Unleashing Scalability: Guide to Kubernetes and KEDA

Ahmed Hesham

Kubernetes’ Horizontal Pod Autoscaler (HPA) excels in auto-scaling workloads, especially for common scenarios like typical web applications. Nevertheless, it isn't the best fit for batch workloads. In this discussion, we'll delve into Kubernetes-based Event-Driven Autoscaling (KEDA), purpose-built for batch workloads. We'll explore how we harness KEDA's capabilities to seamlessly and autonomously scale applications and queues, dynamically ranging from an initial state to hundreds of pods, and scaling down to zero if needed.
KEDA revolutionizes the scalability of applications, particularly those handling varying workloads. In a system consisting of three pivotal parts—a Web Application serving customers, a PubSub system housing multiple queues and consumers, and dedicated applications—we encountered the need to dynamically scale to meet demand. Let's explore how KEDA seamlessly handles this scaling complexity.
Scaling the Web Application
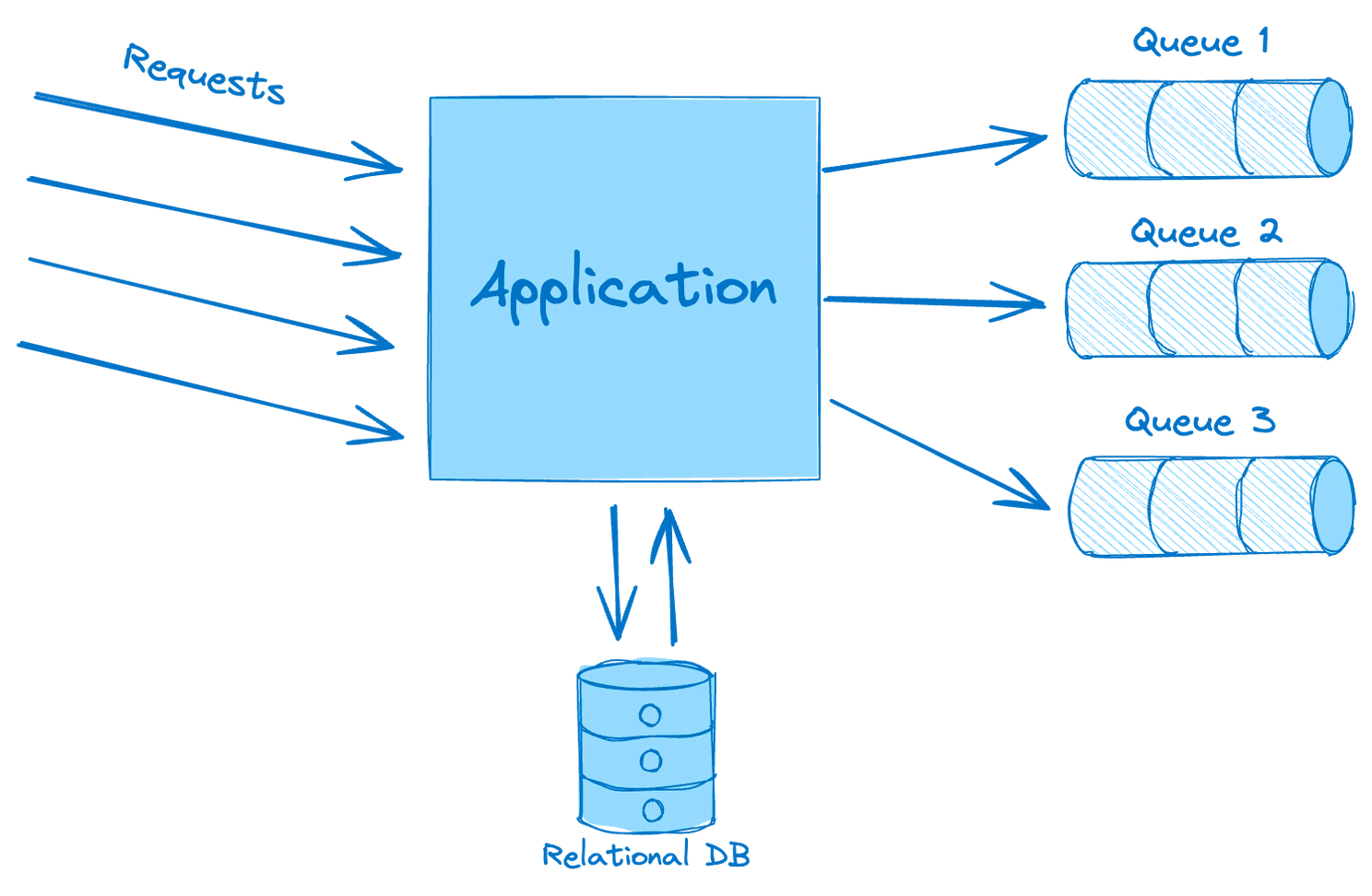
The influx of traffic to the Web Application necessitated scaling to ensure efficient handling of incoming requests. Leveraging KEDA's capabilities, we configured a ScaledObject within Kubernetes, enabling automatic scaling of the application. By referencing the application's deployment, we set scaling parameters to adjust the application's replica count dynamically, ranging from a minimum of 1 to a maximum of 100 replicas. Utilizing metrics like CPU and memory utilization, KEDA triggers the scaling process when specific thresholds, such as 50% CPU and 70% memory utilization, are reached.
