Remote Code Execution Engine
Aayush Pagare
Remote Code Execution Engine
Chapter 1: Choosing Node.js and problems with that.
We all know that Node.js servers are excellent at handling multiple concurrent requests in a real-time environment due to their event-driven architecture and non-blocking I/O model. So, in a scenario where we want to provide a seamless real-time experience to all users when many users are submitting their code execution requests simultaneously, Node.js is suitable.
Problems:
CPU bound requests.
Node.js has a non-blocking I/O model, which means all I/O requests like reading from or writing to files, network operations, user input/output, and database queries are not blocking main thread.
In our scenario, request would contain some source code which is going to be executed on server, and that’s not an I/O request; that’s a CPU-bound request. CPU-bound tasks are blocking in nature even for Node.js because Node.js has a single thread of execution.
If we directly use Node.js here, we are going to make our engine as slow as a tortoise. Imagine a scenario where a user sends a code execution request that takes 15 seconds to execute; until then, server would be blocked, and other users wouldn’t be able to send any requests.
Because our code execution engine is going to get a lot of CPU-bound tasks, we want to take advantage of a multi-core CPU and parallel processing. For that, we need to figure out a way so that we can do multi-threading in Node.js.
Multi-threading in Node.js
NodeJS is a single threaded in nature but there could be a case where we need a multi threads especially for running synchronous, CPU-intensive tasks in isolation.
There are several ways to achieve multi-threading in node.
worker threads
child processes
cluster
We are going to use child processes here for following reasons.
Child processes allow you to run external programs or scripts as separate processes.
Unlike worker threads, child processes provide a separate instance of the entire Node.js runtime. Each child process has its own memory space and communicates with the main process through IPC (Inter-Process Communication). This level of isolation is beneficial for tasks that may have resource conflicts or dependencies that need to be separated.
If a child process crashes for any reason, it will not bring down your main process along with it. This ensures that your application remains stable and resilient even in face of failures.
The
exec function is a good choice if you need to use shell syntax and if size of data expected from the command is small. It buffers the command’s generated output and passes whole output value to a callback function.Chapter 2: Break down services and decouple them using RabbitMQ, Building an asynchronous system.
We can separate out two components here:
Server: Responsible for handling incoming requests, and sending responses
Worker: For execution code
Example of tightly coupled system synchronous system.
Let’s consider a scenario where we have a code execution request. The server then sends it to a worker and waits for worker to finish code execution. When worker finishes the execution, server sends result to client.
This is what we call a synchronous and tightly coupled system. Synchronous: Everything follows an order (get request -> send to worker -> get response back from worker -> send response to client -> next request) while the worker is executing code, the server is idle. Tightly coupled: The server is heavily dependent on the worker to fulfill its responsibility of sending back responses (it will only send a response to the client until it receives it from the worker). — — — — — — — — — — Less Robust: If the worker fails, the server will also fail. This means that if one part of our system, such as the code execution engine, fails, then system cannot serve clients’ requests. It cannot cache or store them so that when code execution engine is up, it can execute those requests. In this scenario, it will face complete downtime. — — — — — — — — — — — — Less scalable: Synchronous systems cannot handle too much load at a time.
How can we make an asynchronous system?
We will be using a message queue here to make an asynchronous system.
