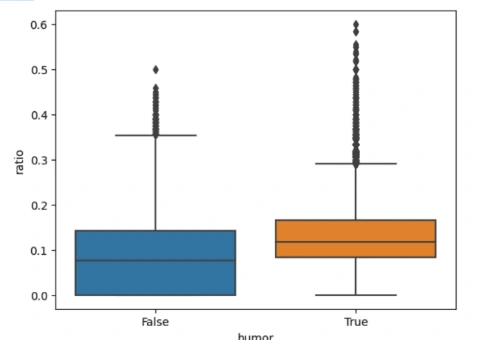
The boxplot above reveals that, on average, humorous content contains more punctuation marks compared to non-humorous content. It's worth noting that jokes often have a specific structure. A well-crafted joke is expected to be somewhat unpredictable, but it should still adhere to a recognizable structure commonly found in modern comedy. This structure typically involves a series of setups leading to a punchline. To maintain this structural order, punctuation marks are frequently used. This explains why punctuations are more prevalent in jokes.
5. POS Tags Analysis
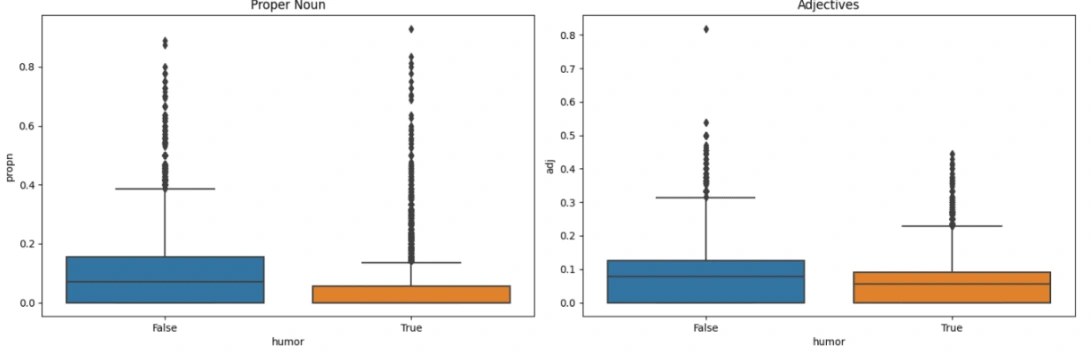
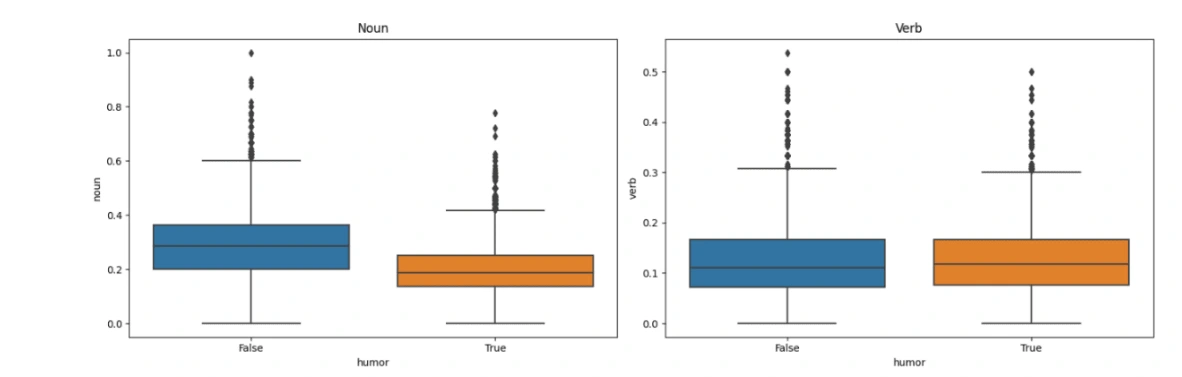
In the comparison above, we have examined the frequency of Nouns, Proper Nouns, Verbs, and Adjectives in texts with the help of boxplots. This analysis provides insights into the characteristics of jokes.
Based on the visualizations, it is evident that non-joke texts tend to contain a higher number of Proper Nouns, Adjectives, and Nouns. This suggests that non-joke texts may lean towards formality, resulting in an increased occurrence of these language elements. Consequently, we can infer that the formality of a text is associated with a greater presence of Proper Nouns, Adjectives, and Nouns.
