Online Speech recognition using RNN-Transducer

Zain Ali Nasir


Online Speech recognition using RNN-Transducer
Speech to text using RNN Transducer (Graves et al 2013 ) trained on 2000+ hours of audio speech data.
This work is a joint collaboration with @w86763777
Highlights
First repo demonstrating online decoding capability of RNN Transducer (RNN-T)
Port RNN-T model to ONNX and OpenVINO
A large scale training on diverse voice datasets for RNN-T with apex and data parallel
Using this model we can run online speech recognition on Youtube Live video with ( 4 ~ 10 seconds faster than Youtube's caption ) on an 2.3GHz dual-core Intel Core i5 processor.
Visualize alignment of audio and text, similar to paper in Graves et al 2013.
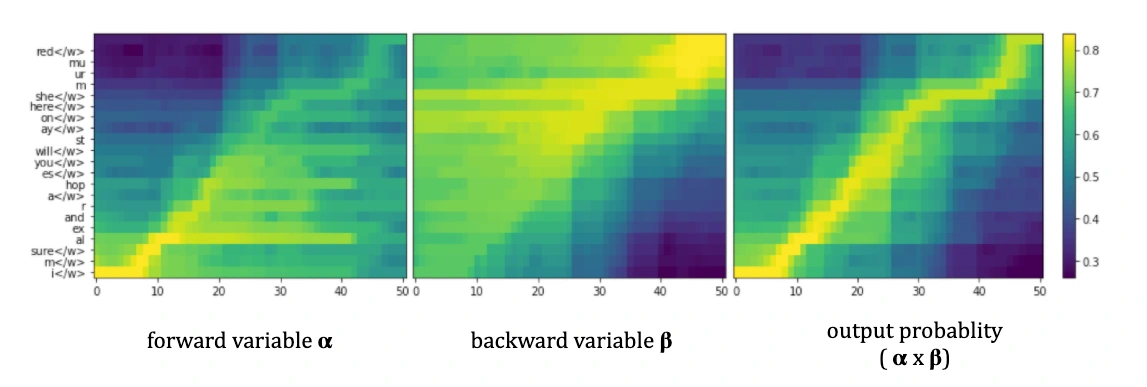
Speech recognition IRL ( in real life)
Pretrained weights are now available in releases v0.1
Follow the instruction for project setup
Update
Training Tips
Most of our insights share some similarity with this article: Towards an ImageNet Moment for Speech-to-Text. The difference is between our work and the mentioned article is that we mainly focus in online decoding, hence limit ourselves to RNN Transducer loss with uni-directional recurrent network. Hence, training requires more parameters and resource as we are limited by past audio feature.
Our current best model only achive a WER of 16.3% on Librispeech test-clean, which is still a long way to reach the common baseline of around 5%.
But we still learn some tricks and would like to share with you.
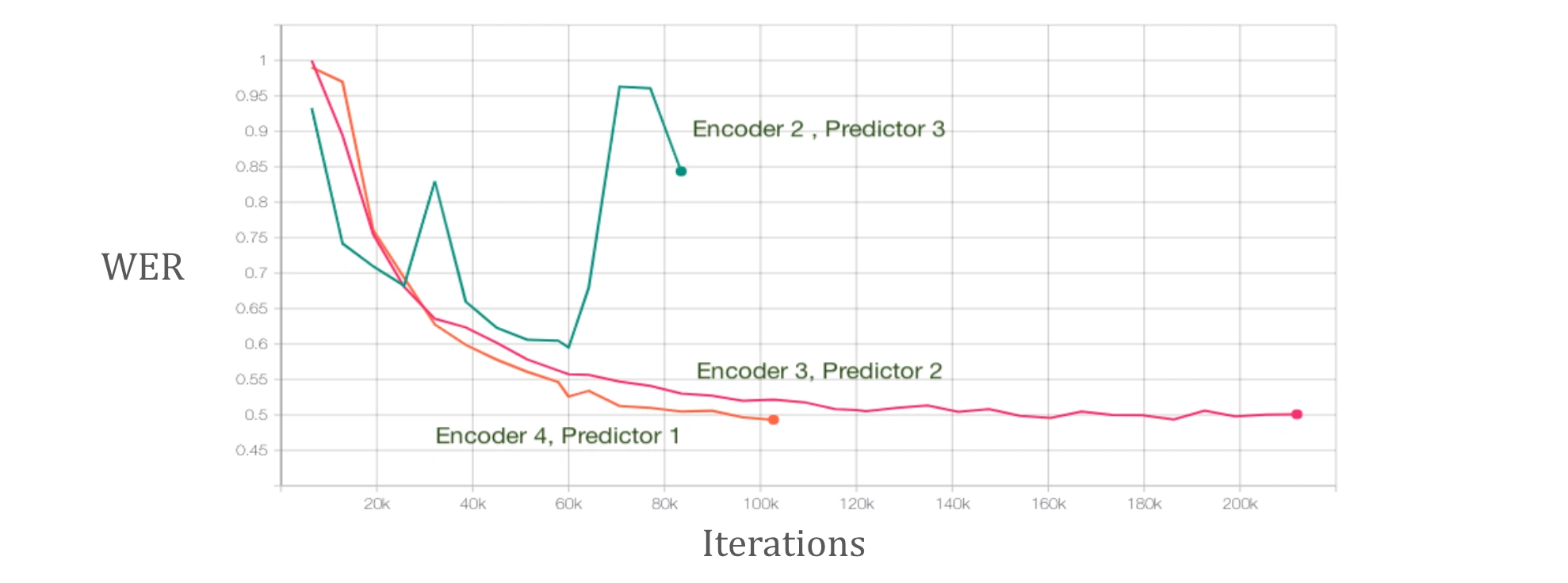
Balanced encoder and predictor is important
A good balance between audio encoding and language decoding is important since audio features is much more complicated than text ( in terms of diversity and feature space ). Hence a good rule of thumb is encoder should at least 4 times the capacity of the predictor network.