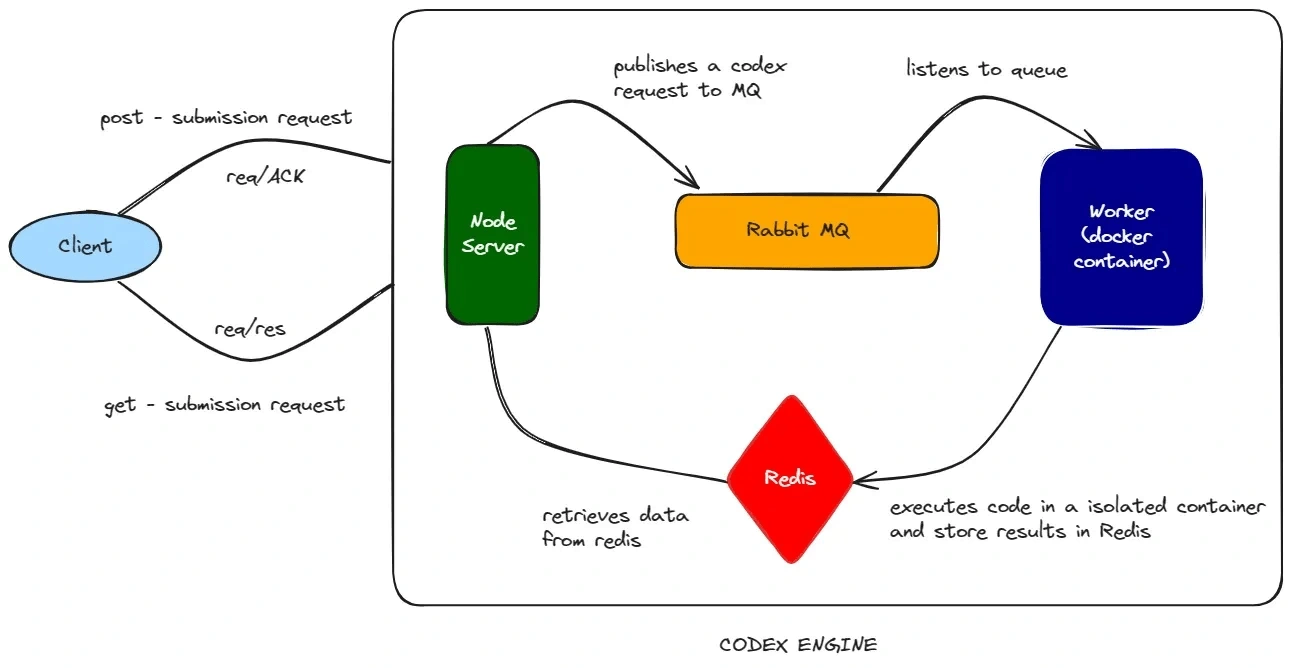
As soon as the server receives a request, it can publish a message along with some data to the queue and immediately and send a response to client (such as an acknowledgment or ID), without waiting for the server to actually execute the code. Then, the server can continue serving other requests.
The client might poll the server to inquire whether the code execution has actually completed or not.
This is an example of an asynchronous system, where one service does not block its own functioning while waiting for responses from other services.
How can we decouple?
We can decouple both the components using message queues.
Server will only publish the message, and the worker will listen to queue. If there’s any message for executing code, it will execute code and store results somewhere.
Server is not dependent on the worker for sending responses or receiving requests, and worker is not dependent on server for executing code.
This is example of a decoupled system, where each component has a dedicated set of responsibilities and are not dependent on other components to complete their responsibilities.
Some Advantages
A robust system, where if one component breaks other would be still completely functional.
We can scale each component individually, if we need better concurrency and scale the server, we can use node cluster for server and if we need to scale worker, we can change config of Wokers (docker container)
Chapter 3: Choosing a service to store submission results.
When our worker picks any code execution request from queue, it will execute and store the result somewhere.
Storage requirement
We just need to store data temporarily, for less than 1 minute. We don’t need to store data permanently.
We need data access really quick.
REDIS: Redis stores data in RAM.
Redis stores data primarily in RAM, allowing for extremely quick read and write operations. Accessing data from RAM is significantly faster than accessing it from disk, which is common in traditional databases.
Redis suits our requirements well.
Chapter 4: Securing system from malicious code attacks.
What are some possible problems?
Attacks like fork bombs which can fork multiple processes.
Creating files, deleting files on system.
Running a CPU and memory intensive job.
Running a program which takes infinite time to execute.
I have addressed few issues here.
For attacks like fork bombs which forks multiple processes we can tackle that by limiting number of processes inside container.
For limiting memory usage and CPU usage for any program we can set memory hard limit for processes inside container.
Docker can help us run code in an isolated environment, we can limit number of processes, CPU usage, memory limit. So that if something happens entire server is not affected. Also, it is really easy to spin up a container.
Features:
Can handle multiple concurrent requests will respond back immediately with acknowledgement.
Limited number of processes inside CPU, programs creating more processes taking RAM more than 200MB, taking more than 1 CPU’S would immediately stop.
Added support for only JavaScript and Python.
Improvements:
Add cluster in node.js, to spin multiple instances of server.
Add security to stop a program which takes more than 30s to execute.
Add security that a malicious program cannot delete, create or alter system files.
Add support for multiple languages.
Add support of judge to take input and execute test cases.
Check blog on medium
Check Github-Repo
Like this project
Posted Dec 18, 2024
I have attempted to build a simple remote code execution engine using Node.js and Docker. Let’s explore its high-level design.
Likes
0
Views
13