CLASSIFYING TEXTS AS HUMOROUS AND NON-HUMOROUS
1. BERT Pre-Trained Language Model
BERT, or Bidirectional Encoder Representations from Transformers, is a leading NLP model. It excels in humour detection by understanding the context and nuances of language.
In humour detection tasks, BERT is fine-tuned using labelled datasets that include humorous and non- humorous text examples. BERT's bidirectional nature enables it to recognize linguistic patterns and context that contribute to humour, making it effective at identifying humour in text, such as jokes in social media posts, funny content in scripts, or humour in chatbots.
i. Preprocessing: Cleaning and preparing the dataset (if required).
ii. Tokenization: Tokenize the text using a BERT tokenizer.
iii. Cross Validation: Splitting the dataset into training set and validation set
iv. Making Datasets and Data Loaders using PyTorch
v. Fine-tuning: Training the BERT-based model for the classification task.
vi. Evaluation: Assessing model performance using accuracy score and confusion matrix.
vii. Inference: Using the model for humour classification on new text data.
2. Naive Baye’s Classifier
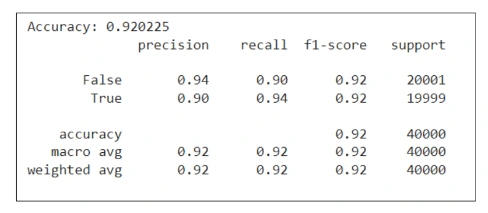
From the above evaluation metrics table, we observe that the performance of the Naiive Bayes classifier is reasonably well (with 92% accuracy), although, not surpassing the BERT model.
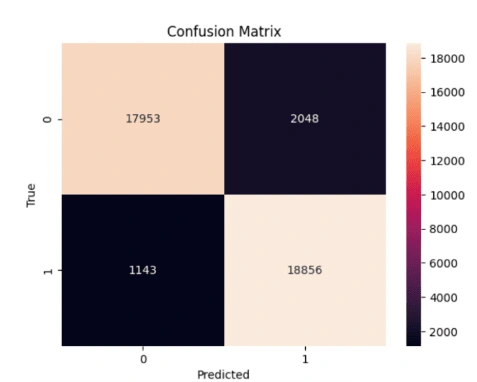
Upon analyzing the confusion matrix, we notice that most of the incorrect predictions occur when the model mistakenly categorizes a non-joke as a joke. The number of such incorrect predictions is relatively more than the BERT model.
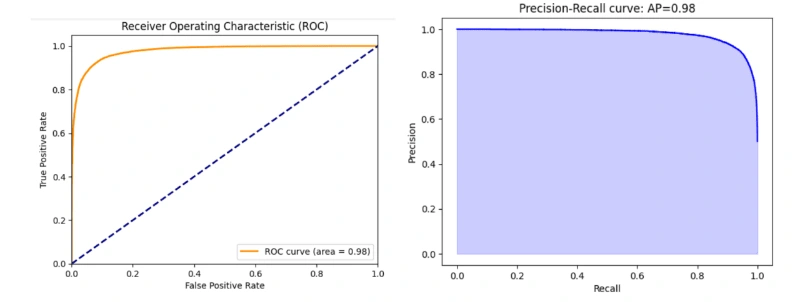
The ROC (Receiver Operating Characteristic) curve with an area under the curve (AUC) of 0.98 is an indication of a highly accurate binary classification model. The ROC curve is a graphical representation of the trade-off between a model's true positive rate (sensitivity) and its false positive rate (1-specificity) across different classification thresholds.
