Telco Customer Churn Prediction
Tio Syaifuddin
Loading this content connects you to YouTube.
YouTube privacy information1. Context
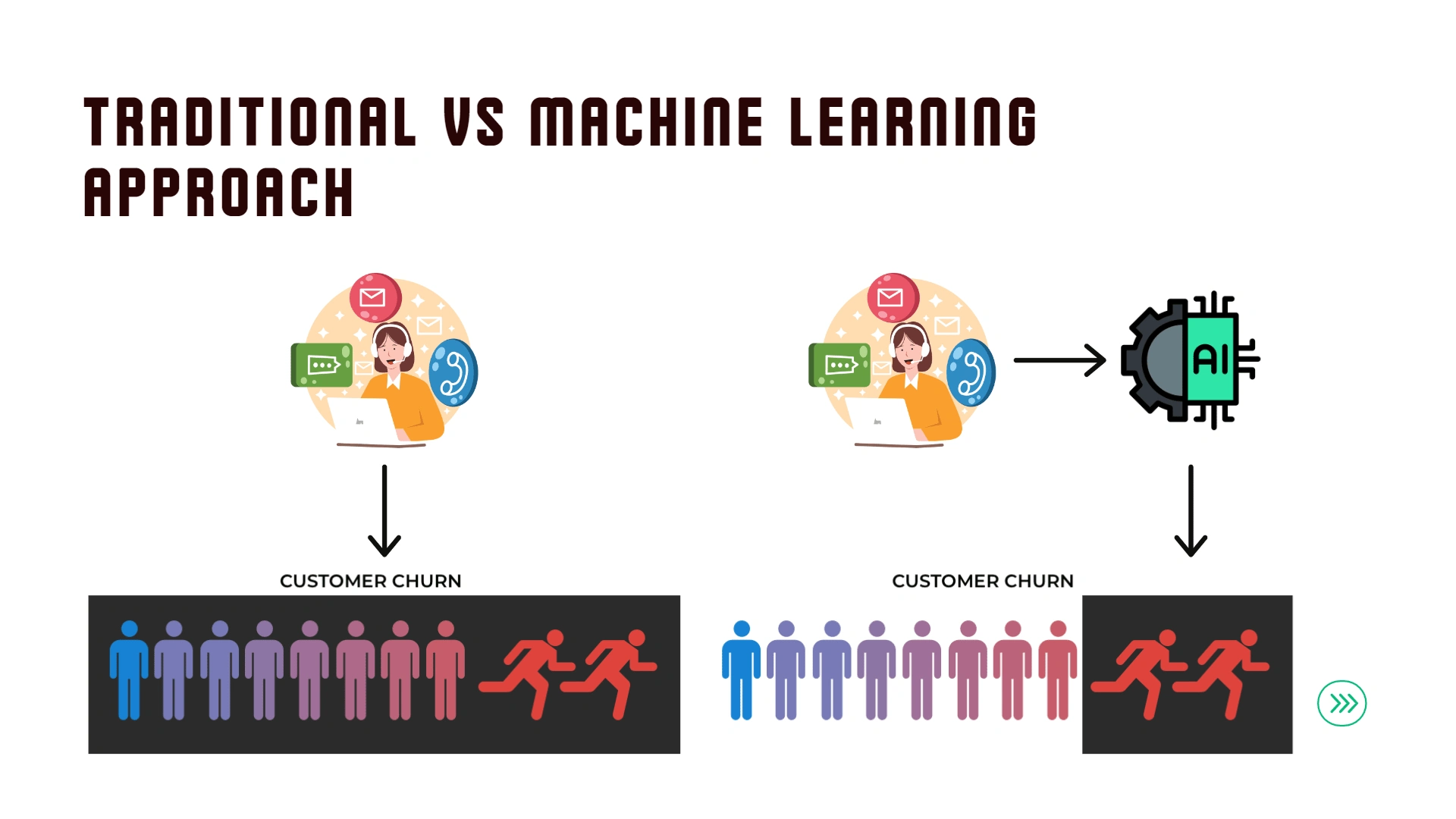
Customer churn is a customers stop using a service, either they don't need the service anymore or they change to another service provider. Acquiring a new customer is far more expensive than retaining the existing ones. Even an article says that "Acquiring a new customer can cost a business 5x more than retaining an existing one". Therefore, customer churn is a critical factor for sustaining long-term profitability.
