Data-De-Duplication-using-AWS-Glue
Mario Sorour
Data-De-Duplication-using-AWS-Glue
Problem description:
The following example of the dataset1 and dataset 2 shows how it’s structured. The dataset1 includes 2,616 records, structured as shown in the following table.

The dataset 2 includes 64,263 records. It has a similar structure, but the data is messier. For instance, it has missing entries, incorrect values (for example, an address in the title field), and includes unexpected characters.

Using the provided labels file, shown below, we need to find the deduplication data using AWS services
Solution steps:
The 1st step to do it to merge the 2 datasets together, and to avoid compatibility issues, replace all “/” characters in the “id” field with “-” in both the datasets and label file and adding new column called source to represent from which the dataset. The next step to do is to upload the combined dataset to S3 to start working on it.

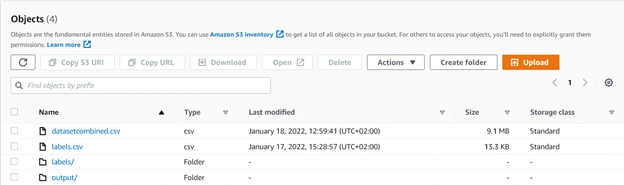
In this exercise Glue Data Catalog (crawler) will be used to create catalog the data so we can other services on it. You have to create or use a new Role to enable Glue access to S3 the best thing about Glue is that you don’t need to move the data from S3, the Glue will work on the data on S3

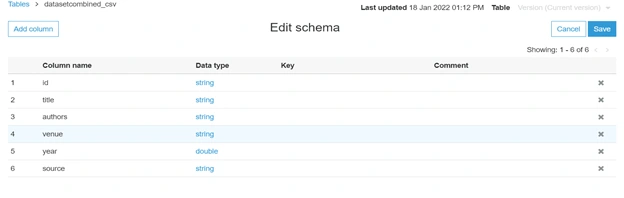
After the crawler finishes running, it will create a table with the following schema
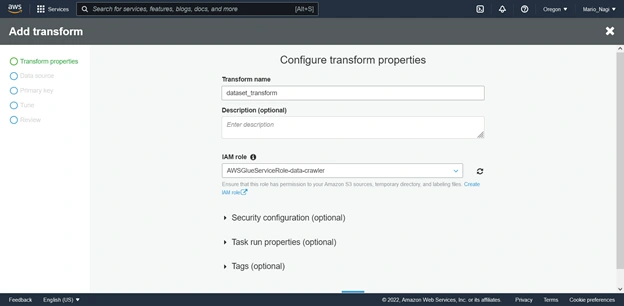
Next we will use create a new FindMatches ML transform for your data. With the following configurations
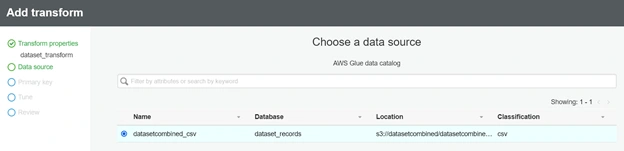
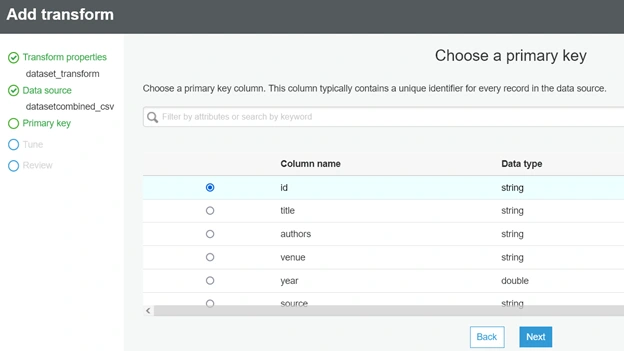
Then choosing the data from S3, after that we have to pick a primary key, select id as the primary key. Since the primary key should be a unique identifier
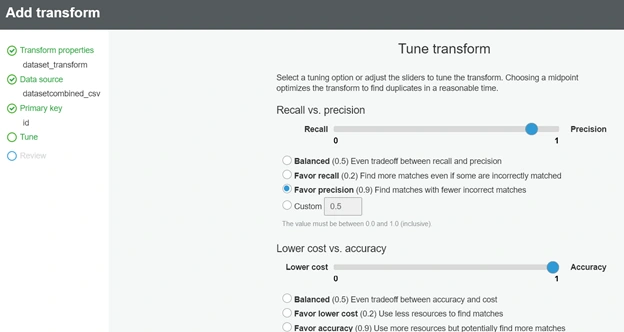
On the tune transform page, you have to adjust the balance between Recall and Precision, and between Lower cost and Accuracy. Based on your choice, the cost and the accuracy will be determined, in this example We will favor accuracy over cost, so we will move the 1st slider towards Precision (0.9) and 2nd towards Accuracy (1.0)
Now we need to teach the model with train data, if we tried to upload the normal label file we have on hand. It will be rejected as it need to adhere to the following format: “ labeling_set_id, label, id, title, ... “ you can create it using the generated option in transformML or creating it manually we will divide the labels into sets which will be added in the labeling set id column, and the label column will be used to mark the duplicated books as seen in the below screenshot