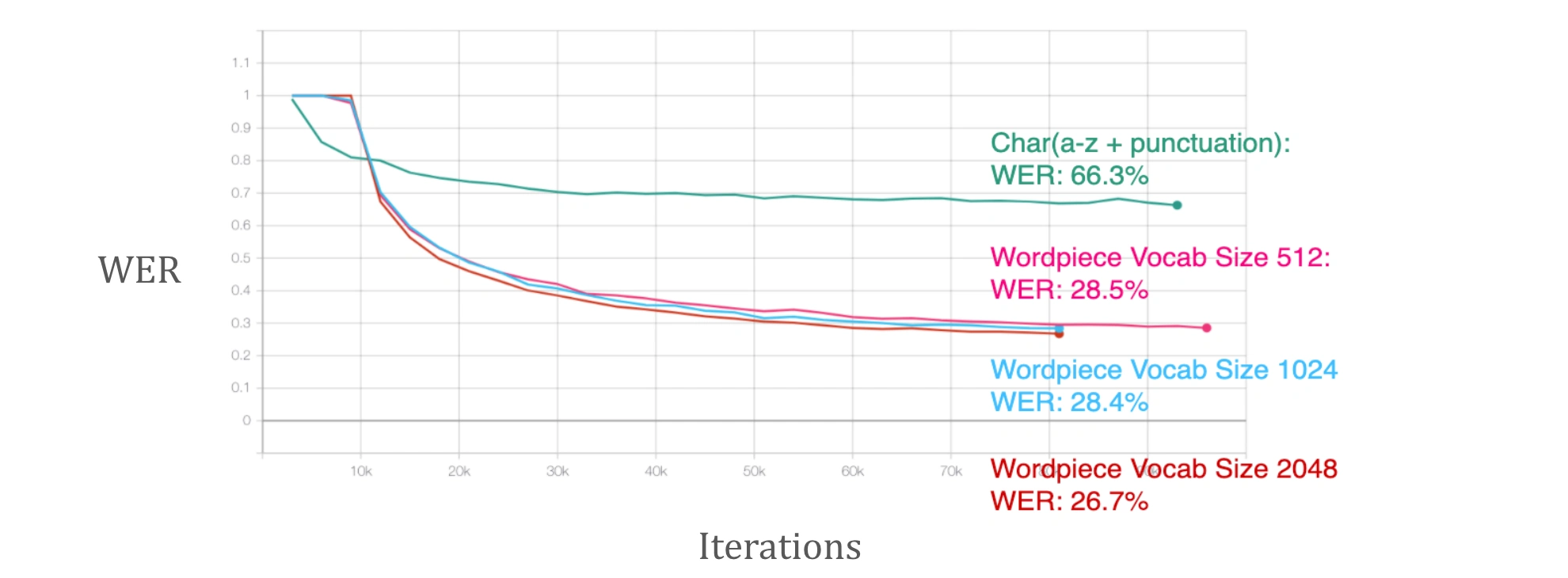
Vocabulary size improve convergence
Contradict to the article mentioned above, we found that larger vocabulary size ( we use BPE as wordpiece vocabulary ) always result in better performance. This is interesting, because CNN based CTC model usually suffers from performance drop when the vocabulary size increase til an extend.
Some other tips
Big batch size is better as mentioned in all previous RNN-T papers ( duh )
Train your model as large as possible ( 100M parameters is better )
Time reduction in first and middle layers help to reduce training memory usage but suffers certain performance hit that we haven't had the resource and time to investigate. However, think this can be make up by designing much more efficient model architecture (Maybe GRU for encoder model instead of LSTM ).
