Freelancers using Ollama in Mumbai
Freelancers using Ollama in Mumbai
Sign Up
Post a job
Sign Up
Log In
Filters
2
Projects
People
Anurag Nagare
Mumbai, India
I’m an AI & Machine Learning engineer with expertise in deve
New to Contra
Follow
Message
I’m an AI & Machine Learning engineer with expertise in deve
0
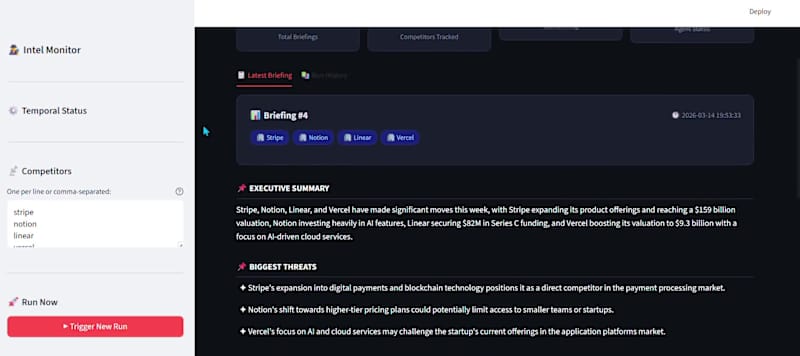
It all started on a Sunday at the AWS User Group Mumbai meetup. I wasn't expecting to walk away with a new obsession, but then the speaker introduced me to Temporal and everything changed. Temporal is a durable execution engine that solves one of the hardest problems in agentic AI what happens when your LLM workflow crashes mid-run? Normally you lose everything So I went home and built this: an agent that monitors your competitors around the clock tracking pricing changes, product launches, hiring signals, and strategic moves. Every 24 hours it uses Mistral (running fully on-device via Ollama) to analyze the data and synthesize a structured executive briefing delivered straight to your inbox. Sometimes the best projects start with a Sunday conversation. https://github.com/AnuragNagare/Agentic-AI-.git
0
7
0
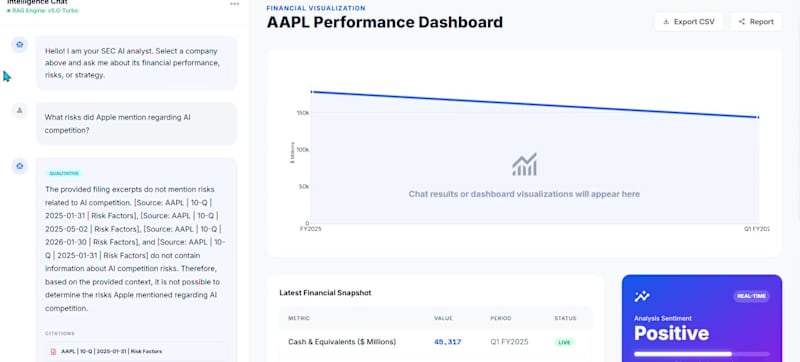
HybridAlpha (Hybrid RAG) : One tool digs into actual SEC filings, not just static documents. From EDGAR, it grabs 10, Ks and 10, Qs fresh each time. Sections like MD&A or Risk Factors get split out by name during parsing. Storage happens two ways at once: words go to ChromaDB, numbers land in SQLite. When a question arrives, the router decides, tone, driven, number, heavy, or both. Depending on that choice, the query moves to one place, sometimes both. Context flows forward only after sorting is done. Answers come from Llama 3.3 70B via Groq, always tagged with sources. Each output ties back to where the data lived. Start by asking, What risks did Apple highlight regarding AI rivals? Out comes exact quotes pulled straight from official documents.
0
19
1
A Neural Network Visualization Tool that demystifies AI! I built an interactive web application using Flask and PyTorch that doesn't just recognize handwritten digits it shows you exactly how the AI "thinks." When you draw a digit (0-9) on the canvas, the app processes it through a Convolutional Neural Network and generates a real-time visualization of every layer: from edge detection in the first convolutional layer, through pattern recognition, pooling, and feature extraction, all the way to the final classification. The tech stack includes Python, Flask, PyTorch, and vanilla JavaScript for the frontend. What makes this unique is the educational aspect each layer's activations are visualized using matplotlib, showing the 32 filters in Conv Layer 1, the 64 filters in Conv Layer 2, and the 128-neuron fully connected layer.
1
30
0
SLM vs LLM for startups SLMs (1B–3B parameters) are becoming a kind of cheat code for startups: they can be run with a single GPU or even a powerful CPU, data can remain on your own infrastructure, and you still get almost LLM quality for very targeted tasks like support bots, internal search, or document workflows. In numerous benchmarks, contemporary SLMs are only a few F1 points behind bigger models while being up to 10–300x cheaper per request to serve. Huge language models (between 50 billion and 70 billion+ parameters) are still the preferred option when we talk about complex multi-step reasoning, long contexts, and highly open-ended generation. Nevertheless, the vast majority of startup scenarios do not need such models for every single request.
0
20
Ollama
(1)
Follow
Message
Explore people