Scaling Consumers for Queue Management
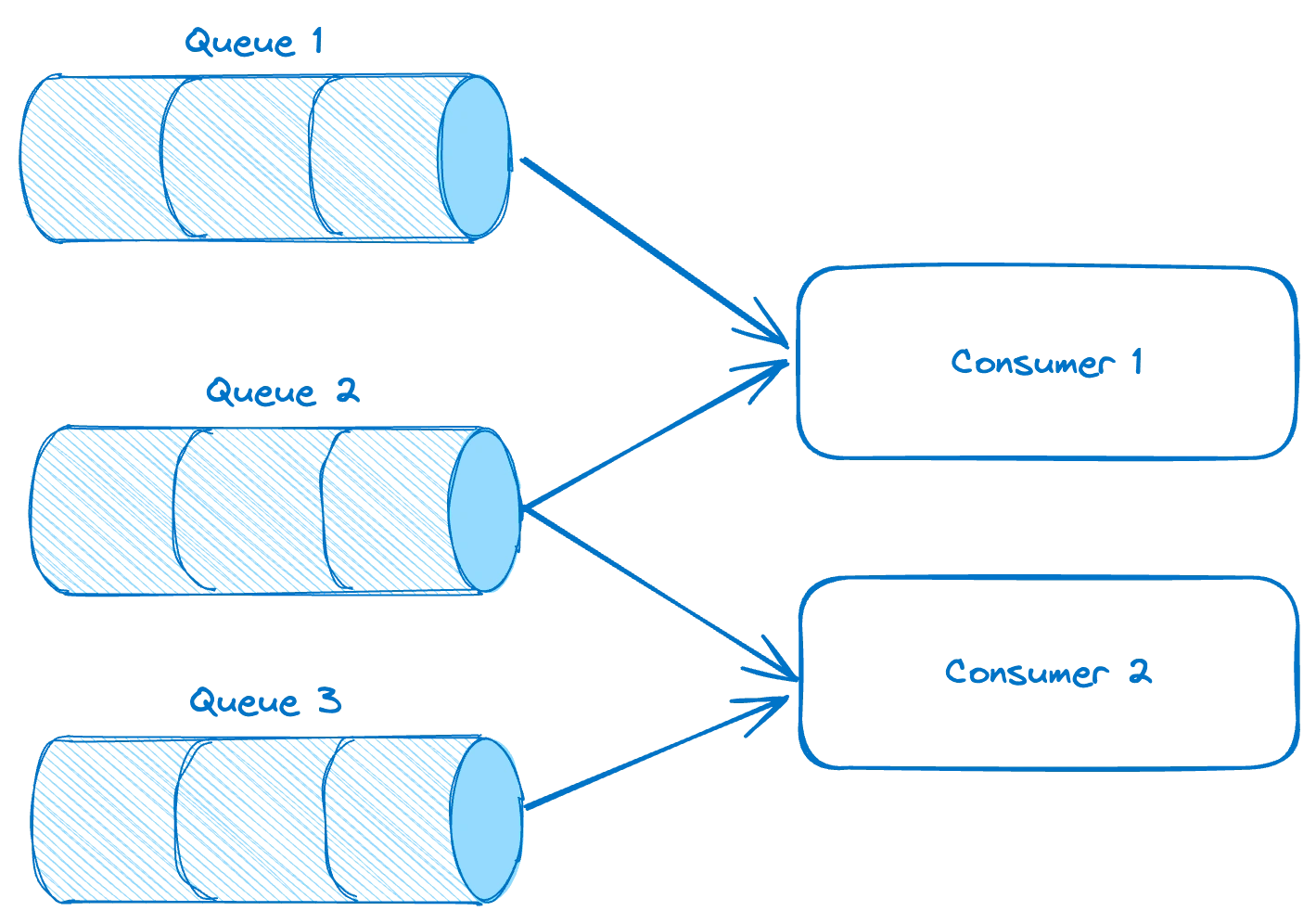
The PubSub system, composed of queues and consumers, demanded meticulous scaling to efficiently manage incoming messages. For each queue, we set up dedicated ScaledObjects to scale the consumers based on queue metrics, particularly the message backlog or publishing rates. By configuring triggers for RabbitMQ, KEDA initiates scaling events when specific thresholds in the queues are met, dynamically adjusting the consumer replicas. Moreover, the setup allows scaling down to zero if the queue backlog doesn't necessitate active consumers.
Conclusion
Kubernetes-based Event-Driven Autoscaling (KEDA) provides an intelligent and efficient solution for handling the dynamic scaling demands of applications and consumer systems within Kubernetes. By leveraging KEDA's capabilities, our system effortlessly and autonomously adjusts to varying workloads, ensuring optimal performance and resource utilization.
Like this project
Posted Dec 3, 2023
Kubernetes-based Event-Driven Autoscaling (KEDA) was implemented to dynamically scale a system comprising a Web Application and a PubSub system with queues.
Likes
0
Views
0