Layer norm helps model to handle sudden increase of voice pitch during online decoding, this allows us to skip CMVN preprocessing commonly found in online decoding. But this slows down the convergence speed.
Training RNN-T is slow, and any brave warrior who wish to challenge should be patience and expect to own a good compute resource ( ie workstation many GPUs, 1TB of SSD storage ).
We use Adam optimizer for fast convergence in order to meet the deadline for our final project. We experiement with SGD w momentum but find it extremely slow to converge.
Other results
Performance comparsion between Pytorch, ONNX, OpenVINO in inference stage
Evaluation environment
We found inference under OpenVINO is two times slower than Pytorch and ONNX runtime. The cause of degrade performance from OpenVINO is unknown, we didn't find any explaination other than lack of optimization for LSTM in OpenVINO.
FrameWork WER Avg Encoding Time Avg Decoding Time Avg Joint Time Avg Throughput Per Second Pytorch 11.08 % 12.289 ms 0.490 ms 0.482 ms 5.797 sec/sec ONNX 11.08 % 11.850 ms 0.462 ms 0.496 ms 5.989 sec/sec OpenVINO 11.08% 20.296 ms 0.897 ms 0.594 ms 3.543 sec/sec
ImageNet for speech recognition is still far away?
If you want to do online decoding. However, training a offline decoding CNN based CTC model is fast and low memory usage due to the use of CNN module. We were able to fit a 211 M CNN based model in one RTX 2080 with batch size of 8, but struggle to train a 50M RNN-T model on RTX 2080 with the same batch size.
Model # Param GPU Time Vocab size Batch size WER 8 layer Bi-Encoder 1280 hidden size [1] > 180M 32 x Google TPU 8G ? 7 Days 16k 512 3.6% CNN Based [2] 211M 8x NVIDIA Tesla V100 32 GB 4.16 Days 27 Character 512 (fp16) 3.7% 6 layer Encoder 1024 hidden size (ours) 50M 4 x NVIDIA RTX 2080-Ti 12G 3 Days 2k 128 (32 * 4) (fp16) 16.3%
Issues:
Currently dataparallel in pytorch 1.4.0 is broken, so you must use pytorch 1.5.0 and apex in parallel training make sure you have supported cudnn and cuda version
Install:
Install
torch and torchaudio with compatible versionInstall apex https://nvidia.github.io/apex/amp.html
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Install warprnnt-pytorch https://github.com/HawkAaron/warp-transducer
git clone https://github.com/HawkAaron/warp-transducer
cd warp-transducer
mkdir build
cd build
cmake -DCUDA_TOOLKIT_ROOT_DIR=$CUDA_HOME ..
make
cd ../pytorch_binding
export CUDA_HOME="/usr/local/cuda"
export CFLAGS="-I$CUDA_HOME/include $CFLAGS"
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
python setup.py install
Install other dependencies
pip install -r requirements.txt
Training:
Checkout configuration examples under flagfiles and rnnt/args.py for more details about parameters.
For dataparallel training or single GPU training:
For distributed training:
If the learning rate and batch size is right, you should have a convergence curve as below after 24 hours of training.
Datasets:
Common Voice : 178.621 hrs
Download english dataset from https://voice.mozilla.org/en/datasets
execute preprocess_common_voice.py to convert audio to 16k, PCM 16bits wav files ( this takes around 20 hours )
Youtube Caption : 118 hrs
Librispeech release 1 : 1000 hrs
Download all the tar.gz files from here and unzip files under a directory LibriSpeech, and point your flagfiles to each directory files
check rnnt/args.py for the argument names
TEDLIUM: 118.05 hrs
Either download release 1 or 3 ( version 1 is smaller )
Data path
OpenVINO cheat sheet
Export pytorch model to ONNX format
python export_onnx.py \
--flagfile ./logs/E6D2-smallbatch/flagfile.txt \
--step 15000 \
--step_n_frame 10
Install OpenVINO inference engine Python API
sudo -E apt update
sudo -E apt -y install python3-pip python3-venv libgfortran3
pip install -r /opt/intel/openvino/deployment_tools/model_optimizer/requirements.txt
Model Optimizer
TODO
Parallelize model training
Use BPE instead of character based tokenizer, should reduce more memory
Write checkpointing and tensorboardX logger
Modify wraprnnt-pytorch to compatible with apex mixed precision
Reference
Like this project
Posted Dec 25, 2023
Working online speech recognition based on RNN Transducer. Convert real-time audio into text.
Likes
0
Views
19



ProPainter_pro
Drwaish/DebugAndDocstringPrompt