3. Random Forest Classifier
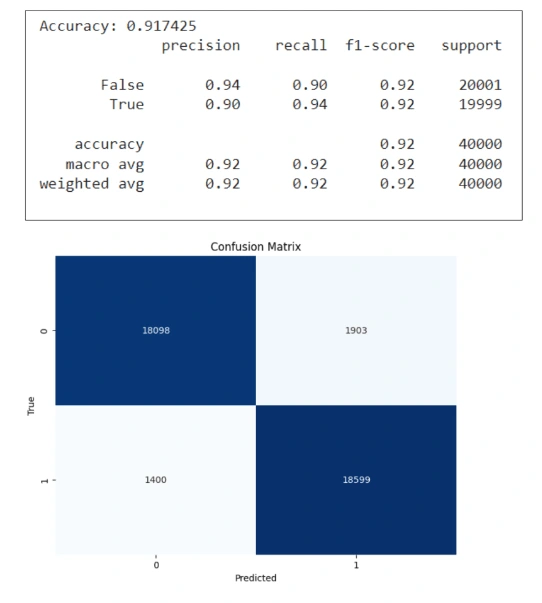
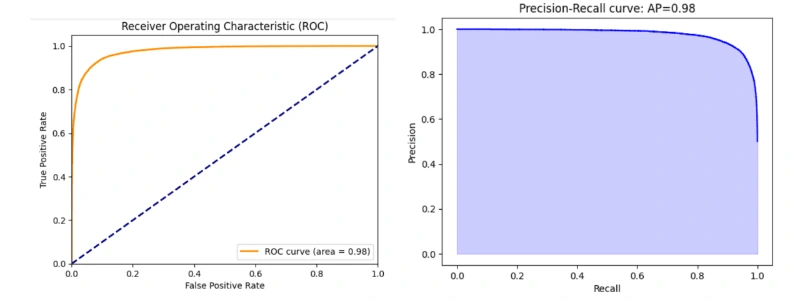
On observing the Random Forest evaluation metrics, we can see and infer that although its accuracy is significant (91.7%), it is still lower than the Naiive Bayes Model. Therefore, we can conclude that the BERT pre-trained model is more effective than the Naiive Baye's and Random Forest classifier models.
RESULTS
1. The frequency of non-humorous texts having a lower character count is higher as compared to humorous texts, which tend to have a higher character count.
2. The frequency of low-word-counted (8 to 12 words) non-humorous texts is quite higher than the humorous texts (for the given dataset), which tend to have a higher word count comparatively.
3. Question marks were found to be more prevalent amongst texts classified as jokes. Consequently, we can conclude that humorous texts have a greater tendency to include question marks.
4. On average, humorous content contains more punctuation marks compared to non-humorous content. A good joke is both surprising and follows a familiar comedic structure, often consisting of setups that lead to a punchline. Punctuation plays a significant role in maintaining this structure, which is why jokes tend to have more of it.
5. Non-joke texts tend to contain a higher number of Proper Nouns, Adjectives, and Nouns. This suggests that non-joke texts may lean towards formality, resulting in an increased occurrence of these language elements.
6. The BERT pre-trained model is more effective than the Naiive Baye's and Random Forest classifier models. Amongst the latter two, Naiive Baye’s Classifier proved to be slightly more effective than the Random Forest model.
CONCLUSION AND RECOMMENDATIONS
The field of natural language processing (NLP) is currently dominated by the Transformer architecture, which is evident by our research via implementing the BERT model and comparing it with the other Supervised ML techniques. This trend is expected to continue for several years. As demonstrated in this study, we've showcased the effectiveness of this approach. With a relatively short training time, we were able to achieve excellent model performance via the BERT pre-trained language model. In the realm of humour detection, we customized the BERT model and fine-tuned it for our specific task, which, in this instance, involves classifying text as either a joke or not.
Following are some recommendations based on our study:
1. Leverage Transformer Architectures: The study highlights the effectiveness of Transformer architectures, particularly the BERT model, for humour detection. It's recommended to explore and leverage these architectures for various NLP tasks, as they offer state-of-the-art performance.
2. Fine-Tuning for Specific Tasks: Fine-tuning pre-trained language models like BERT for specific tasks within humour detection can significantly boost model performance. Researchers and practitioners should consider fine-tuning models to align with their specific humour-related goals.
3. Punctuation Analysis: Given the prevalence of punctuation in humorous texts, researchers can further investigate the role of punctuation in humour detection. Developing models that explicitly capture and analyse punctuation can improve humour classification.
4. Semantic Analysis: Analysing the use of Proper Nouns, Adjectives, and Nouns can provide insights into the differences between humorous and non-humorous texts. Future studies may explore how semantic analysis can enhance humour detection accuracy.
5. Model Selection: While BERT outperformed Naive Bayes and Random Forest models in this study, it's essential to choose the right model based on the specific task and dataset. Researchers should experiment with various models to find the most suitable one for their context.
6. Real-World Applications: Humour detection has various real-world applications, such as sentiment analysis, content recommendation, and chatbots. Integrating humour detection into these applications can enhance user experience and engagement.
7. Multilingual Humour Detection: Extending humour detection models to multiple languages can have broader applications. Multilingual models should be explored to cater to diverse linguistic contexts.
Like this project
Posted Jul 3, 2024
Advancing the comprehension of humor detection in text using NLP and BERT, achieving 98.75% accuracy, surpassing Naive Bayes (92%) and Random Forest (91.7%).
Likes
0
Views
72