2. Problem Statement
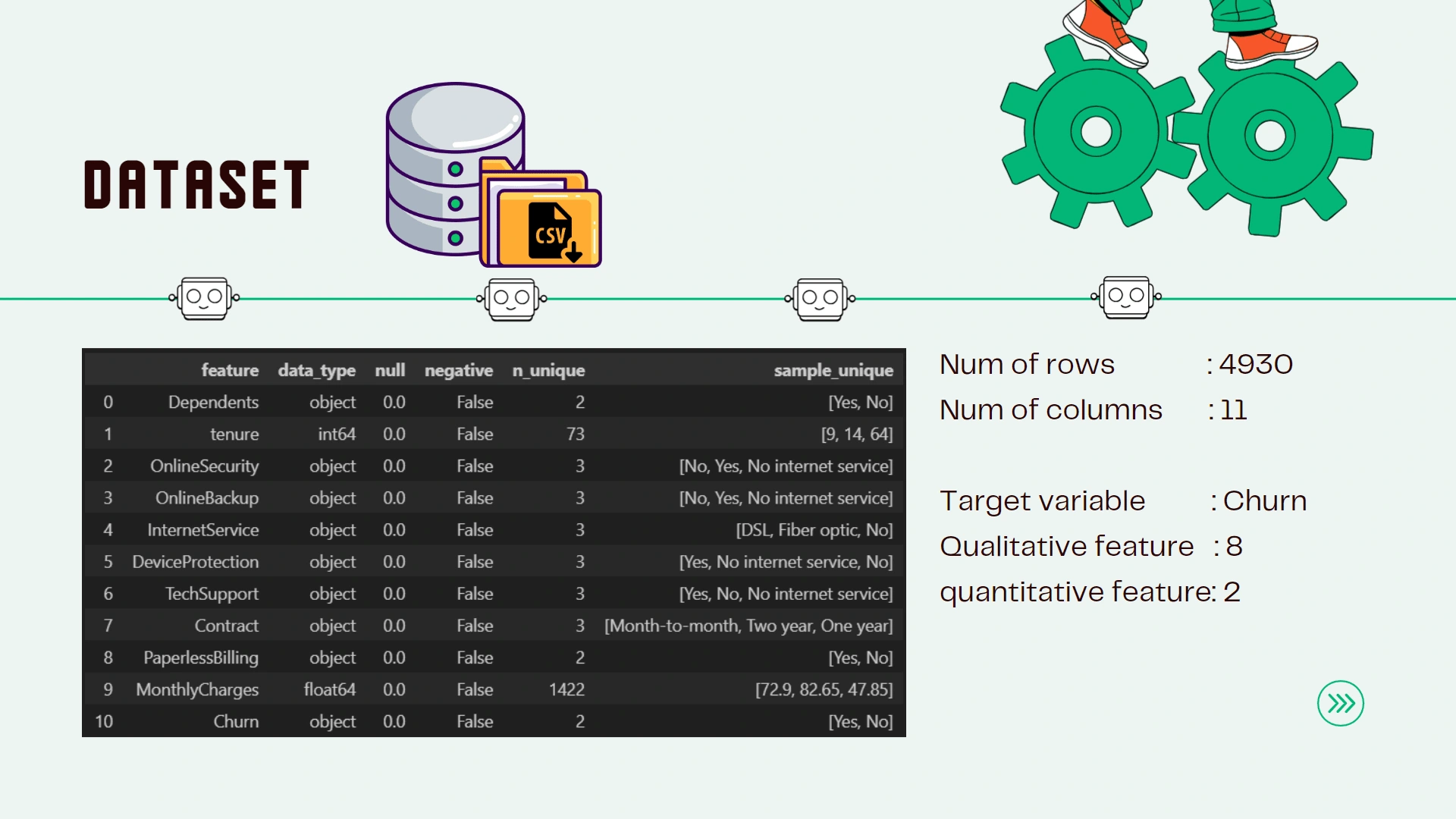
In this project we will use historical data of certain telco company consisting of almost 5000 rows and 11 columns with column that state if the customer is churning or not. This project aim to identify current customers who's likely to churn by looking at historical data. A predictive solution leveraging data analytics and machine learning can help us to identify these at-risk customers and optimize promotional strategies.