At least 100 records are needed to get accurate data, the more records will be added the better results will be achieved
After uploading and teaching the model, accuracy estimation will be calculated

After that we to create and run a record-matching job, in this job Glue will generate a spark script which will use the transform job to identify the duplicated data
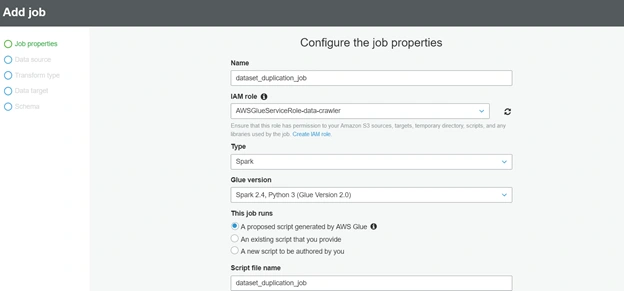
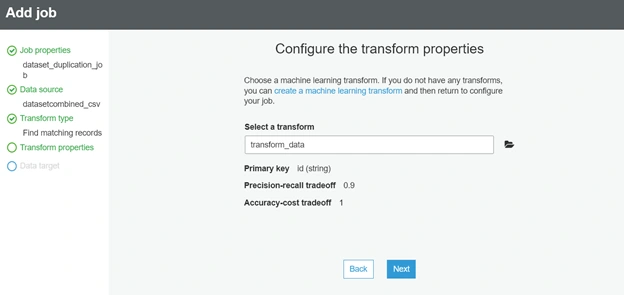
In Security configuration, script libraries, and job parameters (optional), we have to pick “G.2X (Recommended for jobs with ML transforms)” to be able to process the transform ML created earlier
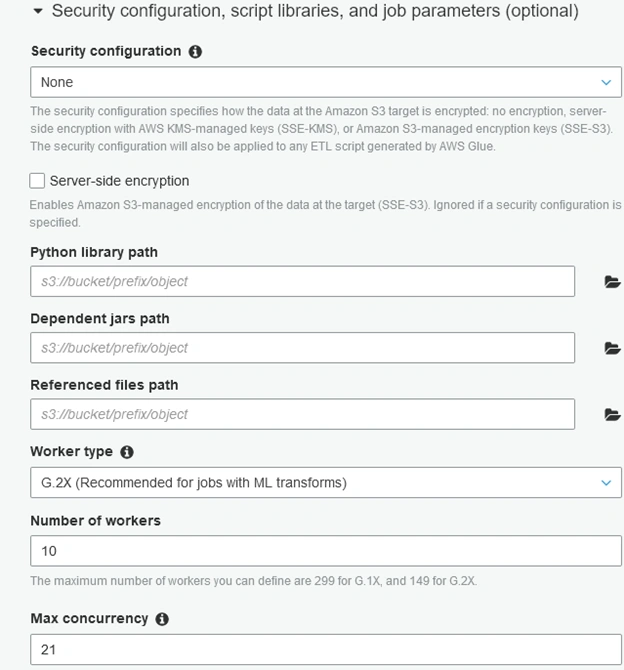
On the next page, select the table within which to find matching records.
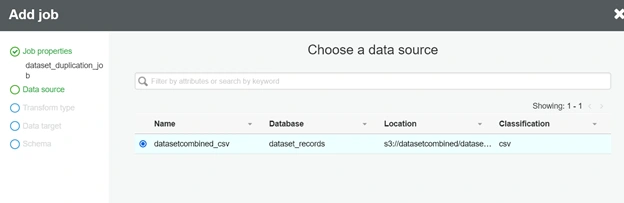
On the next page, select Find matching records as the transform type. To review records identified as duplicate, do not select Remove duplicate records. Choose Next.
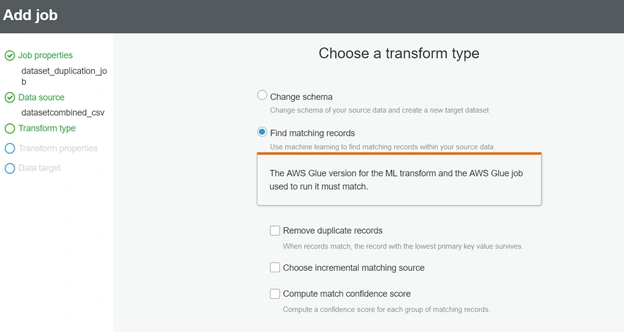
Next, select the transform that you created and choose Next.
On the next page, select Create tables in your data target. For Data store, select Amazon S3. For Format, choose CSV. For Target path, choose a path for the job’s output. Choose Save job and edit script.
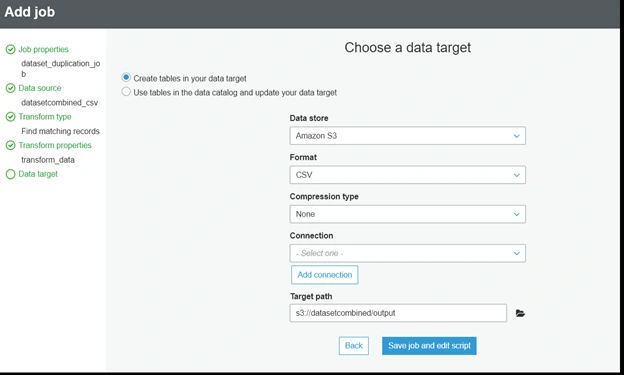
After finishing the configuration, glue will create automatic spark script to do the required find matches
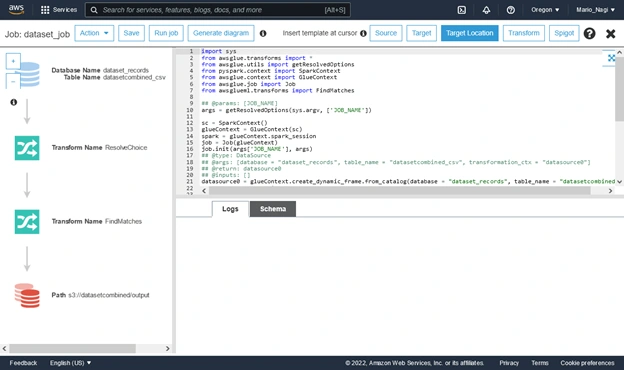
The script will take around 10 mins to fully run and will create output files in the specified output location in S3 picked in the configuration. The output will look something like this (“multipart CSV files”)
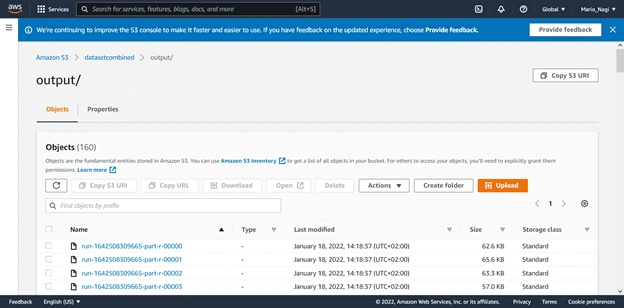
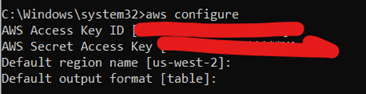
In the final step, we will download these files via AWS CLI, to be able to use AWS CLI you must install on your system first. -install it from here https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html - to check if the cli is installed correctly on your system, write “aws” in your command prompt, you should receive a similar screen
To interact with your AWS account, you have to use the following command “aws configure” and enter your access key id and secret -if you don’t have access key, you can create one from AWS IAM- To configure your session, you have to enter your access key ID, access key secret and your region -here I am using us-west-2- and the output format like the below image
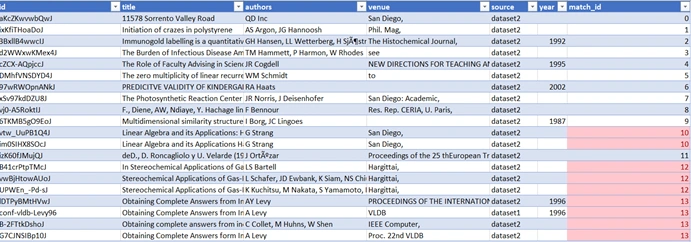
After that, you must ensure that your account has access to S3 through IAM policy otherwise you will receive an error while trying to interact with S3. You can either use “aws sync” command or “aws cp – recursive” to download all the file in your output folder, then merge them to get one final CSV file as seen below a new column has been added named match_id which contains all the matched books
Used services:
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue provides all the capabilities needed for data integration so that you can start analyzing your data and putting it to use in minutes instead of months. The beauty about Glue lies in its serverless operation, as we saw in the above example, Glue did the catalogue, transform Ml, transform job almost without any human interaction which could help users who has little or no experience with machine learning or spark
Like this project
Posted Mar 6, 2024
Contribute to MarioNagi/Data-De-Duplication-using-AWS-Glue development by creating an account on GitHub.
Likes
0
Views
132
Tags