3. Goal
The purpose of this project are to:
Analyze factors that influence a customer to churn
Make a machine learning model to predict whether a customer will churn or not
Deploy the corresponding model to cloud
4. Analytical Approach
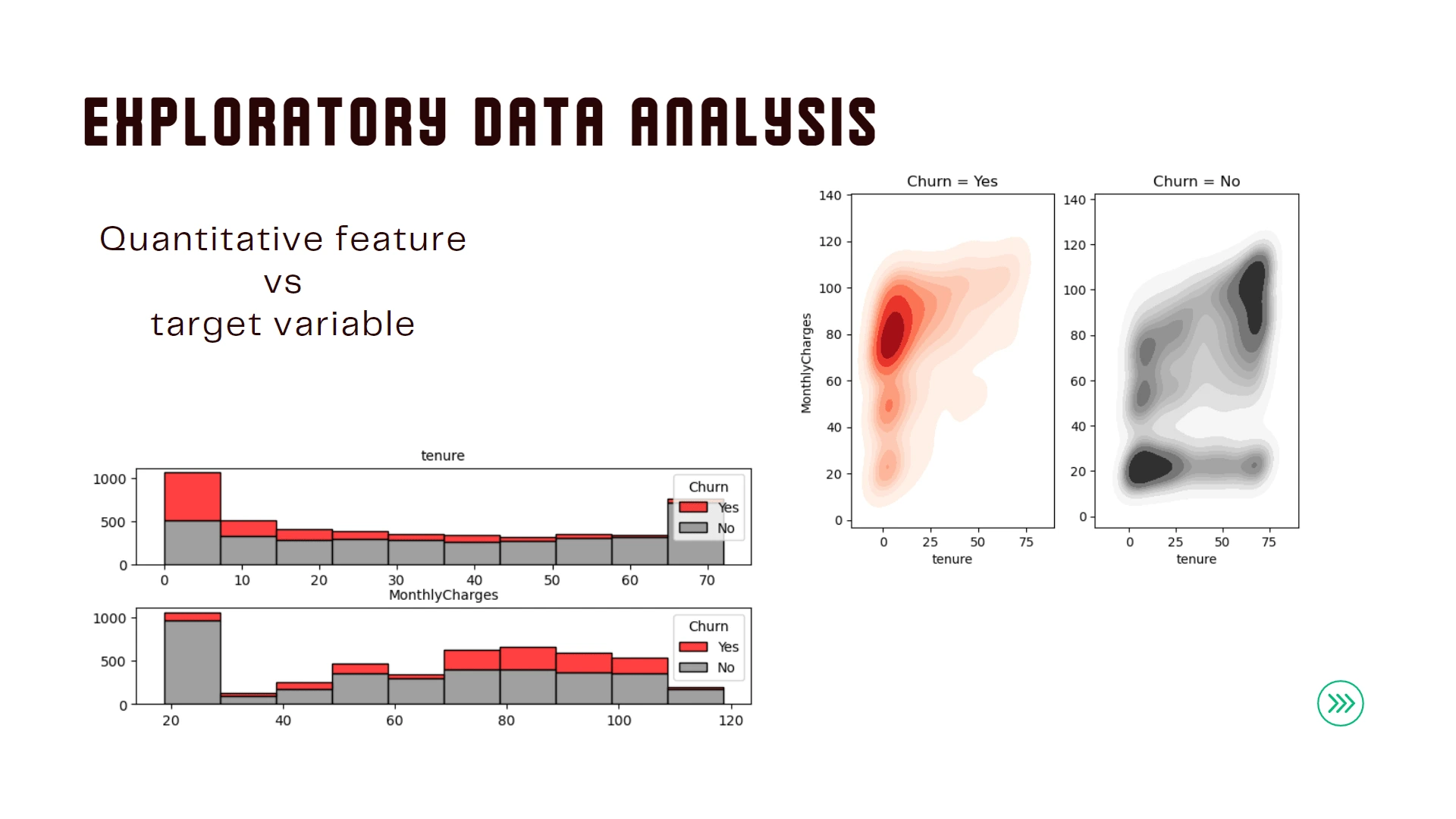
We will take a look at the data by doing some exploratory data analysis (EDA) in hope to uncover the truth that still yet to be uncovered. By looking at several information provided from the data that might potentially have a correlation with churning customers. In the end, we will make several action recommendation based on insight being spotted while doing the data analysis process.
5. Metric Evaluation
Here we define the positive class as a churn customers with this detail.
False Positive (FP): Predict a customer will churn, while it is not
False Negative (FN): Predict a customer will not churn, while it is churn
Giving false prediction will result in these costs.
FP cost: Waste of promotional budget
FN cost: Lost of customers
This projects aims to spot as many potential churn as possible. We knew that acquiring a new customer is far more expensive than retaining the existing ones. Recall will be the metric that suit our interest. But, because we want to maximize the budget that are going to be spend to offer promotions to customers. We are going to take a little bit of concern to the model precision.
To have a good measure of this, we will use the F2-score that give specific weight (2:1) to recall and precision. To better understand this metric, take a look at the equation below (Betha=2)

Loading this content connects you to GitHub Gist.
GitHub Gist privacy informationLike this project
Posted Jul 29, 2024
The purpose of this project are to: analyze factors that influence a customer to churn, make a ML model to predict customer churn, deploy model to the cloud.